



在深度学习的前沿研究范畴中,数据蒸馏与知识蒸馏作为两项具有关键影响力的技术,从不同技术维度为深度学习模型的优化与性能提升提供了重要支撑。数据蒸馏聚焦于数据处理流程,旨在将原始数据中繁杂且冗余的信息进行有效过滤,提炼出具有高度代表性的精炼数据子集;知识蒸馏则侧重于模型间的知识迁移,通过将大型复杂模型(教师模型)所蕴含的知识转移至小型轻量化模型(学生模型),实现模型性能的优化以及计算资源的高效利用,二者协同为提升深度学习模型的整体效能开辟了新的技术路径。
数据蒸馏
从原始数据到精炼子集的转换过程
深度学习模型本质上是一个设计精巧的数据处理架构,由一系列数据处理单元(即层,layer)有序组合而成,宛如一套层层嵌套的精密筛选机制。在模型运行过程中,每一层都承担着对输入数据进行特征提取与信息过滤的任务,将经过处理的数据传递至下一层,以实现更深入的数据特征挖掘与表达,这一过程即为数据蒸馏的核心操作流程。
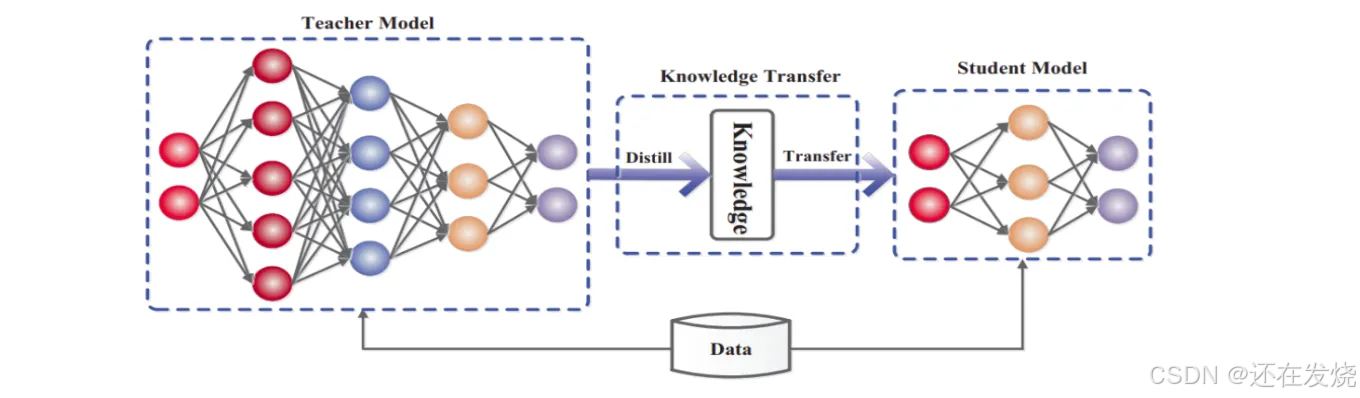
数据蒸馏的核心技术步骤
-
原始数据集:数据来源与初始状态:在实际应用场景中,深度学习所依赖的原始数据集通常体量庞大,且包含大量冗余信息与噪声干扰。以图像识别领域为例,原始图像数据集中可能存在大量相似图像样本,或者图像存在模糊、噪点等质量问题,这些因素会显著影响模型对图像特征的准确提取与识别性能;在语音识别任务中,原始音频数据往往混杂着环境噪声、人声冗余片段等干扰信息,对后续语音内容的准确识别造成阻碍。原始数据集犹如未经加工的矿石原料,虽蕴含丰富信息,但需经过一系列精细处理才能发挥其价值。
-
数据预处理:数据质量提升与标准化:为提高数据可用性与模型训练效果,需对原始数据进行清洗、去噪等预处理操作。在图像数据处理中,常采用图像滤波算法去除图像中的噪点,增强图像清晰度;对于音频数据,通过降噪技术消除背景杂音,突出人声或目标音频信号。同时,还需进行数据格式转换、归一化等操作,使数据在格式与数值范围上达到统一标准,便于后续数据处理与模型训练。
-
特征提取:数据本质特征的挖掘与表达:从经过预处理的数据中提取关键特征,这些特征能够精准反映数据的内在本质属性。在图像分析领域,可提取图像的边缘、纹理、颜色等底层视觉特征;在视频分析场景中,除了图像特征外,还需提取视频的关键帧、动作序列等动态特征。例如,人脸识别系统通过提取人脸的关键特征点,如眼睛、鼻子、嘴巴的位置与形状特征,实现对人脸的精准识别;语音识别系统则依赖于提取音频的频谱特征、基音频率等声学特征,以区分不同语音内容。
-
数据降维:数据表达的精简与优化:原始数据通常具有较高维度,包含许多相关性较强的冗余维度,这不仅增加了计算复杂度,还可能对模型训练效率与准确性产生负面影响。借助数据降维技术,如主成分分析(PCA)、线性判别分析(LDA)等,可去除数据中冗余的相关性维度,保留最具代表性的核心信息,从而获得更为精简高效的数据表达形式。例如,在处理高分辨率图像时,通过数据降维可将图像从高维像素空间转换至低维特征空间,在大幅减少数据量的同时,有效保留图像的主要特征信息。
-
精炼数据集:数据处理的最终成果与应用价值:经过上述一系列数据处理步骤后所得到的精炼数据集,具备更高的数据质量与代表性。该数据集去除了原始数据中的冗余信息与噪声干扰,保留了最具价值的核心特征,能够为后续深度学习模型的训练提供更为高效的数据支持,显著提升模型的训练速度与识别准确率,如同经过精细提纯的高纯度原料,具有更高的应用价值与效能。
在深度学习模型架构中,数据蒸馏过程通过各层对数据的逐步过滤与特征提取得以实现。每一层依据其设计功能对输入数据进行特定的变换与处理,推动数据逐步向最终目标特征表示逼近。以卷积神经网络(CNN)为例,卷积层通过卷积核扫描图像提取局部特征,池化层则对卷积层输出的特征图进行下采样操作,进一步减少数据量并保留关键特征,经过多层的级联处理,最终生成能够准确表征图像内容的特征向量。
综上所述,数据蒸馏是一种集数据处理、特征提取与优化为一体的关键技术,其通过数据预处理、特征提取、数据降维等一系列标准化技术流程,从包含大量冗余与噪声的原始数据集中提炼出高质量、低冗余且具有高度代表性的精炼数据集,为深度学习模型的高效训练奠定坚实的数据基础。
知识蒸馏
模型间知识迁移与性能优化机制
知识蒸馏作为模型压缩与知识迁移领域的重要技术手段,旨在将大型、高复杂度的教师模型所蕴含的丰富知识与泛化能力,有效迁移至小型、轻量化的学生模型中,实现模型性能的优化提升以及计算资源的高效利用,以满足不同应用场景对模型性能与资源消耗的多样化需求。
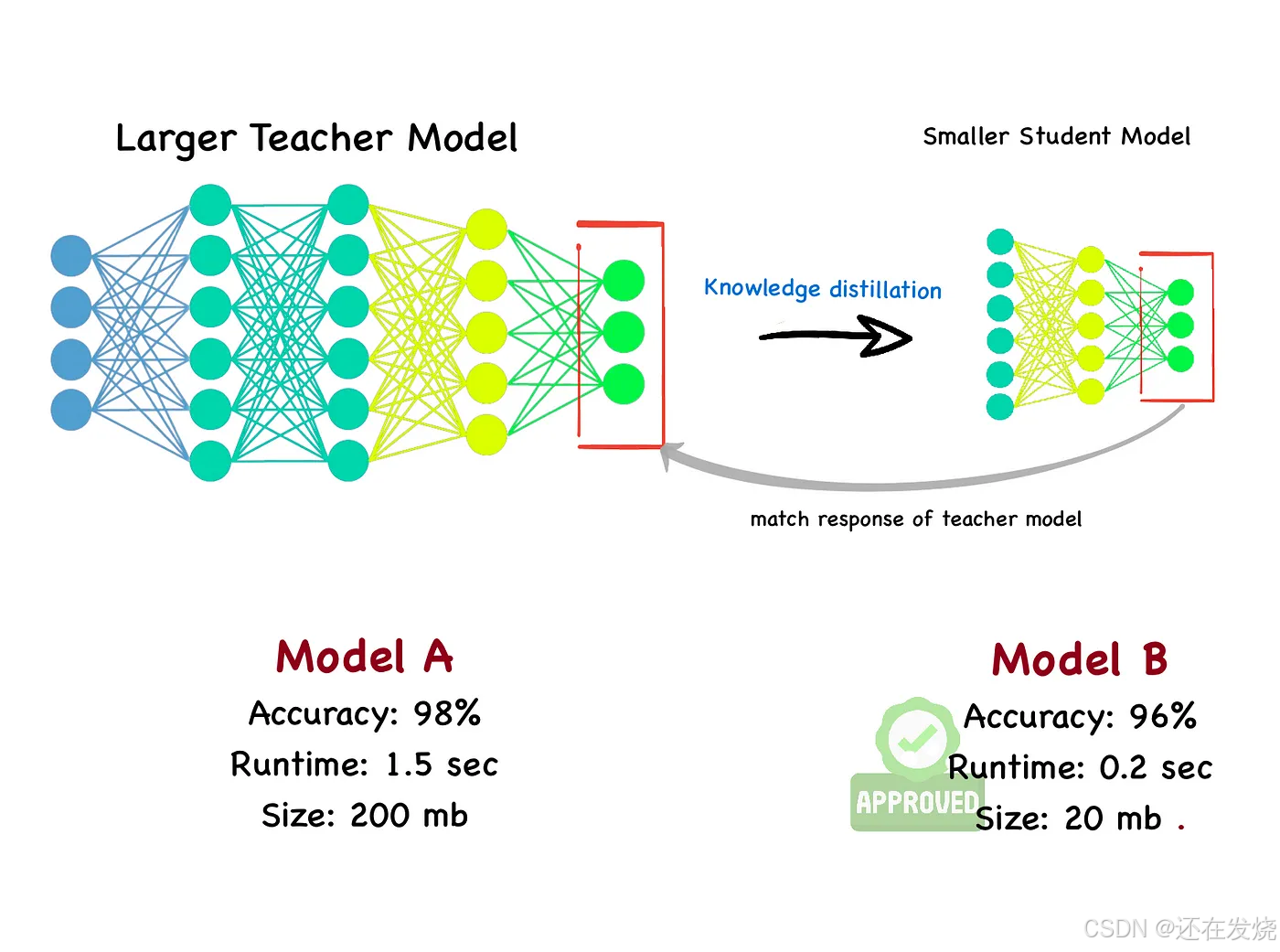
知识蒸馏的关键技术要素与实现流程
-
教师模型:知识的载体与来源:教师模型通常是经过大规模数据训练的高精度模型,其结构复杂、参数量庞大,在特定任务上展现出卓越的性能表现。以图像分类任务为例,教师模型可能采用深度卷积神经网络架构,如 ResNet 系列模型,经过大规模图像数据集的充分训练后,能够准确识别各类图像,并对图像中的细微特征与语义信息具有深入的理解与表达能力。教师模型不仅在最终分类结果上具有高准确性,其内部各中间层所提取的特征也蕴含着丰富的多层次知识,这些知识反映了模型对数据从底层特征到高层语义的逐级理解与处理过程。
-
知识提取:教师模型知识的挖掘与解析:从教师模型的输出中提取具有价值的知识信息,主要包括概率分布与中间层特征。概率分布体现了教师模型对各类别的置信度估计,例如在对一幅动物图像进行分类时,教师模型输出的概率分布可能表示该图像属于猫类的概率为 80%,属于狗类的概率为 15%,属于其他类别的概率为 5%,这种概率分布包含了比简单分类标签更丰富的信息,反映了教师模型对不同类别之间相似性与差异性的判断;中间层特征则是教师模型在数据处理过程中,各中间层所提取到的特征表示,这些特征能够捕捉到数据的高级语义信息,如在视频分析中,中间层特征可表征视频中的场景、动作等语义内容
-
学生模型:知识的接收者与学习者:学生模型是一种轻量化、结构相对简单、参数量较少的小型模型,其在计算资源消耗与推理速度方面具有显著优势,但在模型性能上可能不及教师模型,尤其在处理复杂数据时,分类准确性与泛化能力相对较弱。例如在相同的图像分类任务中,学生模型可能由于结构简单,无法像教师模型那样全面、准确地捕捉图像的关键特征,导致分类错误率较高。
-
蒸馏训练:知识迁移与学生模型优化过程:利用从教师模型提取的知识作为监督信号,指导学生模型的训练过程。在训练过程中,将教师模型输出的概率分布作为软目标,引导学生模型学习教师模型的决策过程,而非仅仅依赖于真实类别标签(硬目标);同时,通过最小化学生模型与教师模型在中间层特征上的差异,使学生模型能够学习到教师模型对数据的高级语义理解能力,从而提升自身性能。具体实现中,常采用计算学生模型与教师模型输出概率分布之间的 KL 散度(Kullback-Leibler Divergence),并将其作为损失函数的一部分,指导学生模型的参数更新,使其逐步逼近教师模型的知识水平。
-
精炼学生模型:知识迁移后的性能提升与应用价值:经过蒸馏训练后的学生模型,能够有效学习到教师模型的泛化能力与知识精华,在保持低计算成本优势的前提下,实现性能的显著提升,达到或接近教师模型的性能水平。此时的学生模型如同经过名师指导的学习者,在知识储备与应用能力上实现了质的飞跃,能够在对计算资源与响应速度要求较高的实际应用场景中发挥重要作用,如移动设备上的实时图像识别、语音助手的实时语音识别等。
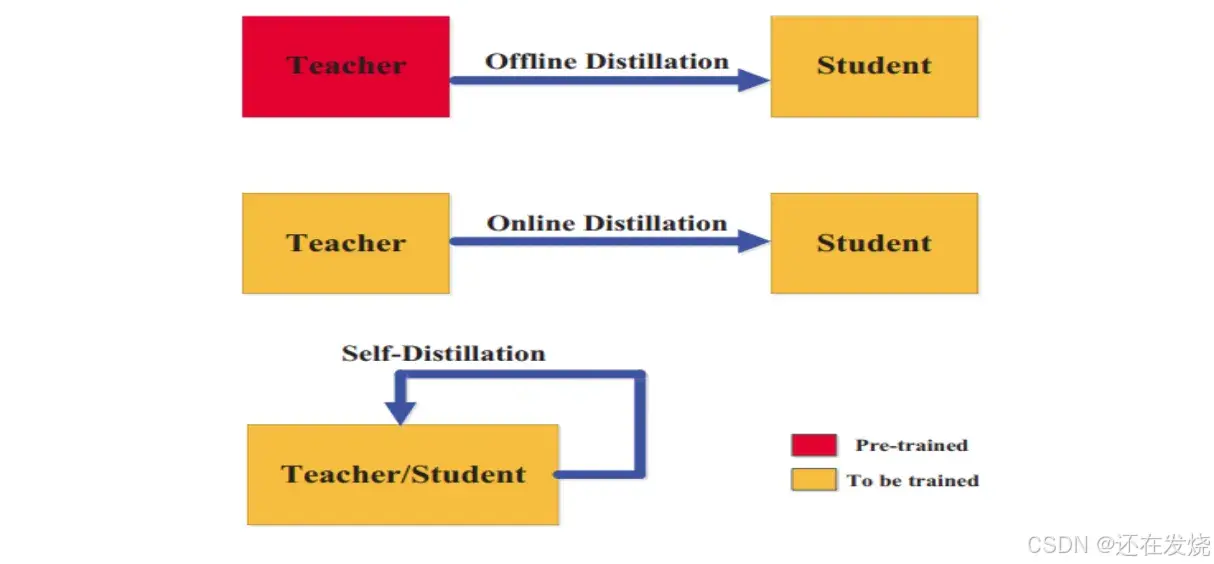
知识蒸馏技术的核心在于实现模型间的知识传递,通过将教师模型的输出(如概率分布、中间层特征等)作为软目标,引导学生模型的训练过程。与传统仅基于真实标签进行训练的方法不同,知识蒸馏使学生模型能够学习到教师模型的决策逻辑与泛化能力,打破了模型性能与计算资源之间的部分制约关系,为在资源受限环境中部署高性能模型提供了可行的技术解决方案。

















 6482
6482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









