



一、链表(基于指针 / 引用实现)
(一)链表的定义与分类
定义:物理存储非连续、非顺序的线性表,通过节点(数据域 + 指针域)链接实现逻辑顺序,节点可动态生成。
核心分类:根据指针数量和结构,分为单向链表、双向链表、循环链表。
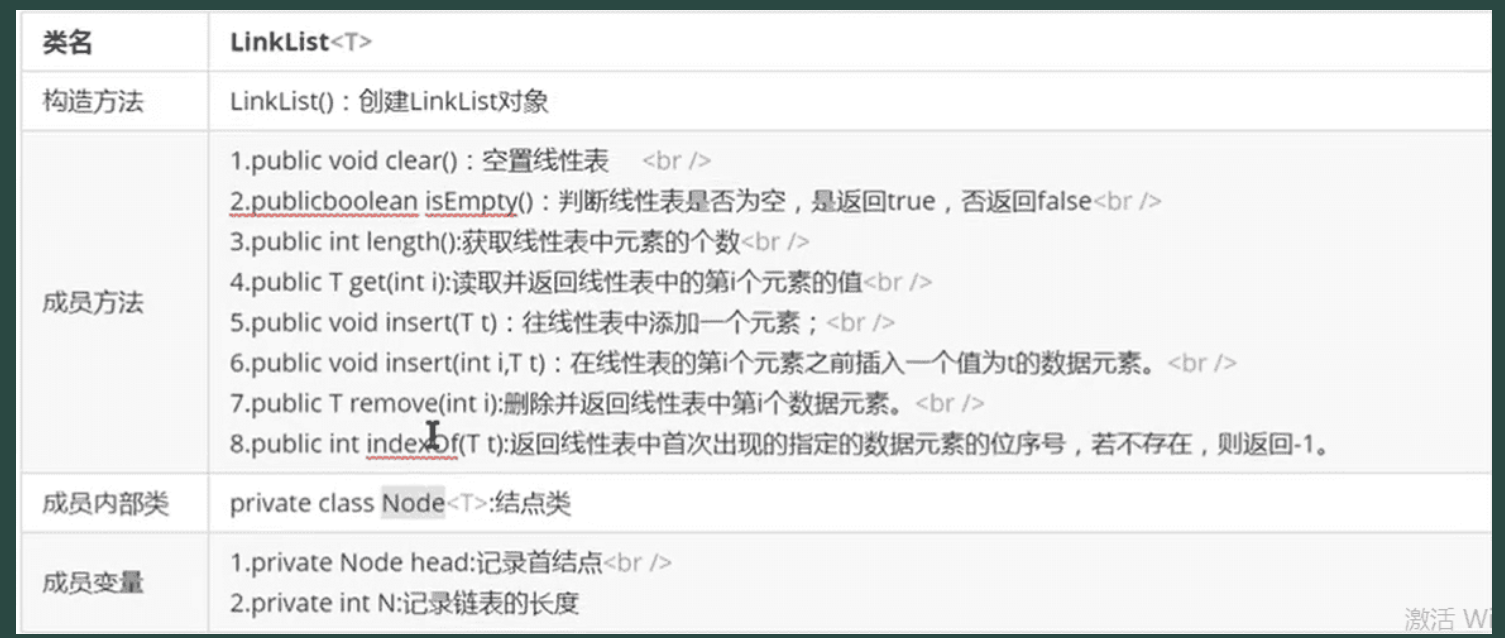
1. 单向链表
节点结构:每个节点包含 1 个数据域(存储元素)和 1 个指针域(指向后继节点)。
特殊节点:头指针(指向头节点),头节点数据域通常不存储元素,仅用于定位链表起点;尾节点指针域指向null。
优缺点:实现简单、节省内存(1 个指针);仅支持单向遍历,插入 / 删除需找到前驱节点(O (n))。
2. 双向链表
节点结构:每个节点包含 1 个数据域和 2 个指针域(前驱指针指向前面节点,后继指针指向后面节点)。
特殊节点:头节点前驱指针为null,尾节点后继指针为null。
优缺点:支持双向遍历,插入 / 删除无需额外查找前驱节点(O (1));每个节点需 2 个指针,内存占用更高。
3. 循环链表
结构特点:尾节点指针域不指向null,而是指向头节点(单向循环)或头节点的前驱(双向循环),形成闭环。
优缺点:便于循环遍历(如约瑟夫问题);需避免无限循环(遍历需判断终止条件)。
单向链表API设计
(二)双向链表核心差异
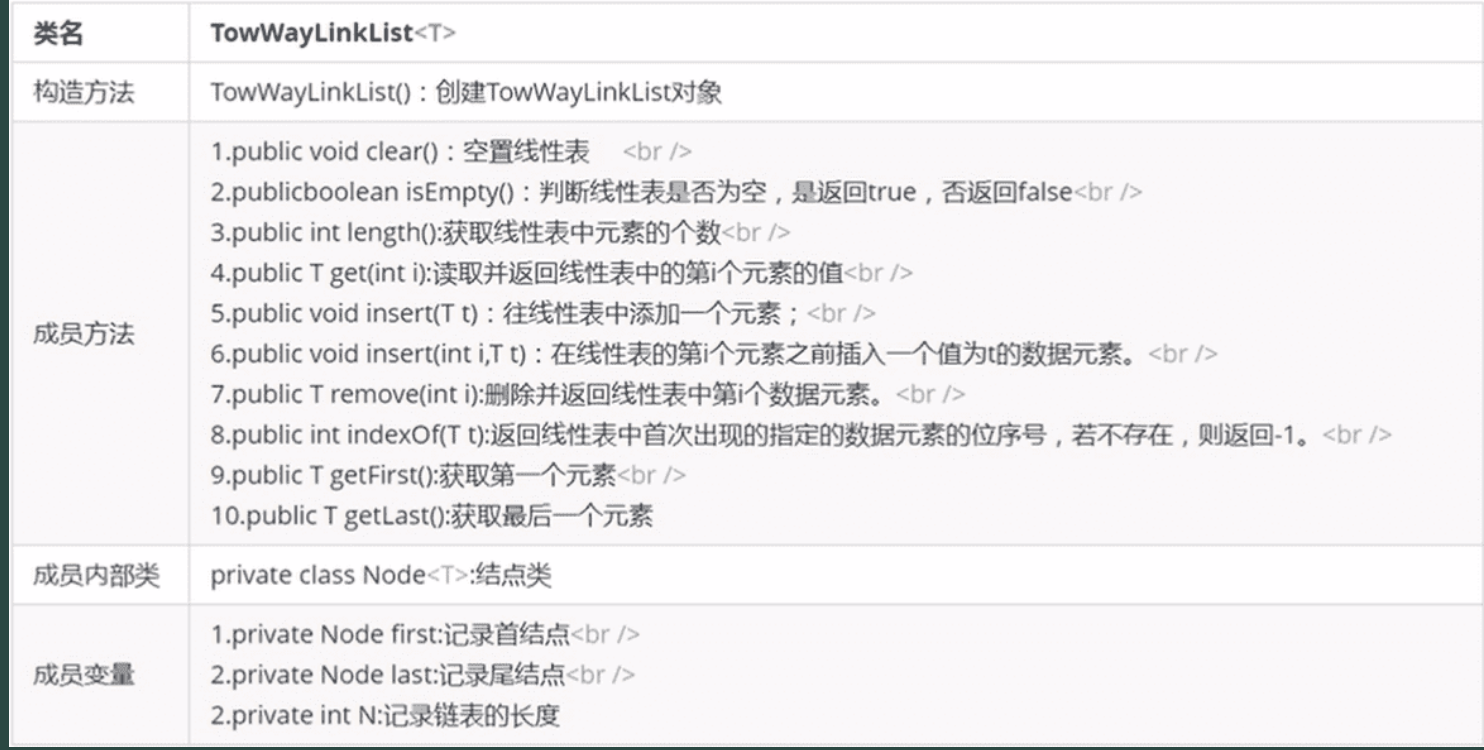
1.节点结构:新增Node pre(前驱指针),API 新增getFirst()(获取首元素)、getLast()(获取尾元素)。
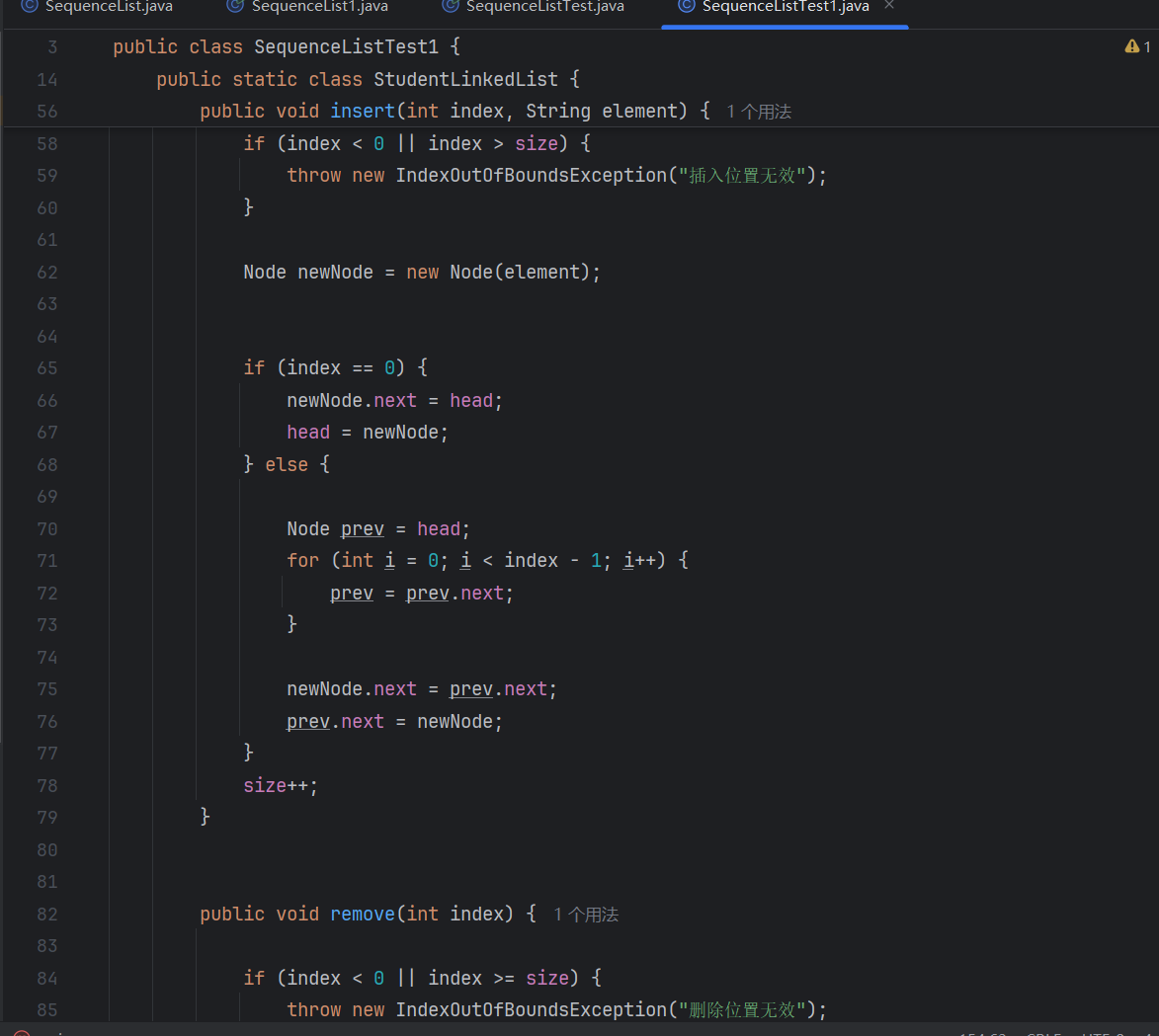
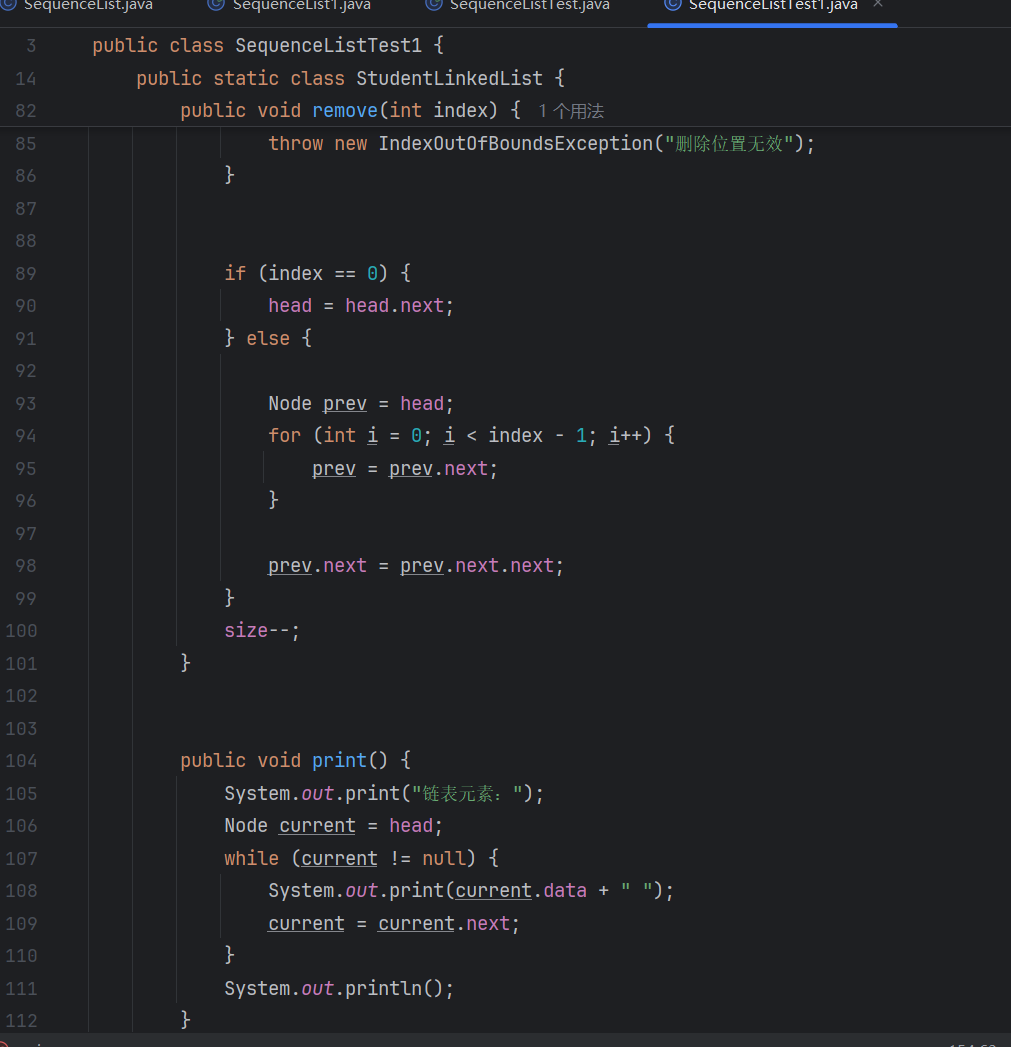
2.插入 / 删除优化:无需遍历查找前驱节点(通过pre指针直接访问),操作效率更高。
插入:新节点的pre指向前驱,next指向后继;前驱的next和后继的pre指向新节点。
删除:前驱的next指向后继,后继的pre指向前驱,无需额外查找。
双向链表API设计

















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









