import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# import gym
from ple.games.flappybird import FlappyBird
from ple import PLE
from pygame.constants import K_w
import time
import random
import collections
import numpy as np
import os
# Hyper Parameters
BATCH_SIZE = 32
LR = 0.0001 # learning rate
EPSILON = 0.9 # greedy policy
GAMMA = 0.999 # reward discount
TARGET_REPLACE_ITER = 100 # target update frequency
MEMORY_CAPACITY = 20000
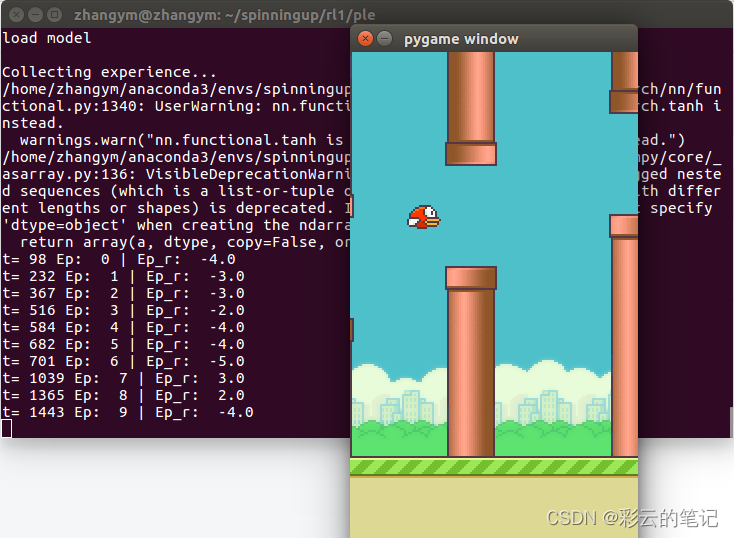
game = FlappyBird()
env = PLE(game, fps=30, display_screen=True)
N_ACTIONS =2# env.action_space.n
N_STATES = 8#env.observation_space.shape[0]
class Net(nn.Module):
def __init__(self, ):
super(Net, self).__init__()
self.fc1 = nn.Linear(N_STATES, 128)
self.fc1.weight.data.normal_(0, 0.





 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5521
5521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









