







小白学习笔记,有误请指正
目录
一、决策树的基本流程
1.决策树的相关基本概念
- 决策树:亦称判定树。决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。通过不断地条件判定来对某一事件进行分类,且后一类的判定条件是基于前面的所有判定条件的基础上新加的条件。举例:判断某一个物品的类别,水果——>红色的——>甜的——>满足以上条件,判断该物品为苹果。
- 根节点:表示数据集的整体。一般的,一棵决策树包含一个根结点。
- 内部节点:每个节点表示一个特征的划分条件。一棵决策树可以包含若干个内部节点。
- 叶节点:每个叶节点对应一个类别(分类问题)或一个数值(回归问题),即对应于决策结果。一颗决策树可以包含若干个叶节点。
- 先验分布:根据一般的经验认为随机变量应该满足的分布。先验分布是先知道结果但不知道原因,猜参数服从什么分布。
- 后验分布:通过当前训练数据修正的随机变量的分布,比先验分布更符合当前数据。后验分布是你学习经验后有根据地猜参数服从啥分布。
- 决策树桩:一棵仅有一层划分的决策树。
2.基本流程

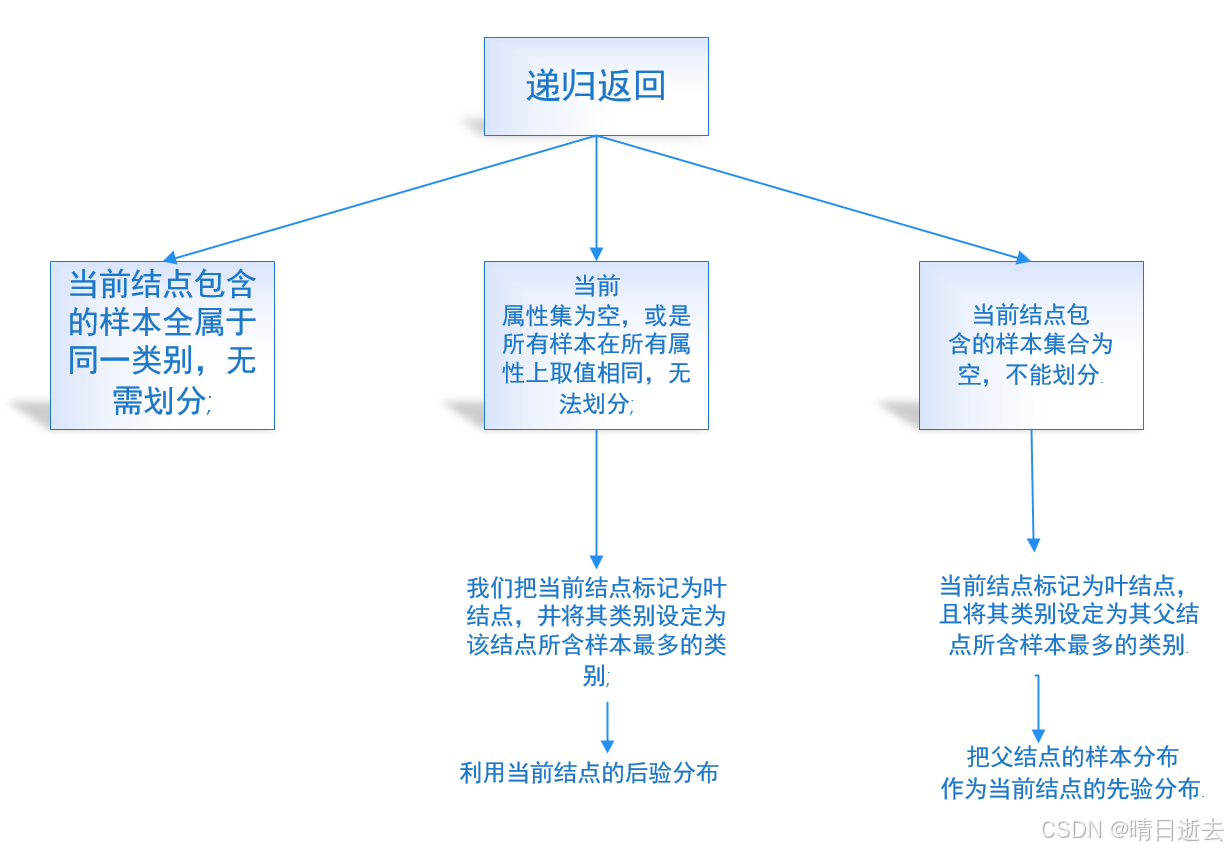
二、划分选择
随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的"纯度"(purity)越来越高。
1.信息增益
信息熵:假定当前样本集合D中第k类样本所占的比例为Pk(k = 1,2,. . . , IYI),则D的信息熵定义为
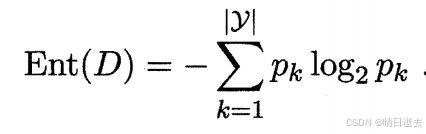
pk具有非负性,nt(D)的值越小,则D的纯度越高.
信息增益:用属性α对样本集D进行划分所获得的"信息增益"(information gain)。
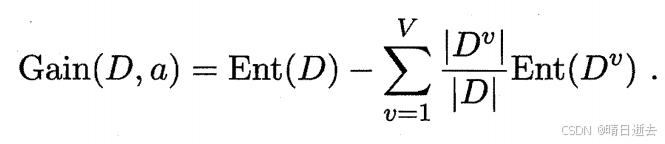
信息增益越大,则意味着使用属性α来进行划分所获得的"纯度提升"越大. 可以选择增益大的划分为属性,作为决策树的一条分支。信息增益衡量的是选择特征后数据的不确定性减少的程度。
2.增益率
增益率:
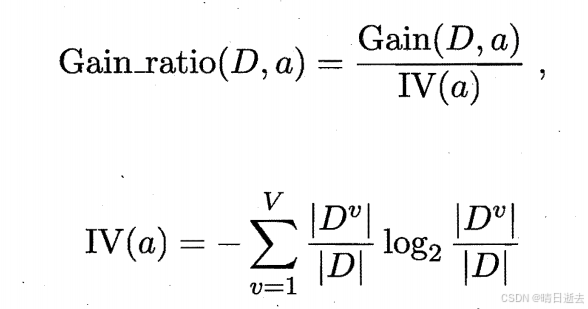
IV(α)称为属性α的"固有值".属性α的可能取值数目越多(即V越大),则IV(α)的值通常会越大.
信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,用增益率进行分枝。但需要注意,增益率准则对可取值数目较少的属性有所偏好。
3.基尼指数
基尼指数:
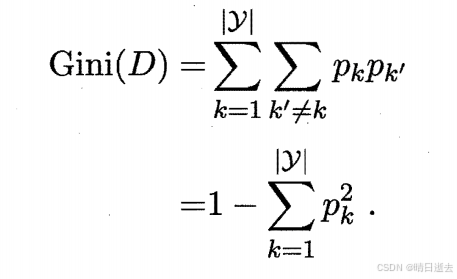
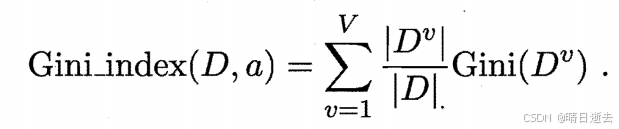
Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率.因此,Gini(D)越小,则数据集D的纯度越高。选择基尼指数最小的作为最优属性划分。
三、剪枝处理
决策树容易发生过拟合,特别是在树的深度较大时。为了避免过拟合,可以通过剪枝来简化模型。剪枝的过程有两种:
1.预剪枝
在构建树时就限制树的增长,如设置树的最大深度或每个节点的最小样本数。当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点。
通过限制树的最大深度限制、每个叶子节点的最小样本数、限制节点的最小信息增益(当信息增益小于某个阈值时停止分裂)等方法来进行预剪枝。
存在欠拟合风险。
2.后剪枝
在决策树完全构建之后,从叶节点开始,去掉一些不必要的分支,从而提高模型的泛化能力。若将该结点对应的子树替换为叶结点能来决策树泛化性能提升,则将该子树替换为叶结点。
后决策欠拟合风险很小,但相比前剪枝训练耗费的时间成本较大。
四、连续与缺失值
1.连续值处理
连续值指的是可以取任意数值的数据,如年龄、价格、温度等。在机器学习中,需要对连续值进行离散化处理。
二分法:定样本集D和连续属性α,假定α在D上出现了η个不同的取值,将这些值从小到大进行排序,记为{α1α2..αn}.基于划分点t可将D分为于集![]() 和
和![]() 。其中
。其中![]() 包含那些在属性α上取值不大于t的样本,
包含那些在属性α上取值不大于t的样本,![]() 则包含那些在属性α上取值大于t的样本。
则包含那些在属性α上取值大于t的样本。
对连续属性α我们可考察包含n-1个元素的候选划分点集合,
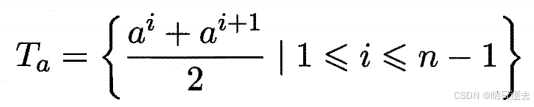
![]()
则二分法后的信息增益可以这样表达:
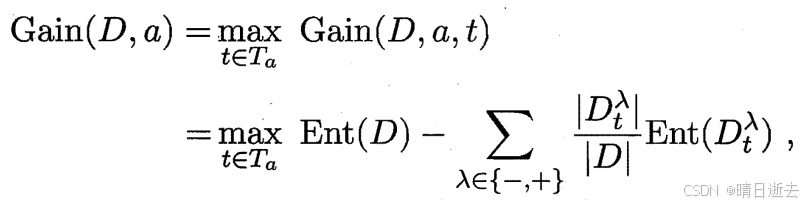
Gain(D,α, t)是样本集D基于划分点t二分后的信息增益。我们就可选择使Gain(D,α,t)最大化的划分点,使信息增益最大,使数据集分类的纯度提升。
2.缺失值处理
缺失值是指数据集中某些条目缺少值,常见的处理方法有:
删除缺失值:直接删除含有缺失值的样本或特征,但这种方法适用于缺失数据较少的情况。
填充缺失值:
均值填充:用该特征的均值填充缺失值,适用于数值型数据。
中位数填充:用中位数填充,适合处理有异常值的数据。
众数填充:用最频繁出现的值(众数)填充,适合处理类别型数据。
插值法:基于已有数据的趋势推测缺失值,如线性插值。
预测填充:利用其他特征来预测缺失值。例如,使用回归模型根据其他特征预测缺失值。
五、多变量与决策树
多变量决策树(斜决策树):在经典的决策树(如CART或ID3)中,每个节点的划分通常基于单一特征,比如“年龄 > 30”,这样的数据划分方式是逐个特征进行的。而在多变量决策树中,决策规则可能包含多个特征的组合,比如:“年龄 > 30 且 收入 > 50000”,这就可以同时考虑多个特征的交互作用来进行决策。
即在多变量决策树的学习过程中,不是为每个非叶结点寻找一个最优划分属性,而是试图建立一个合适的线性分类器(线性模型)。
六、参考文献
1.周志华《机器学习》
2.Releases · datawhalechina/pumpkin-book · GitHub
3.决策树_百度百科


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









