







小白学习笔记,有误请指正
目录
(1) 计算类内散度矩阵(Within-Class Scatter Matrix)
(2) 计算类间散度矩阵(Between-Class Scatter Matrix)
一、线性判别分析基本定义
线性判别分析(LDA)的核心思想是通过线性变换将数据从高维空间映射到低维空间(通常是1维或2维),使得在新空间中,不同类别之间的距离尽可能大(类间距离大),而同一类别内部的散布尽可能小(类内距离小)。
LDA通过寻找投影方向来实现数据的降维和分类:
- 类内散度(Within-Class Scatter): 类内散度度量的是每个类别内部数据点的分散程度。LDA希望将同一类别的数据尽可能聚集在一起,因此类内散度应尽量小。即让同类样例投影点的协方差尽可能小。
- 类间散度(Between-Class Scatter): 类间散度度量的是不同类别之间均值的距离。LDA希望使得不同类别的均值尽可能远离,因此类间散度应尽量大。
就像书本上的概念:
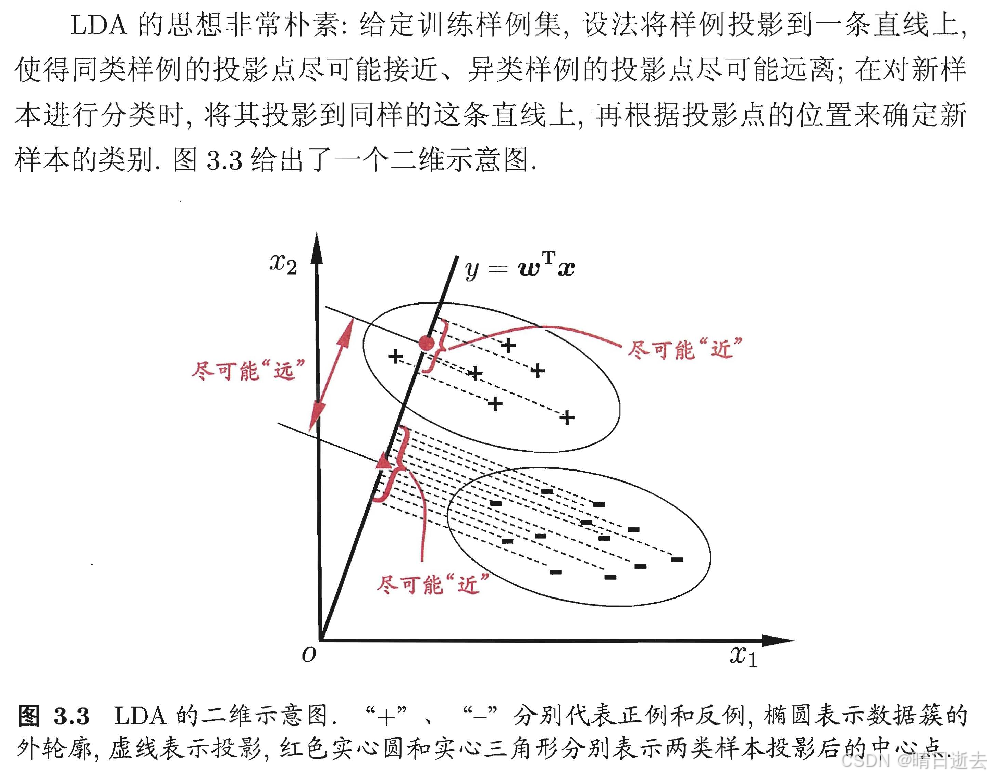
二、实现步骤
(1) 计算类内散度矩阵(Within-Class Scatter Matrix)
类内散度矩阵表示同一类别内数据点的分布情况。对于每一个类别 ,计算该类别内数据点的协方差矩阵,然后对所有类别求和,得到类内散度矩阵:
两个类别的类内散度矩阵:
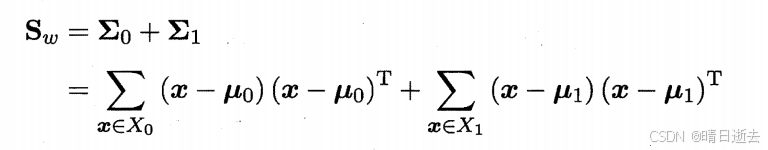
其中,μ0是类别X0的均值,μ0是类别X1的均值,xi是该类别中的样本。
多个类别的全局散度矩阵:

多个类别的类内散度矩阵:
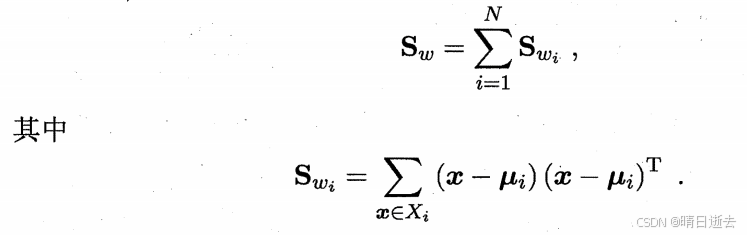
(2) 计算类间散度矩阵(Between-Class Scatter Matrix)
类间散度矩阵反映了不同类别之间的分布情况。它表示的是类别均值与全体数据均值之间的差异:
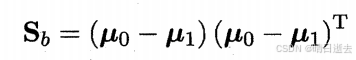
其中,μ0是类别X0的均值,μ0是类别X1的均值。
多个类别的类间散度矩阵:
(3)求解最优投影矩阵
LDA的目标是找到一个投影方向,使得在这个方向上类间散度尽可能大,而类内散度尽可能小。为了实现这一目标,我们需要最大化类间散度与类内散度的比值,具体来说,求解以下优化问题:
其中,w是投影向量。
这个优化问题的解可以通过求解广义特征值问题得到:
![]()
其中,λ 是拉格朗日乘子,w是对应的特征向量。我们通过求解这个特征值问题,得到一个或多个特征向量(投影方向),这些特征向量就是我们需要的线性判别方向。
多个类别的优化问题解决:
其中,![]() ,W的闭式解则是
,W的闭式解则是![]() 的N-1个最大广义特征值所对应的特征向量组成的矩阵。
的N-1个最大广义特征值所对应的特征向量组成的矩阵。
(4)选择投影方向
一般情况下,LDA会选择前k−1个特征向量作为投影矩阵,其中 k 是类别的数量。对于每个样本,投影到这些特征向量上,得到一个低维表示。这些特征向量是按照类间散度与类内散度的比值大小进行排序的。
(5)数据投影和分类
一旦得到投影矩阵,我们就可以将原始数据投影到低维空间中。在低维空间中,通常使用简单的分类方法(如高斯判别分析、最近邻分类等)来进行分类。
在投影后,样本的类别标签可以通过计算其在新空间中的位置来预测。通常,LDA通过假设各个类别的样本在低维空间中呈高斯分布,并进行贝叶斯分类。
三、参考文献
1.周志华《机器学习》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









