




动手点关注 干货不迷路 👆
日前,字节跳动技术社区 ByteTech 举办的第四期字节跳动技术沙龙圆满落幕,本期沙龙以《字节云数据库架构设计与实战》为主题。在沙龙中,字节跳动基础架构数据库开发工程师马浩翔,跟大家探讨了 《从单机到分布式数据库存储系统的演进》,本文根据分享整理而成。
存储系统概览
存储系统是指能高效存储,持久化用户数据的一系列系统软件。在众多的存储系统中,以下是三类比较主流的存储产品及其特点分析:
块存储
底层语义,基于 block 编程;
接口朴素:在 Linux 的 IO 软件栈中,要直接使用块存储的话就要基于 LBA 编程,因此接口较为简单朴素,再加上块存储本身处于整个存储软件栈的底层,这导致块存储使用起来并不十分友好;
追求低时延、高吞吐:研发一个块存储系统,在设计目标上我们往往会追求超高的性能,体现在超低的时延和超高的吞吐。但考虑到块存储的接口确实过于朴素,往往只有一些追求超高性能的系统才会直接基于块存储构建,然后自建应用层 cache。
对象存储
公有云上的王牌存储产品:在 IT 时代,“Everything is data”的趋势迅速催化了对象存储系统。尤其对于字节跳动的业务而言,使用对象存储系统来处理视频、图片、音频等非结构化的数据,语义最为自然;
非结构化数据,提供 immutable 语义:一旦图片或视频等非结构化数据上传至对象存储系统成功,则无法对其进行原地修改,只能通过删除旧数据,重新上传新数据的方式完成“修改”逻辑;
成本优先:一般不苛求单次操作的时延,但是非常注重系统吞吐 & 存储成本。
文件系统
接口语义丰富,普适性强:遵循 POSIX/弱 POSIX 语义,诸如 Open、Write、Read 等许多操作数据的接口都能在文件系统中被找到。
拥有较多开源的分布式实现,生态良好。
一般也不苛求时延,注重系统吞吐 & 存储成本。
单机数据库存储解析
单机数据库存储,要从内存层和持久化层两个方面来解析。在内存层,仅说关系型数据库,其内存数据结构特点可以总结为:一切都是“树”。我们以最常见的 B+ 树为例,B+ 树具有以下突出的特点:
In memory 操作效率非常高: B+ 树搜索时间复杂度是 log 级别;并且 B+ 树的叶子节点构成链表,非常有利于在内存中对数据进行 scan 操作。
磁盘操作效率高:B+ 树的 Fanout 足够大,树的层级较少,呈矮胖状,可以减少磁盘 IO 数;同时 B+ 树的非叶子节点只存索引数据,叶子节点存实际数据,能大大压缩树高,进一步减少磁盘 IO 数。
数据结构高度统一:数据 & 索引都可以直接组织成 B+ 树,因此代码的可维护性、可读性和开发效率都比较好。
仅有内存数据结构当然是不够的,我们还需要设计高效的磁盘数据结构,下图展示了从内存数据结构到磁盘数据结构的数据持久化过程:
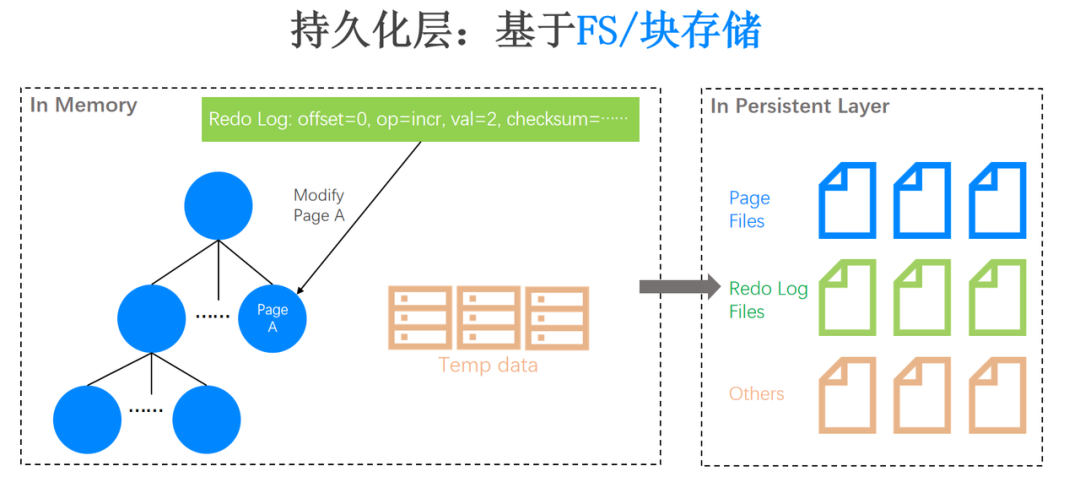
左边虚线框描绘的是 In Memory 结构示意图。举个例子,如果我们要修改 Page A 的某一行数据,对其中的一个字段进行自增,自增值是 2。自然而然会产生一个数据库的物理操作日志,即 Redo Log,用来描述我们对 Page A 的修改。同时,在数据库的事务执行过程中,可能还会产生大量临时数据(图里的 Temp data),当内存不够用的时候也需要将其
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









