 卡顿与ANR治理:从原理到实践的优化策略
卡顿与ANR治理:从原理到实践的优化策略





背景
卡顿 & ANR 在各 APP 中都是非常影响用户体验的问题,关于其的分析和治理一直也是个老生常谈的话题。过去调查卡顿 & ANR 问题主要依赖上报的堆栈和 traceInfo 文件,通过这些信息还原问题的现场情况。但是在实践过程中发现,现有监控机制下堆栈的抓取时机是晚于问题发生的,大部分情况获取到的是问题发生后某一瞬间的堆栈,随机性强,是不置信的,无法反映问题的真实现场情况,同一个问题可能聚合到不同堆栈中,无法清晰的归类和定位问题,这就使得很多开发者清楚原理,但到了具体 case 时无从下手,调查起来缺乏方向甚至因堆栈聚合的不置信而陷入了错误的排查方向,效率低下。另一方面,大多能够准确衡量性能的工具本身会带来严重耗时问题,无法用于线上,而性能问题大多发生于复杂的线上用户场景。所以,如何对卡顿 & ANR 进行有效的防治就是我们需要考虑的问题。
卡顿 & ANR 治理现状和痛点
过去几年,在业务发展的同时积累了大量的卡顿 & ANR 问题,对用户的使用体验带来了极大的负面影响。随着治理工作的进行,现有的监控机制暴露出一定的问题,堆栈不置信、聚合错误、缺乏正确信息、缺乏有效防治策略,这些成了制约治理工作进行的瓶颈。
卡顿 & ANR 现状
长期以来,新老问题的不断叠加,同时没有系统的进行相关防治工作使得数据指标常态高水位,影响的用户以及发生次数都很不乐观。
在治理之初,卡顿周均影响用户比例达到 10‰ 左右,受影响的用户平均 5 次卡顿,ANR 影响用户则常态高水位保持在 6‰ 左右,受影响用户平均 ANR 2 次,这些数据在公司的各大 APP 中都排名很差。
对问题进行筛查发现,问题呈现头部集中,整体分散的现象,TOP 2 问题占总体的 30%,其余问题零零散散的分布在 60000 个不同的堆栈聚合上,观察这些不同的堆栈聚合,TOP 2 问题落在了系统的堆栈上,同时很多小量级聚合并非直观上的耗时点,这些现象给我们初期的治理工作带来了很大的困扰,占比极大的 TOP 问题优先级最高,但是如何导致,需要如何优化,分散在 60000 个堆栈聚合上的问题应该如何切入。
另外,长期以来缺乏有效的增量问题防治能力。在开发、测试阶段没有专项测试,问题很少暴露,也缺乏持续跟进计划和问题复现定位能力,在灰度、线上等用户场景下报警策略单一,只有新增堆栈聚合情况下才会触发报警,实际运行中发现报警策略很少触发,大多情况下也无法消费。
卡顿 & ANR 检测机制及问题
首先,我们来看一下 TOP 2 问题的堆栈表现。
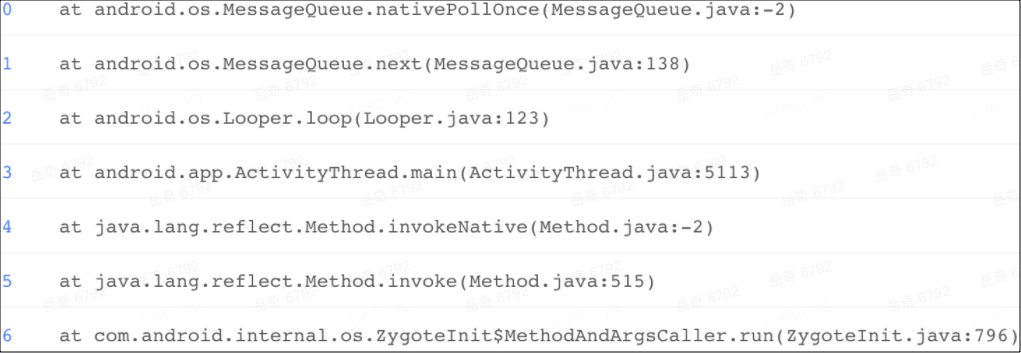
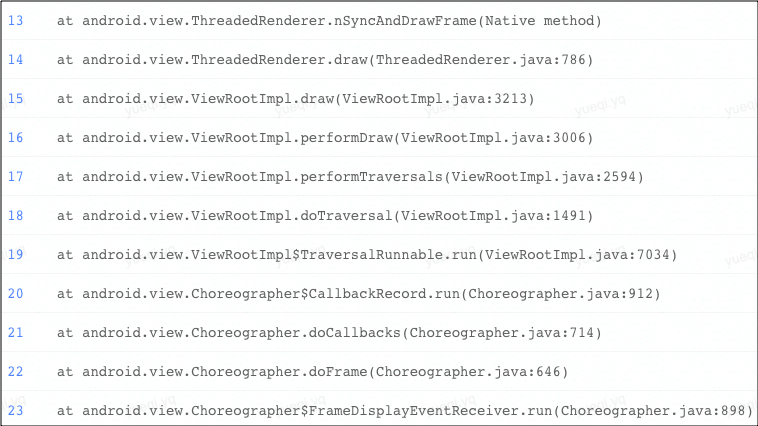
TOP 2 问题聚合到了 nativePollOnce 和 nSyncAndDrawFrame 系统堆栈上,占比分别达到了 20% 和 10%,nativePollOnce 是主线程消息机制下的消息分发函数,nSyncAndDrawFrame 是页面的基础绘制函数,直观上看没有问题,对此我们在初期进行了一系列的常规分析和尝试。以 TOP 1 的 nativePollOnce 为例。首先,常规怀疑该方法本身耗时,分析了方法在 Java 层和 native 层的执行逻辑。
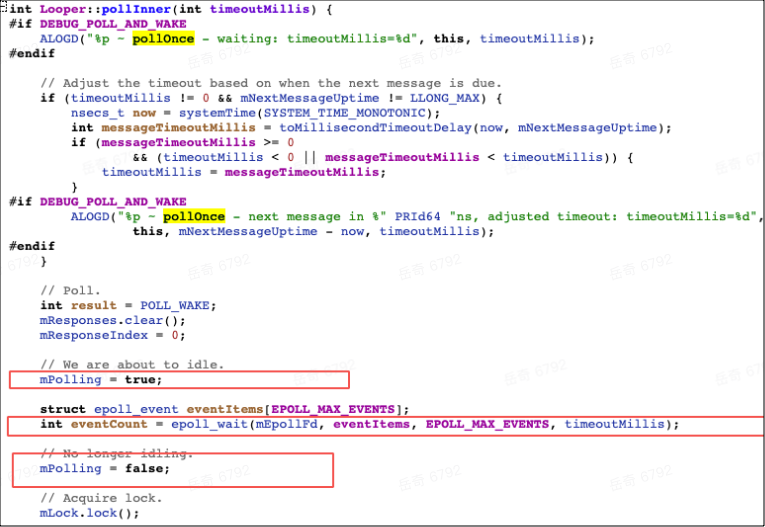
看到在 native 层有 epoll_wait 调用,通过在 C++ 层 hook 相关方法验证,没有发现问题。接着我们在 Java 层构造一个一直存在的 idleTask,使得消息队列空闲时就执行 idle 任务而不休眠,验证发现问题仍然存在。再看 Java 层逻辑。
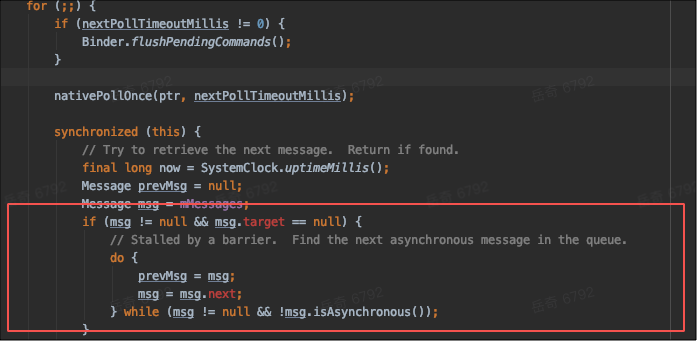
这部分是关于同步屏障的处理,异步更新 UI 可能会导致同步屏障出现多线程问题而无法移除,验证后排除该可能。调查至此,并没有找到该问题的明确原因,排名第二的 nSyncAndDrawFrame 的问题与此类似,经过埋点调查,很多 nSyncAndDrawFrame 问题下的调用链路并不耗时。
此时,我们回过头来看一下目前的监控机制。对于卡顿 & ANR 的检测和分析,长期以来我们依赖于 NPTH 工具提供的能力。对于卡顿的监控,采用拦截消息调度流程,在消息执行前埋点计时,当耗时超过阈值时,则认为是一次卡顿,会进行堆栈抓取和上报工作。ANR 的监控则是通过定时轮询,在线程中每 500ms 定时和 AMS 进行交互,通过 AMS 的 Error 信息来判断是否发生 ANR,当确定发生 ANR 时,进行堆栈的抓取和信息的上报。
在实际分析解决问题时,以上不论卡顿还是 ANR,在现有检测机制下获取到的堆栈及其他信息都存在一定的缺陷,无法有效解决问题。
对于卡顿,由于是以 Message 为维度进行检测,当检测到 Message 超时发生卡顿时,拿到的堆栈是从 Message 开始到当前执行 Method 的堆栈链路。实际上 Message 中可能执行了几千个 Method,耗时点很可能是 Message 中的另外 Method 或者多个 Method 耗时堆积导致 Message 超时,这一点我们无法确认。因此知道 Message 耗时对我们排查问题帮助很小,我们还是无法定位到具体的可消费的耗时点,这就导致当前的卡顿数据无法快速消费。
对于 ANR,抓栈时机是定时轮询有 ANR 发生才进行的。一方面从发生 ANR 到开始抓栈到抓栈完成都有一定的时间间隔,除了少部分循环等待、锁等待等卡住场景能够相对准确抓到,大部分问题抓到堆栈和问题现场不匹配,堆栈会落在耗时点之后的调用链路上。另一方面对于那种多次耗时累积导致 ANR 的情况,单点的堆栈也无法定位问题。
在此基础上,我们接入了调度时序图,调度时序图就是主线程 MessageQueue 中的 Message 执行情况,包括已执行 Message、当前 Message 和待执行 Message,可以在 ANR 发生时一起上报。我们借助调度时序图来看 nativePollOnce 聚合下的 case:
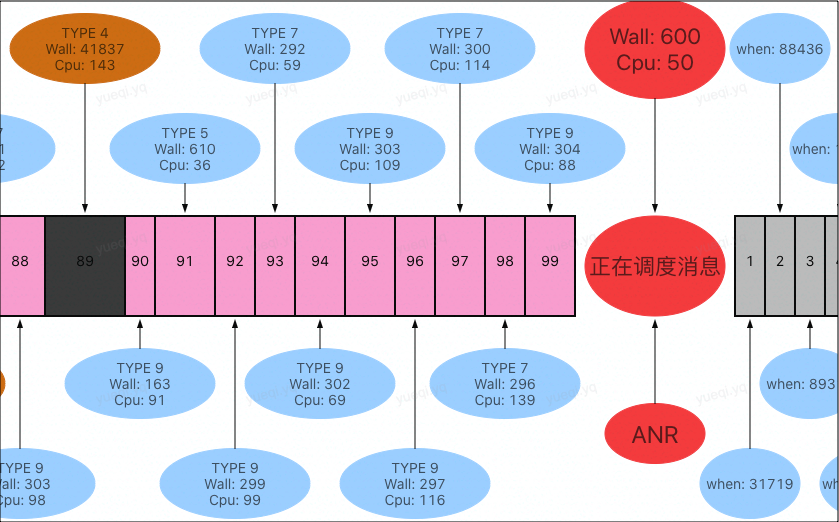
可以看到,前边有 Message 耗时 42s,而上报的堆栈当前 Message 耗时很少,ANR 和当前 Message 没有关系。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 2万+
2万+



 到【灌水乐园】发言
到【灌水乐园】发言







