






将某种现象的指标数值按照时间序列排列而成的数值序列,分为三类:
1.描述过去
2.分析规律
3.预测未来
时间序列数据:同一对象在不同时间连续观察得到的数据,两要素:1.时间要素 2.数值要素
e.g.:1.从出生到现在你的体重数据(每年一次)
2.中国历年来的GDP的数据
3.某地每隔一小时测得的温度数据
可分为时期时间序列,时点时间序列
时期时间序列:反应现象在一定时期内发展的结果(2)可累加,有实际意义
时点时间序列:在一定时点上的瞬间水平(1,3)不可累加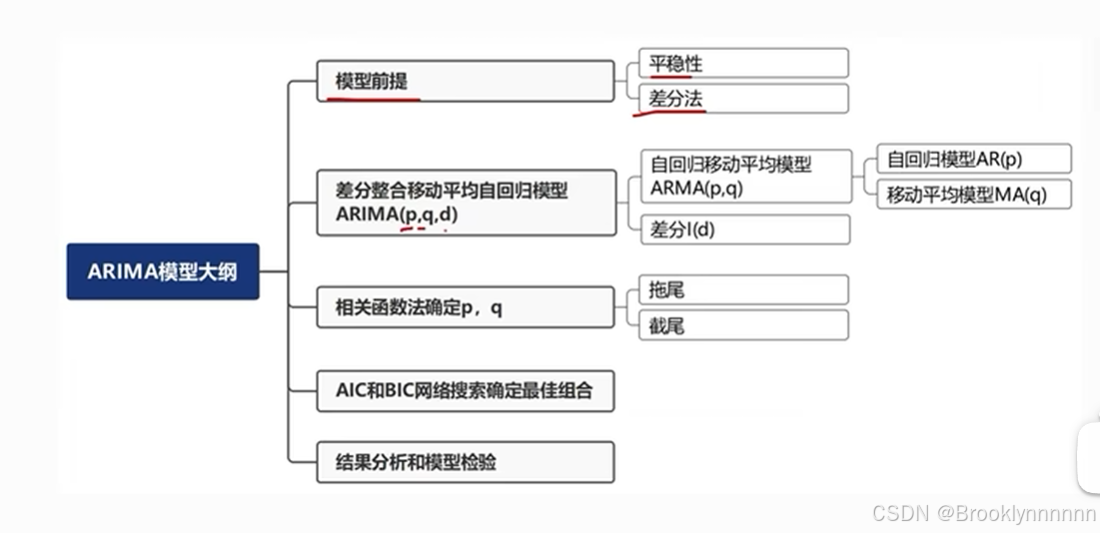
 自回归模型AR(p):描述当前值与历史值之间的关系,用变量自身的历史数据对自身进行预测,必须满足平稳性要求(后期会讲怎么判断)。只适用于与自身前期相关的现象(时间序列的自相关性)
自回归模型AR(p):描述当前值与历史值之间的关系,用变量自身的历史数据对自身进行预测,必须满足平稳性要求(后期会讲怎么判断)。只适用于与自身前期相关的现象(时间序列的自相关性)

p也叫自回归模型的阶数
移动平均模型MA(q)
关注自回归模型中误差项的累积
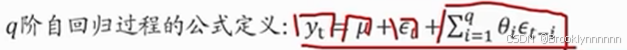
即时间序列当前值与历史值没有关系,只依赖历史白噪声的线性组合
历史白噪声:可理解为随机误差
移动平均法能有效消除预测中的随机误差
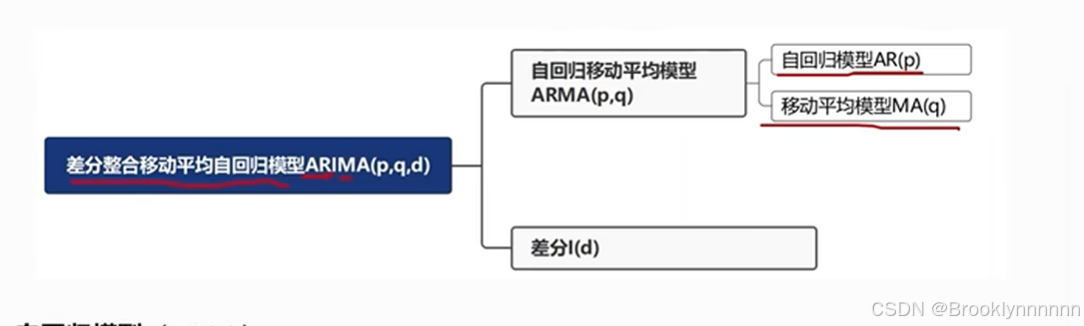
自回归移动平均模型ARMA(p,q)
自回归与移动平均的结合
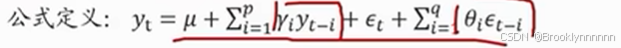
即该序列可以由自身的过去或随机扰动值表示,如果该序列是平稳的,就可以通过该序列过去的行为预测未来。
差分自回归移动平均模型ARIMA(p,d,q)
将自回归模型,移动平均模型,差分法结合
p:自回归项,q:移动平均项数,d:时间序列平稳时做的差分次数
原理:将非平稳时间序列转换为平稳时间序列然后将因变量仅对他的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型
ARIMA模型的建模步骤:
1.对序列绘图,进行平稳性检验,观察序列是否平稳。非平稳时间序列要进行d阶差分,转换为平稳序列。
2.对平稳时间序列分别求得自相关系数(ACF)和偏自相关系数(PACF),通过对自相关图和非自相关图的分析,得到最佳阶数p,q;
3.由以上得到的d,p,q,得到ARIMA模型,最后对得到的模型进行模型检验。
例题:

1.检验平稳性
平稳序列:要求经由样本时间序列得到的拟合曲线在未来的一段时间内仍然能够按照现有的形态延续下去
要求序列的均值和方差不发生明显变化
严平稳:序列所有的统计性质(均值和方差)都不会随着时间的推移发生变化(一般无法实现)
宽平稳:期望与相关系数(依赖性)不变(大部分)
2.差分法实现
时间序列在t和t-1时刻的差值,

不建议差分次数过高,一般最多两次
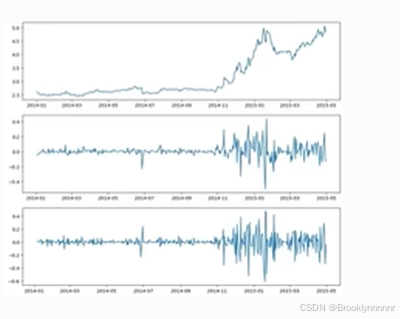
后面两图区别不大,做一次两次都可
自相关系数ACF:
自相关系数反映了同一序列在不同时序的取值之间的相关性。对于时间序列yt,yt与yt-k的相关系数称为yt间隔k的自相关系数。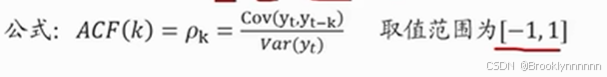
偏自相关系数PACF:对于一个平稳AR模型,求出滞后k自相关系数后,实际上得到的并不是yt与yt-k的单纯相关关系。因为yt同时还会受到中间k-1个随机变量的影响。为了单纯测出yt-k对yt的影响,引进PACF的概念。对于平稳时间序列yt,所谓滞后k偏自相关系数指在剔除了中间k-1个随机变量的干扰之后,yt-k对yt影响的相关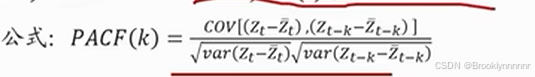 程度。
程度。
这两个公式不仅能判断平稳性,还能解出p,q。
判断一个时间序列的平稳性:主观:1.时间序列趋势图2.自相关函数图
客观:3.ADF检验
3.ADF检验:原理:假定该数据为随机游走,即不稳定,得出p如果接近1,即满足假设,不稳定;若接近0,不满足假设,稳定。
用MATLAB实现,对得出的数据进行分析
e.g.:

第一个值:test statistic,t检验
第二个值:p-value,即p值,表示t统计对应的概率值
第三、四个值:lags used,表延迟和测试的次数
第五个值:{10%:xxx,1%:xxx,5%:xxx},不同程度拒绝原假设的统计值
如何确定:1.第一个值与第五个值的三个参数作比较,同时小于三个值说明平稳
2.第二个值是否非常接近0(0.05)

不做差分时不平稳,下面两列是差分后得到的数据,都平稳
2.自相关图
通过自相关系数和偏自相关系数作图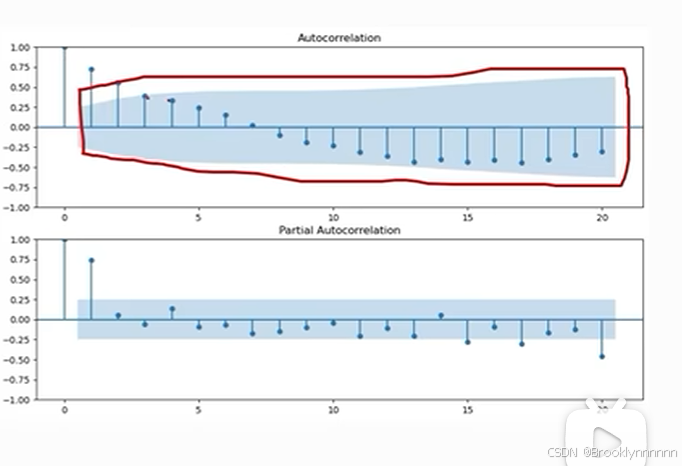 如图,大部分系数都落在置信区间内,说明序列平稳,不需要差分。因此ARIMA模型中I对应的d为零。
如图,大部分系数都落在置信区间内,说明序列平稳,不需要差分。因此ARIMA模型中I对应的d为零。
确定p,q
拖尾:序列以指数率单调递减或震荡衰减;截尾:序列从某个时点变得非常小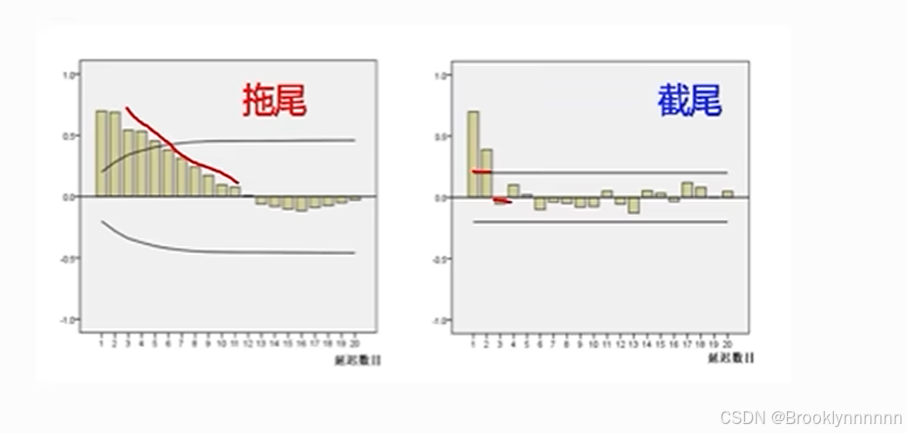
截尾判断:出现以下情况,视为(偏)自相关系数d阶截尾
1.在最初的d阶明显大于2倍标准差范围
2.之后几乎95%的(偏)自相关系数都落在2倍标准差范围以内
3.由非零自相关系数衰减至在零附近小值波动的过程非常突然
拖尾判断:
1.有超过5%的样本都落在2倍标准差范围以外
2.由显著非0的偏自相关系数衰减为小值波动的过程非常缓慢或比较连续
不规则衰减较难判断,一般归为拖尾
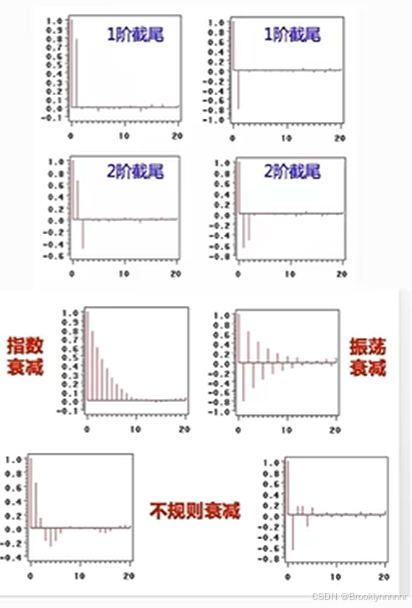
注:p,q,d的确定方式都偏主观,有时不同的方法算出的值不一样,言之有理即可
通过自相关系数(ACF)和偏自相关系数(PACF)作图确定p,q
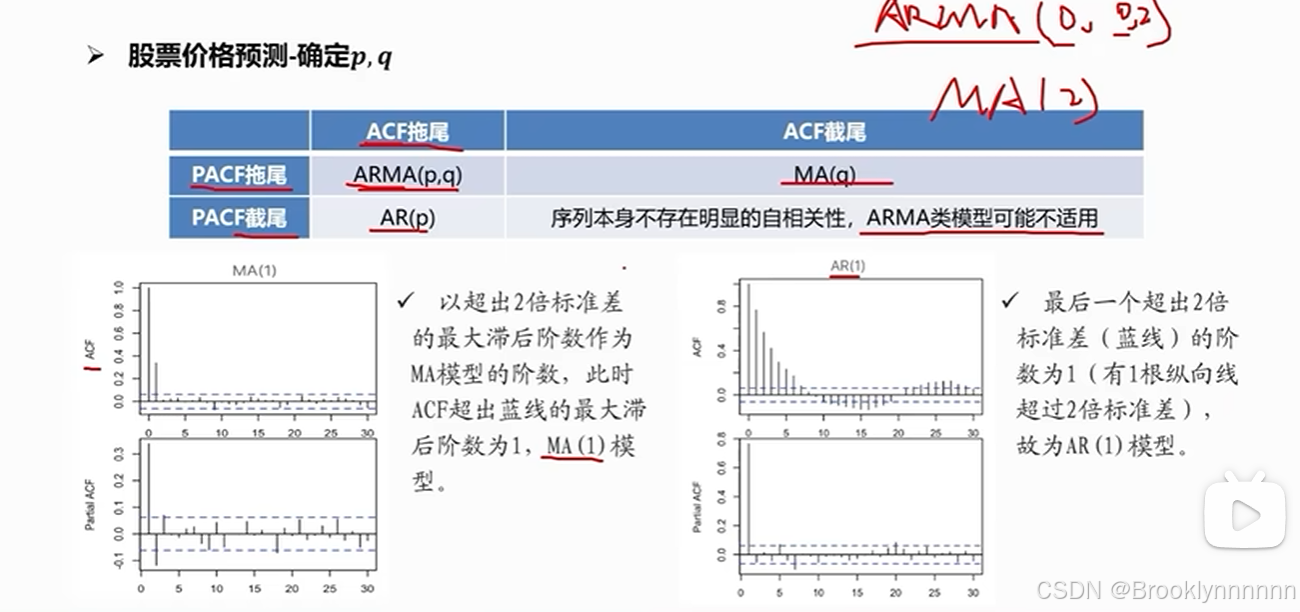
如图1, ACF为截尾,PACF为拖尾,依照表格为MA(q),q值判断:ACF图中超出标准差的阶数-1,所以q=2-1;
如图2,ACF为拖尾,PACF为截尾,依照表格为AR(p),p值判断:PACF图中超出标准差的阶数,所以p=1;
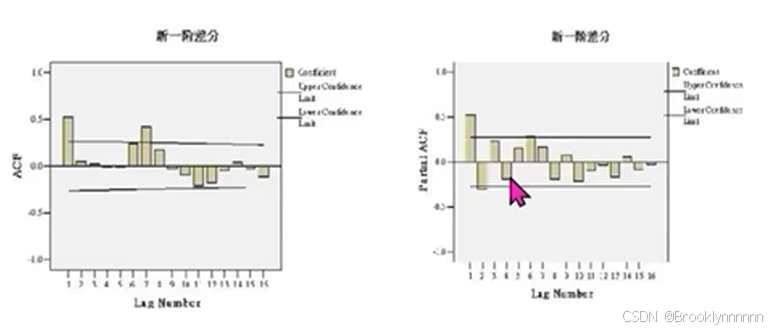
如图3,ACF为拖尾,PACF为拖尾,依照表格为ARMA(p,q)
p值判断:PACF图中自第二阶后系数都落在二倍标准差范围内,p=2;(查阅资料发现有的减一,有的不变,区别不大)
q值判断:ACF图中自第七阶后系数都落在二倍标准差范围内,q=7-1=6;
若ACF,PACF均为截尾,则ARMA模型不适用
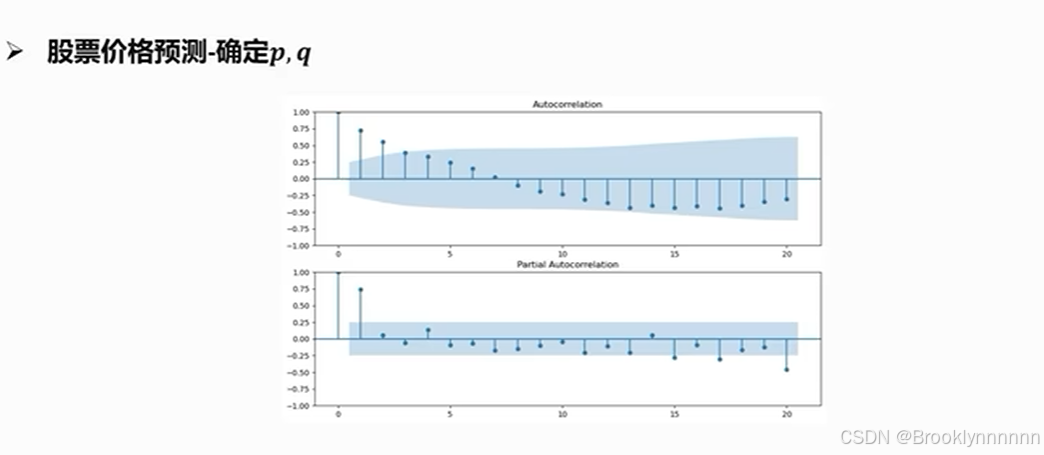
回到股票价格预测:ACF拖尾,PACF2阶截尾,所以用AR(1)或AR(2) 模型(查阅资料发现还有AR(2)区别不大),或ARIMA(1,0,0)模型
通过拖尾和截尾对模型定阶具有很强的主观性。在参数选择时,需要平衡预测误差与模型复杂度,可根据信息准则函数法来确定模型阶数:
AIC准则和BIC准则:参数与结果精度的权衡
AIC:赤池信息准则
公式:AIC=2K-2ln(L) L:模型的极大似然函数 K:模型参数个数
从预测角度,选择一个好的模型预测
BIC=Kln(n) -2ln(L) n:样本容量
从拟合角度,对现有数据拟合最好的模型

简单粗暴,直接设p,q的取值范围,此时p,q的取值范围为【0,5】,通过循环网格所有组合算出AIC或BIC最小值
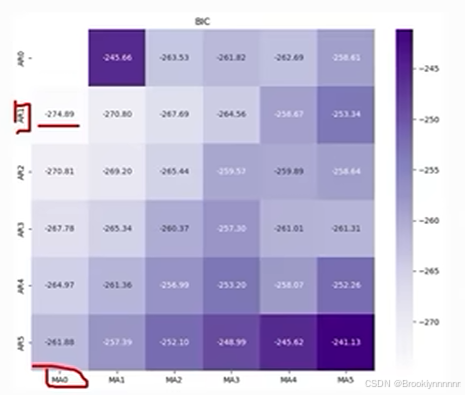
此图通过python代码实现
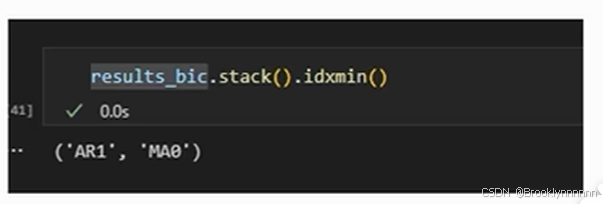
或用Python的封装函数直接对训练集进行运算,更为简单:
 得出
得出

模型检验
检验残差序列的随机性,即残差之间是独立的
残差:![]() ,其中yi是真实值,右项为预测值
,其中yi是真实值,右项为预测值
随机性可通过做函数的自相关图来检验
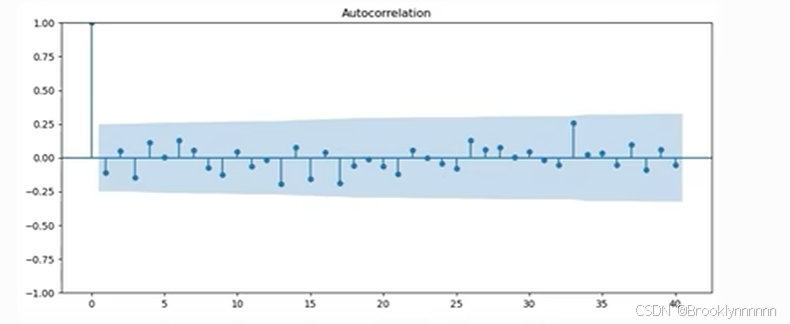
此情况下,残差之间独立性较高
经过检验后,进行预测,由训练集对原始数据集进行预测
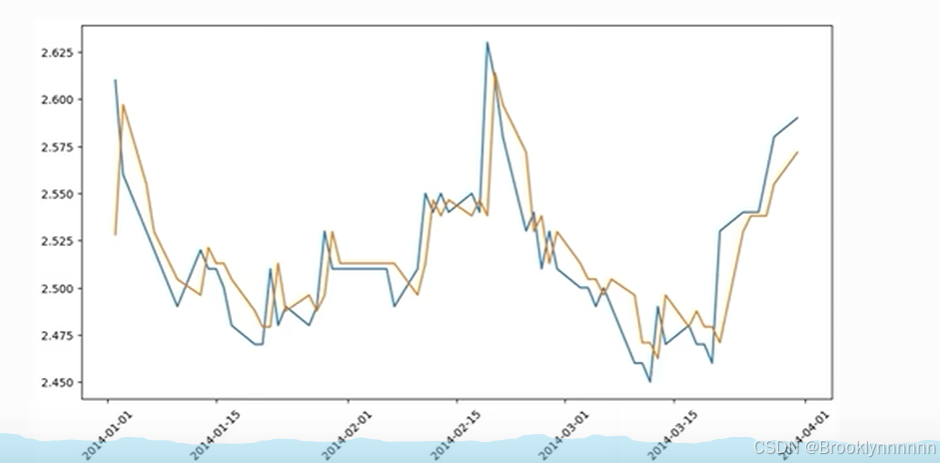
注:本篇代码全部由Python实现,参考资料:数模加油站

















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









