




成年人的世界
别人公众号粉丝刷刷的涨,我的佛系公众号关注全靠随缘。本来挺不淡定的,但今天现实给我上了一课啊。

财大气粗的地产商们都开始搞公众号了,关注公众号就送一个饭盒,你说这涨粉速度能跟别人比么...成年人的世界没有容易二字啊...
不,有容易的!
容易胖、容易老、容易头发变稀少;容易困、容易丑、容易变成单身狗;容易失眠一整夜,容易加班没补贴...这些貌似都挺容易的啊,哈哈。
自娱自乐
今天朋友发了一个段子,居然来自糗事百科...随着抖音、快手的各种火爆,仿佛从前拿着手机刷糗百的日子,已经过去好久了。不知道多少人还会念起那句“天王盖地虎,小鸡炖蘑菇...”。今天就做个小练习,爬一爬糗事百科上的段子吧!
网站分析
段子内容首页
糗百的段子栏目格式比较简单:https://www.qiushibaike.com/text/page/<page_number>/
网站分析
网页格式就更为简单了:
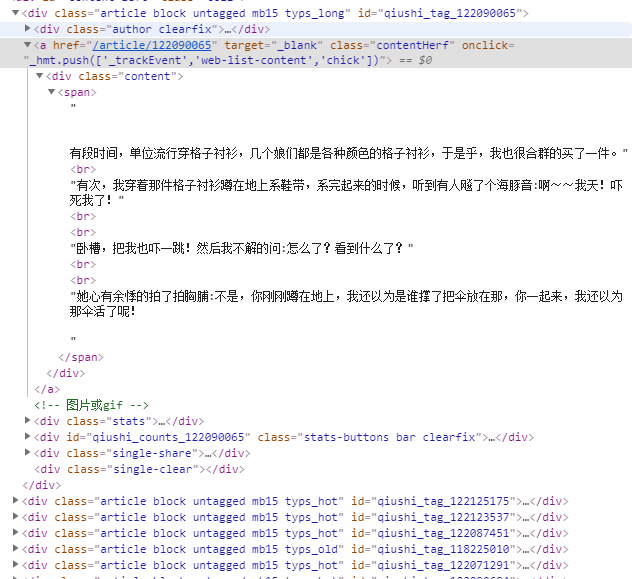
每次数据定位都是用class没有创新意识,这次增加一点难度,在beautifulsoup中引入一下正则吧!可以看到没调内容的id格式都是qiushi_tage_numbers,那么我们是否可以这么定位:findAll('div', {'id': re.compile("qiushi_tag_[0-9]+")})
避坑指南
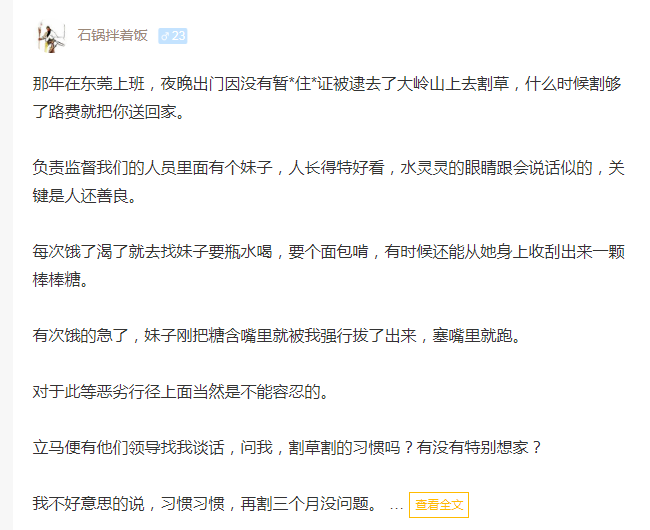
分析段子发现,有些段子内容过长,会出现部分展示的问题,此时我们需要针对这些存在查看全文的段子,获取它的子链接,然后进入新的页面,获取所有段子内容,再进行保存。即当段子内容中存在<span class="contentForAll">查看全文</span>标签时,需要跳转网页后获取内容。
整体代码
段子每页25条内容,为了减少服务器的压力,我们就默认每次获取10页内容即可:
# -*- coding: utf-8 -*-
# @Author : 王翔
# @JianShu : 清风Python
# @Date : 2019/8/15 1:21
# @Software : PyCharm
# @version :Python 3.7.3
# @File : JokeCrawler.py
import requests
from bs4 import BeautifulSoup
import re
import time
class JokeCrawler:
def __init__(self):
self.host = "https://www.qiushibaike.com"
self.headers = {'User-Agent': ('Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36')}
_time = time.strftime('%y%m%d.%H.%M.%S', time.localtime())
self.file = open('糗事百科{}.txt'.format(_time),
'w+', encoding='utf-8')
def get_request(self, url):
r = requests.get(url, headers=self.headers)
return BeautifulSoup(r.text, 'lxml')
def crawler(self, url):
jokes = self.get_request(url).findAll('div', {'id': re.compile("qiushi_tag_[0-9]+")})
for number, joke in enumerate(jokes, start=1):
if joke.find('span', {'class': "contentForAll"}):
_href = joke.find('a', {"class": "contentHerf"})['href']
content = self.get_request(self.host + _href).find('div', {"class": "content"}).text.strip()
else:
content = joke.find('div', {"class": "content"}).text.strip()
self.file.write("{}.{}\n".format(number, content))
def run(self):
for page in range(1, 11):
_url = "{}/text/page/{}".format(self.host, page)
self.file.write("第{}页\n\n".format(page))
self.crawler(_url)
def __exit__(self):
self.file.close()
if __name__ == '__main__':
main = JokeCrawler()
main.run()
来看看我们最终的爬虫结果吧:
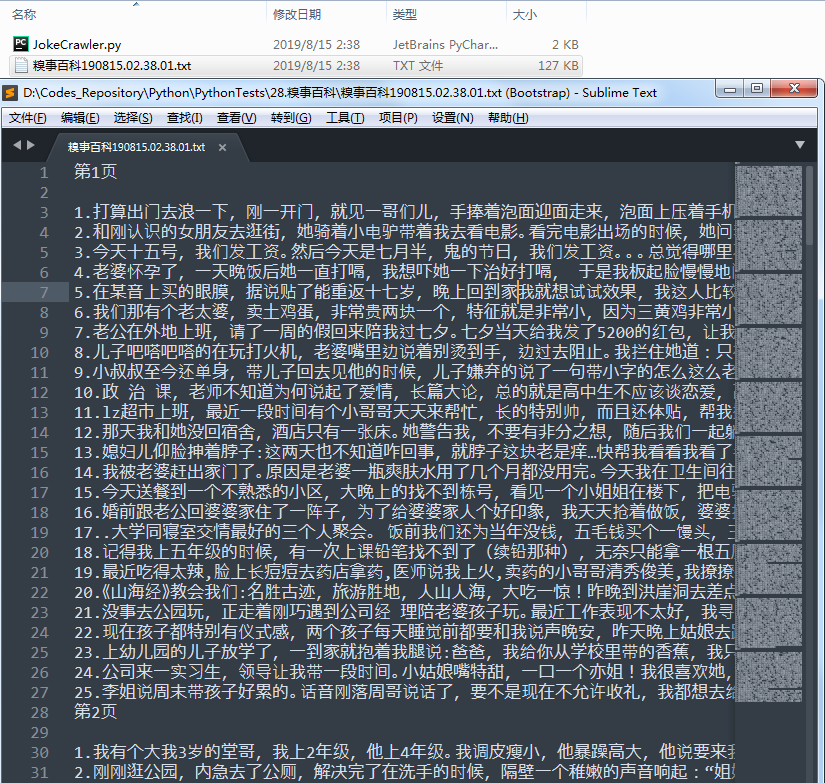
没事儿爬上写段子,休息时候慢慢看吧....
The End
OK,今天的内容就到这里,如果觉得内容对你有所帮助,欢迎点击文章右下角的“在看”。
期待你关注我的公众号清风Python,如果觉得不错,希望能动动手指转发给你身边的朋友们。
希望每周一至五清晨的7点10分,都能让清风Python的知识文章叫醒大家!谢谢……



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









