






 本文介绍了K-means聚类算法的工作原理,包括初始化中心点、数据点分配、更新中心点等步骤,并展示了如何使用sklearn库实现K-means,同时探讨了如何确定最佳簇数、轮廓系数的应用以及K-means在图像压缩中的实践。
本文介绍了K-means聚类算法的工作原理,包括初始化中心点、数据点分配、更新中心点等步骤,并展示了如何使用sklearn库实现K-means,同时探讨了如何确定最佳簇数、轮廓系数的应用以及K-means在图像压缩中的实践。
K-means简介
K-means是一种常见的聚类算法,用于将数据点划分成不同的簇,以便相似的数据点被分配到同一个簇中。
以下是K-means算法的基本工作原理:
初始化中心点: 首先,需要选择K个初始中心点,其中K是你希望将数据点分成的簇的数量。这些中心点可以是从数据中随机选择的点,也可以使用其他初始化方法。
分配数据点: 然后,对于每个数据点,计算它与K个中心点之间的距离,通常使用欧氏距离或其他距离度量。将数据点分配到距离最近的中心点所属的簇中。
更新中心点: 计算每个簇中所有数据点的平均值,然后将这些平均值作为新的中心点。
重复步骤2和步骤3: 重复步骤2和步骤3,直到满足停止条件,通常是当中心点不再发生显著变化,或者达到预定的迭代次数。
输出结果: 最终,K-means算法将数据点分成K个簇,每个簇具有一组数据点,这些数据点在某种程度上相似。
通过sklearn库实现
import pandas as pd
from sklearn.cluster import KMeans
Data = {'x': [25,34,22,27,33,33,31,22,35,34,67,54,57,43,50,57,59,52,65,47,49,48,35,33,44,45,38,43,51,46],
'y': [79,51,53,78,59,74,73,57,69,75,51,32,40,47,53,36,35,58,59,50,25,20,14,12,20,5,29,27,8,7]
}
df = pd.DataFrame(Data,columns=['x','y'])
# 执行K-means
kmeans = KMeans(n_clusters=4).fit(df)
centroids = kmeans.cluster_centers_
# 打印质心位置
print(centroids)
'''
[[27.75 55. ]
[43.2 16.7 ]
[55.1 46.1 ]
[30.83333333 74.66666667]]
'''
# 画出聚类之后的图
import matplotlib.pyplot as plt
plt.scatter(df['x'], df['y'], c= kmeans.labels_.astype(float), s=50, alpha=0.9)
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=100)结果图:
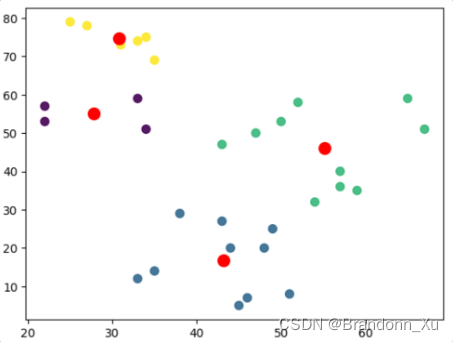
手撕k-means算法!不依赖sklearn
这个算法不算太难,简而言之分为以下步骤:
- 初始化K个质心,记录下质心的位置,并返回一个列表a。
- 计算每个数据点与每个质心之间的距离,找到距离最近的质心,并记录下该质心在列表a中的索引idx。由此形成了K个簇。
- 计算每个簇的中心位置,成为新的质心。
- 循环上述步骤,直至质心位置不再发生明显变化,即收敛。
def init_centroids(X, K):
# 首先,通过np.random.permutation函数创建一个随机的索引数组,这个数组包含0到X.shape[0] - 1的整数,表示数据集X中的数据点的随机排列。
randidx = np.random.permutation(X.shape[0])
# 随机排列的索引数组中选择前K个索引,这些索引对应于数据集X中的K个随机选定的数据点。这些数据点被用作初始的质心,存储在centroids变量中。
centroids = X[randidx[:K]]
return centroids
def find_closest_centroids(X, centroids):
# 获取质心的数量K。
K = centroids.shape[0]
# 创建一个初始值为0的整数数组idx
idx = np.zeros(X.shape[0], dtype=int)
# 遍历数据集中的每个数据点。
for i in range(X.shape[0]):
# 初始化最小距离min_distance为正无穷大,用于记录数据点到最近质心的距离。
min_distance=float('inf')
# 在每个数据点的循环内部,遍历所有的质心。
for j in range(centroids.shape[0]):
# 如果当前计算得到的距离小于最小距离min_distance,说明当前质心更接近该数据点,因此更新min_distance为这个距离,并将当前质心索引j赋值给closest_centroid,表示当前数据点最接近的质心。
distance = np.linalg.norm(X[i] - centroids[j])
if distance<min_distance:
min_distance=distance
closest_centroid = j
# 将当前数据点分配给距离最近的质心,将质心的索引存储在idx数组中,表示每个数据点所属的簇。
idx[i] = closest_centroid
return idx
def find_new_centroids(X, idx, K):
# 创建一个名为centroids的零矩阵,其形状为(K, 特征维度),其中K是质心的数量,X.shape[1]是数据集X中的特征维度。
centroids = np.zeros((K, X.shape[1]))
# 遍历每个簇(质心)的索引i
for i in range(K):
# 对于每个簇,计算该簇内所有数据点的均值,即计算这些数据点的平均位置,然后将这个平均位置作为新的质心位置。
centroids[i] = np.mean(X[idx==i],axis=0)
return centroids
def run_kmeans(K, X, max_iters):
# 初始化质心
centroids = init_centroids(X,K)
# 创建一个全零数组idx,用于存储每个数据点所属的簇索引。
idx = np.zeros(X.shape[0])
# 进入迭代循环,最多执行max_iters次。
for i in range(max_iters):
# 调用自定义函数,寻找最近质心
idx = find_closest_centroids(X, centroids)
# 调用自定义函数,分配新的质心
centroids = find_new_centroids(X, idx, K)
# 最终返回质心的值centroids,以及代表原数据属于哪一个质心的索引idx
return centroids, idx
if __name__ == "__main__":
centroids, idx = run_kmeans(16,X,10)如何找到最佳的k个质心数?——'Silhouette Method' 轮廓系数
轮廓系数(Silhouette Coefficient)是一种用于评估聚类质量的指标。
轮廓系数的计算基于以下两个概念:
a(簇内相似度):对于给定的数据点,计算它与同一簇中所有其他点的平均距离。这个值越小越好,表示数据点与其所属簇的其他点越相似。
b(簇间相似度):对于给定的数据点,计算它与最接近的不同簇中所有点的平均距离。这个值越大越好,表示数据点与其他簇的点越不相似。
轮廓系数的计算公式: (b - a) / max(a, b)。轮廓系数的取值范围在 -1 到 1 之间
如果聚类质量较差,轮廓系数会接近于0;而如果聚类质量很好,轮廓系数会接近于1。
计算过程
-
对于每个数据点 i,计算该点与同一簇中所有其他数据点的平均距离 a(i)。这个距离表示数据点 i 与其所属簇中其他点的相似度。
-
对于每个数据点 i,计算它与其他不同簇中所有数据点的平均距离,选择最小的这个距离作为 b(i)。这个距离表示数据点 i 与其他簇中的点的不相似度。
-
对于每个数据点 i,计算轮廓系数 s(i):s(i) = (b(i) - a(i)) / max(a(i), b(i))
-
对所有数据点的轮廓系数 s(i) 求平均,得到整个聚类的轮廓系数。
轮廓系数的值越接近于1,表示聚类质量越好,数据点更可能被正确地分配到其所属簇。值越接近于-1,表示聚类质量较差,数据点可能被错误地分配。
代码实现
from sklearn.metrics import silhouette_score
sil = []
# 分别以2个、3个、4个、5个质心进行聚类
for k in range(2, 6):
kmeans = KMeans(n_clusters = k).fit(df)
preds = kmeans.fit_predict(df)
sil.append(silhouette_score(df, preds, metric = 'euclidean'))
# 输出各组聚类结果
for i in range(len(sil)):
print(str(i+2) +":"+ str(sil[i]))
2:0.5051959802345012
3:0.5107383117230143
4:0.5069597209807262
5:0.4577649312639833
可视化分析方法:轮廓图分析
轮廓图是一种用于评估聚类质量的可视化工具,通常与K均值聚类一起使用。通过观察轮廓图,可以识别出哪个k值产生了最佳的轮廓系数,以及整体聚类的质量如何。
轮廓图通常包括以下元素:
数据点的刀片形状(Silhouette Plot):轮廓图的核心部分是数据点的刀片形状,其中每个数据点表示为一个垂直的线段。这些线段的长度表示了数据点的轮廓系数,即数据点与其所属簇的相似度。
刀片颜色:不同的簇在轮廓图中通常以不同的颜色表示,以区分它们。每个数据点的刀片线段的颜色对应于其所属的簇。
平均轮廓系数线(Average Silhouette Score Line):轮廓图中通常有一条垂直虚线,表示所有数据点的平均轮廓系数值。这个平均值是所有数据点轮廓系数的均值。
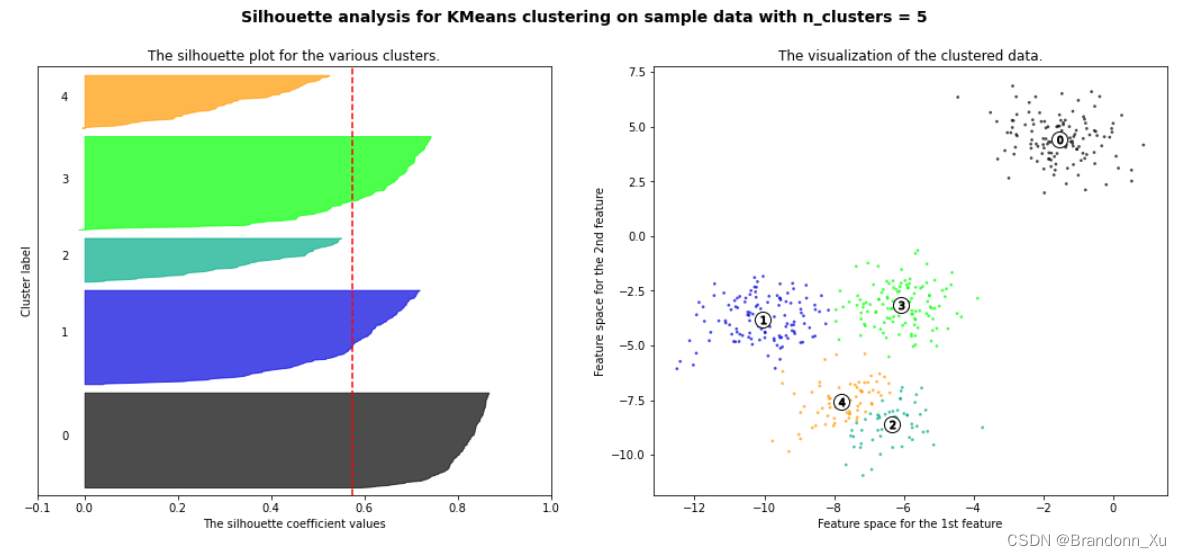
原理很简单:分别为不同的簇画1个“刀片”,刀片的高度(即在x轴上的长度)为该数据点的轮廓系数,若干个数据点根据轮廓系数由小到大排列,并堆叠在y轴上,即形成刀片,故刀片的宽度(即在y轴上的长度)也代表该簇的样本点数量。
代码实现 :
# 执行5个聚类
range_n_clusters = [2, 3, 4, 5, 6]
X = 要执行聚类的数据
# 从k=2开始循环,每次循环都生成一次轮廓图
for n_clusters in range_n_clusters:
# 创建一个1行2列的画布
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(18, 7)
# 设置第1个子图的x轴标签范围
ax1.set_xlim([-0.1, 1])
# 设置第1个子图的y轴标签范围
ax1.set_ylim([0, len(X) + (n_clusters + 1) * 10])
# 执行聚类算法,并获取聚类后的类别标签
clusterer = KMeans(n_clusters=n_clusters, random_state=10)
cluster_labels = clusterer.fit_predict(X)
# 获取当前聚类所有数据点的轮廓系数均值
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters,
"The average silhouette_score is :", silhouette_avg)
# 获取当前聚类所有数据点的轮廓系数
sample_silhouette_values = silhouette_samples(X, cluster_labels)
# 设置y轴上的起始高度
y_lower = 10
# 从0开始循环当前聚类下的k个聚簇,为每个聚簇生成1个“刀片”
for i in range(n_clusters):
# 用类别标签索引出属于i聚簇的轮廓系数
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
# 获取当前i聚簇下有多少个样本点
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
# 为每个刀片生成不同颜色
color = cm.nipy_spectral(float(i) / n_clusters)
# 绘制刀片,在y_lower和y_upper之间堆叠各个样本点的轮廓系数高度柱,高度对应x轴
ax1.fill_betweenx(np.arange(y_lower, y_upper),
0, ith_cluster_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
ax1.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
# 为下一个“刀片”预留出y轴上的空间
y_lower = y_upper + 10 # 10 for the 0 samples
ax1.set_title("各个簇的轮廓图")
ax1.set_xlabel("轮廓系数")
ax1.set_ylabel("簇类别")
# 设置一条竖直虚线,代表当前所有样本点的轮廓系数均值
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
# 绘制散点图,展示当前聚簇结果
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1], marker='.', s=30, lw=0, alpha=0.7,
c=colors, edgecolor='k')
# 聚簇类别标签
centers = clusterer.cluster_centers_
# 区别显示质心
ax2.scatter(centers[:, 0], centers[:, 1], marker='o',
c="white", alpha=1, s=200, edgecolor='k')
for i, c in enumerate(centers):
ax2.scatter(c[0], c[1], marker='$%d$' % i, alpha=1,
s=50, edgecolor='k')
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()实战:应用K-means进行图像压缩
应用K-means进行图像压缩的原理是基于聚类分析的思想,它将图像中的像素点分为不同的簇,然后使用聚类中心来表示每个簇,从而减小图像文件的大小。
简单而言,原先的图像有1024个像素点,假设每个像素点的颜色都各不相同,即需要存储1024种颜色。
应用K-means算法,把这n种颜色划分为16个簇,用每个簇的质心的颜色信息代替属于该簇的所有像素点的颜色信息,因此只需要存储16种颜色,这样就达到减少信息量的效果。
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from sklearn.cluster import KMeans
original_img = plt.imread('test.jpg')
# 对RGB图片进行归一化处理,加速模型收敛
original_img = original_img / 255
# 把(n,m,3)的3维矩阵展开成(n*m,3)形状的2维矩阵,方便计算
numpy_img = np.reshape(numpy_img, (numpy_img.shape[0] * numpy_img.shape[1], 3))
# 设定K值,代表以K种颜色代替原先所有像素点,以达到压缩图片的效果
K = 16
# 执行k-mean算法
kmeans = KMeans(n_clusters=K).fit(numpy_img)
# 获取质心的值,为(16,3)的数组,代表算出来的16种代表颜色
centroids = kmeans.cluster_centers_
# 此处获取索引,结果如[ 9 9 9 ... 5 5 11],代表了原先所有像素点经过压缩后属于centroids当中哪一个质心,为(numpy_img.shape[0] * numpy_img.shape[1], )的数组
idx = kmeans.labels_
# 把原图数据修改为压缩后的16种颜色
for i in range(K):
numpy_img[idx==i,:] = centroids[i]
# 还原3维矩阵
img_recover = numpy_img.reshape(original_img.shape[0],original_img.shape[1], 3)
fig, ax = plt.subplots(1,2, figsize=(8,8))
plt.axis('off')
# 原图
ax[0].imshow(original_img)
ax[0].set_title('Original')
ax[0].set_axis_off()
# 压缩后的图
ax[1].imshow(img_recover)
ax[1].set_title('Compressed')
ax[1].set_axis_off()
fig.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









