



文章推荐了DataWhale开源的从NLP到大语言模型的全栈教程,分为理论、实战、微调量化和应用部署四部分。教程从NLP基础开始,逐步深入到Transformer架构和预训练模型,通过文本分类和命名实体识别等实战项目巩固知识,最后讲解微调技术和模型部署方法。该教程全面系统,适合新手快速构建大模型知识框架,为进入50W+薪资的大模型算法岗位做准备。
前排提示,文末有大模型AGI-优快云独家资料包哦!
今年的秋招大模型算法岗位也是非常火热,基本上大厂都开出了总包50w+的算法,大模型在未来几年将会有很多落地的场景和应用,大有可为
很多刚开始学习大模型的同学,可能会感到迷茫,因为大模型确实比机器学习和深度学习更加复杂,特别是会出现很多新的专有名词,比如大模型幻觉,模型微调等
这一期主要是给大家推荐datawhale开源的从NLP到大语言模型教程,内容非常全面,适合新手小白全面系统学习,有助于快速构建起大模型的框架
下面具体来介绍一下这个教程:
第一部分:理论篇

这一部分从NLP开始,介绍NLP是解决什么问题,然后介绍NLP中的文本表示和词向量,NLP的第一步就是要把文本转换成向量,不同的转换方法效果差别很大,而且影响后续的建模
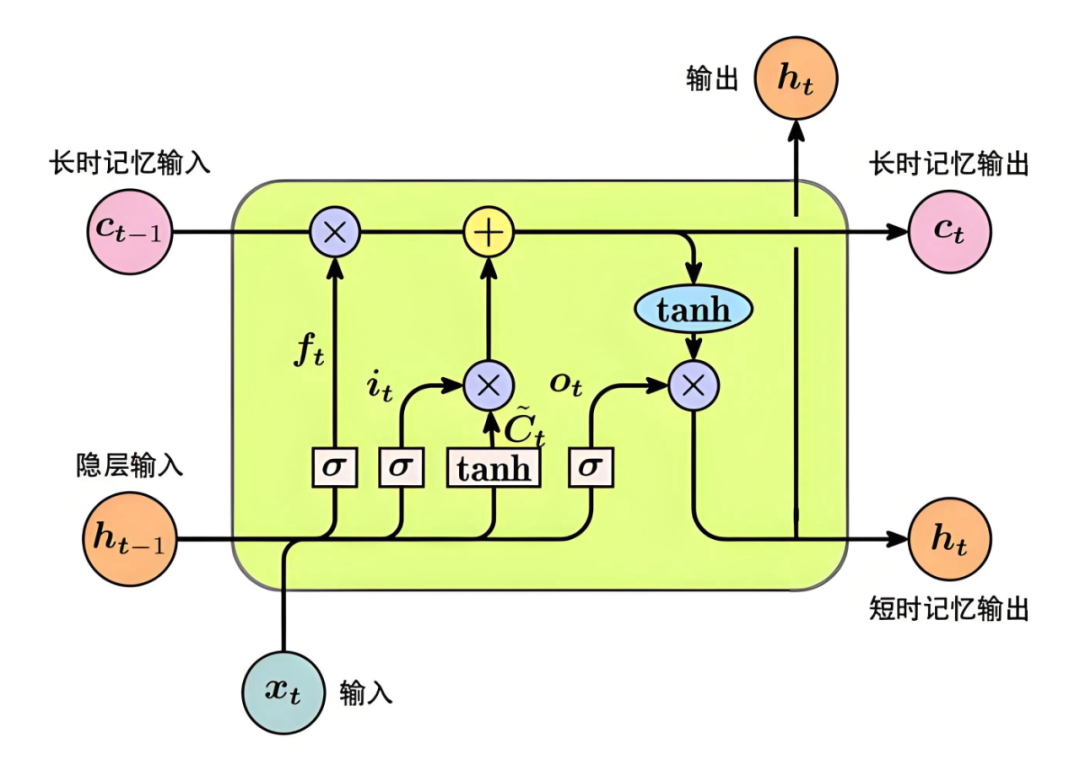
然后介绍一些可以应用于NLP时间序列建模的方法,比如循环神经网络,注意力机制和Transformer模型,在早起NLP的主流方法确实是RNN,现在主要还是Transformer的变体
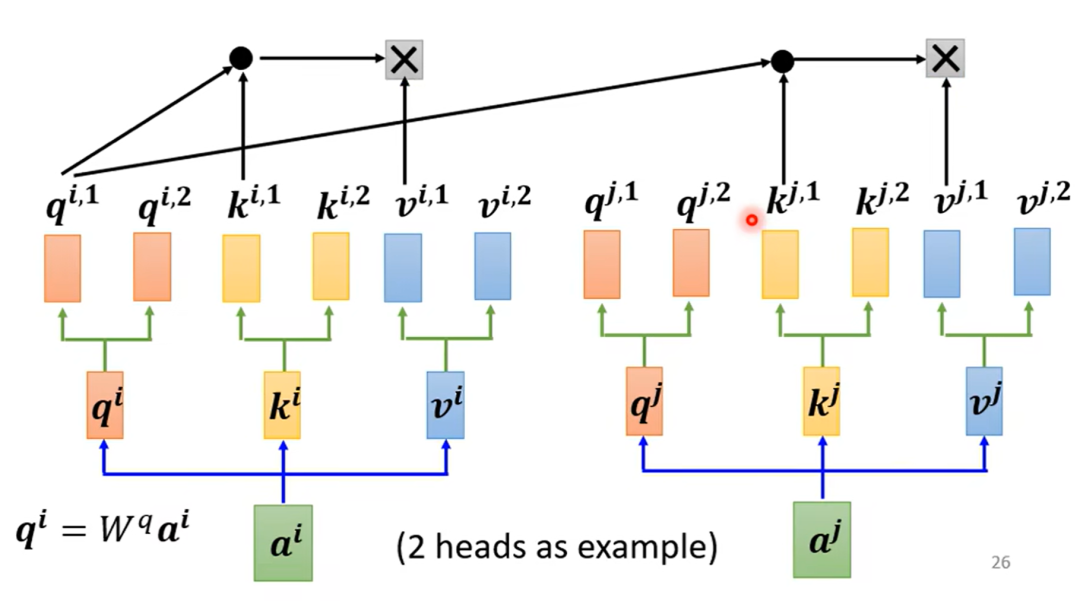
最后介绍一些预训练的大模型,比如Bert和GPT,T5分别代表不同的框架,还有最新的MOE框架介绍,学完这一部分就串完了大部分NLP和大模型的知识,当然这里可能会有点泛泛而谈,但是对于新手小白来说是有助于构建整体框架的,有个总体概念很重要
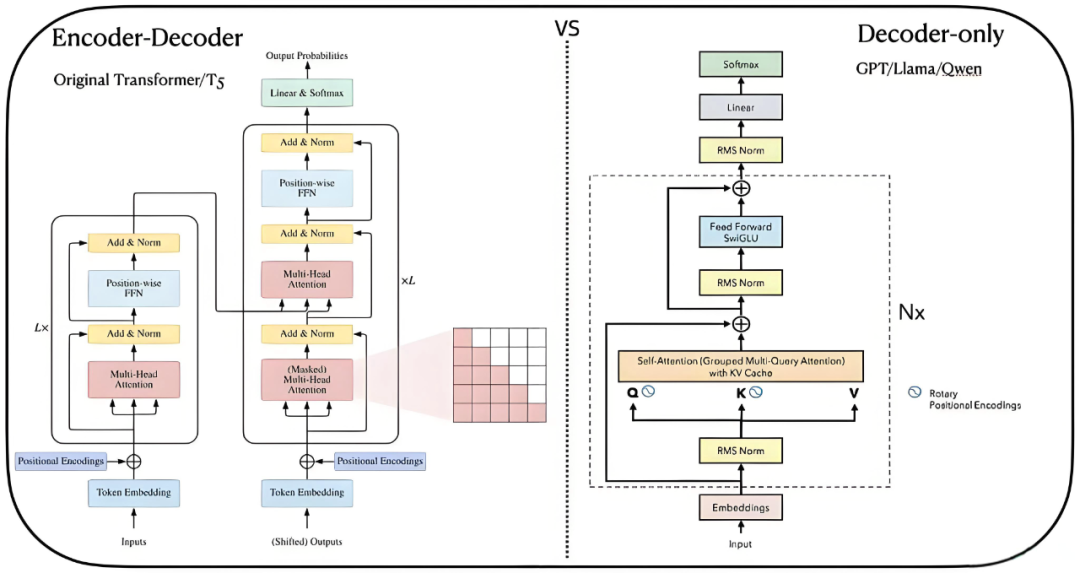
第二部分:实战篇

学完上面的理论知识,就可以找一些案例来进行实战,在实战中看看不同模型的效果。首先是文本分类任务,文本分类像朴素贝叶斯这种简单的机器学习算法就能实现,后续发展是用LSTM等模型来做的,现在是用BERT等大模型来做,对比一下不同算法模型的区别
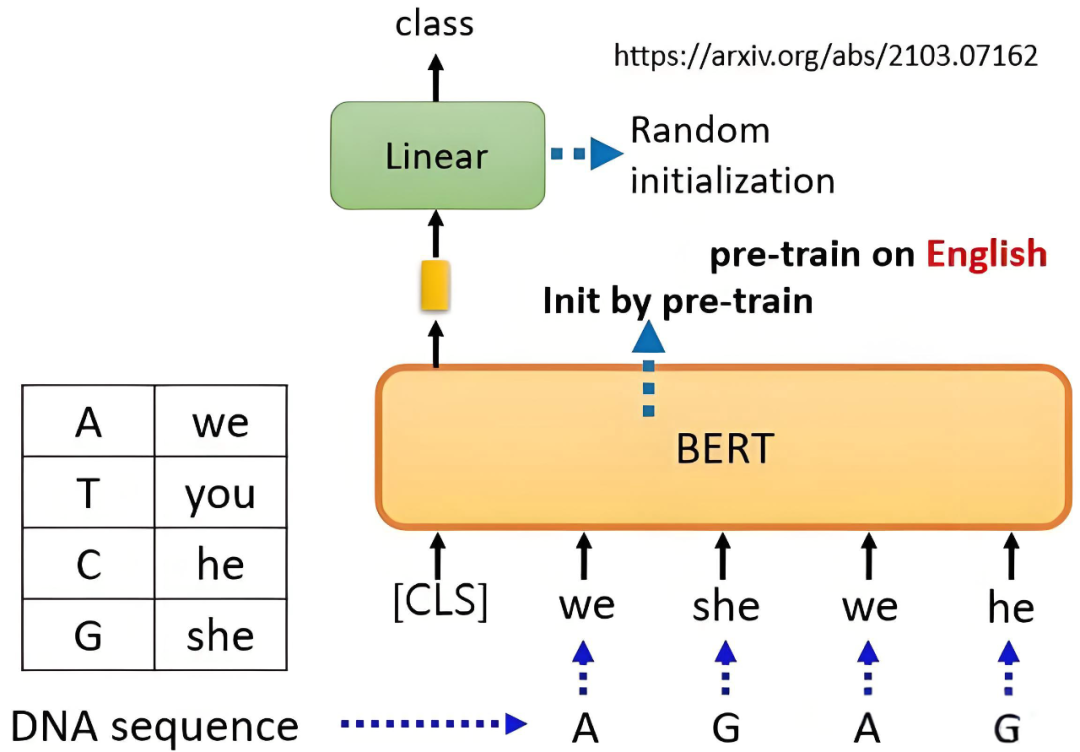
第二个实战项目是命名实体识别,这个也是NLP中的重点实战项目,重点掌握NER任务的数据处理,模型构建,训练和推理流程
第三部分:微调量化篇

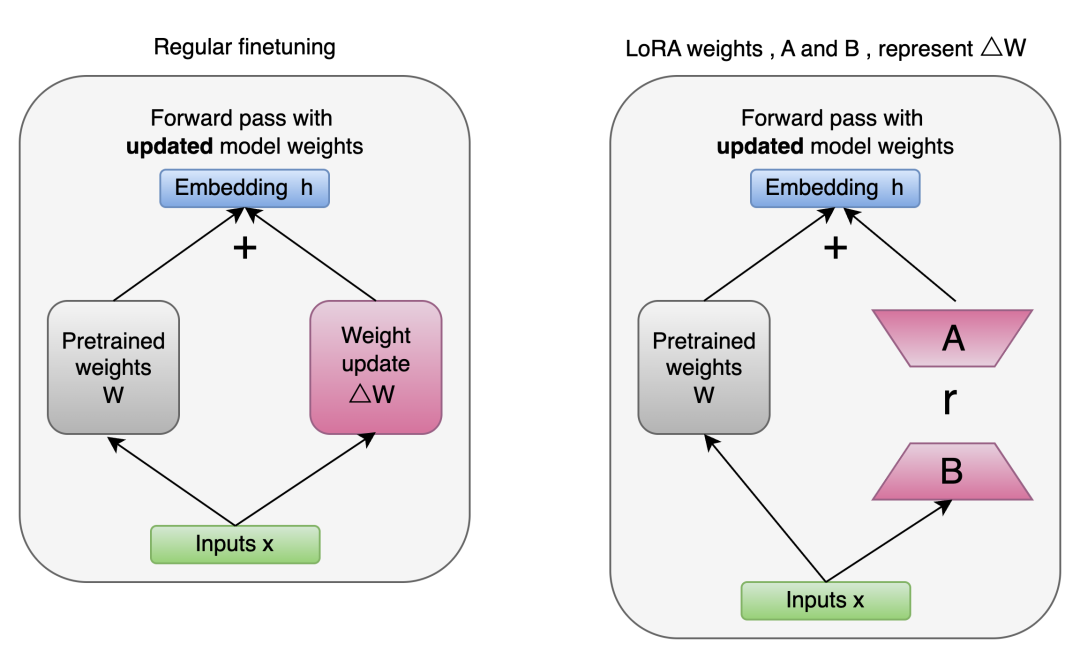
大模型在预训练之后,想要在特定的任务上发挥出更好的性能,那就需要进行参数微调,微调分为高效参数微调和全参微调,全参微调成本太高,一般情况下不考虑。高效参数微调中Lora微调是工业界常用的方法,这个在面试中经常会问到具体的原理
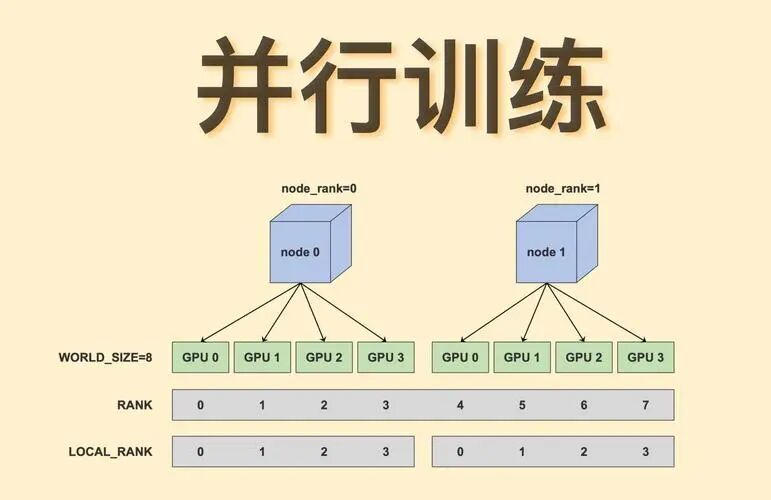
此外在监督微调之后,有可能还会进行RLHF,使得模型回答得更好,最后是采用Deepspeed框架进行模型并行计算以及一些量化技巧
第四部分:应用部署篇

大模型刚刚火起来的时候,很多人都在看一些教程如何本地部署DeepSeek-R1等模型,部署大模型是比较繁琐的,需要准备相应的环境,可以采用FastAPI,云服务器或者Docker等途径部署
优快云独家福利
最后,感谢每一个认真阅读我文章的人,礼尚往来总是要有的,下面资料虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:


















 3782
3782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









