







Dataframe创建
- 由数组/list组成的字典
data1 = {'a':[1,2,3],
'b':[3,4,5],
'c':[5,6,7]}
df1 = pd.DataFrame(data1)
print(df1)
- 输出
a b c
0 1 3 5
1 2 4 6
2 3 5 7
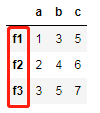
- 添加索引
df1 = pd.DataFrame(data1,index = ['f1','f2','f3'])
2. 由Series组成的字典
data1 = {'one':pd.Series(np.random.rand(2)),
'two':pd.Series(np.random.rand(3))} # 没有设置index的Series
df1 = pd.DataFrame(data1,index = ['a','b','c'])
print(df1)
较短的序列补0
one two
a 0.065605 0.217466
b 0.973106 0.908904
c NaN 0.663079
- 通过二维数组直接创建
ar = np.random.rand(9).reshape(3,3)
print(ar)
df1 = pd.DataFrame(ar)
df2 = pd.DataFrame(ar, index = ['a', 'b', 'c'], columns = ['one','two','three'])
0 1 2
0 0.339401 0.773847 0.253083
1 0.281513 0.028760 0.751607
2 0.347467 0.252451 0.689796
one two three
a 0.339401 0.773847 0.253083
b 0.281513 0.028760 0.751607
c 0.347467 0.252451 0.689796
Dataframe索引与切片
列索引和行索引
df
a b c d
one 94.473099 30.077407 70.953102 9.416436
two 41.958628 15.709462 47.400670 56.909647
three 14.539075 8.398997 80.139084 83.250374
1. 列索引
按照列名选择列,只选择一列输出Series,选择多列输出Dataframe
data1 = df['a']
data2 = df[['a','c']]
data1 = df['a']
one 94.473099
two 41.958628
three 14.539075
Name: a, dtype: float64 <class 'pandas.core.series.Series'>
data2 = df[['a','c']]
a c
one 94.473099 70.953102
two 41.958628 47.400670
three 14.539075 80.139084 <class 'pandas.core.frame.DataFrame'>
2. 行索引
按照index选择行,只选择一行输出Series,选择多行输出Dataframe
df.loc['one'] – 按标签索引
df.iloc[0] – 按位置索引
data3 = df.loc['one']#单标签索引
data4 = df.loc[['one','two']]#逐个选择--多标签索引
data5 = df.loc['one':'three']#范围--切片索引
data3
a 94.473099
b 30.077407
c 70.953102
d 9.416436
Name: one, dtype: float64 <class 'pandas.core.series.Series'>
data4
a b c d
one 94.473099 30.077407 70.953102 9.416436
two 41.958628 15.709462 47.400670 56.909647 <class 'pandas.core.frame.DataFrame'>
data5
a b c d
one 94.473099 30.077407 70.953102 9.416436
two 41.958628 15.709462 47.400670 56.909647
-
df.iloc[]- 按照整数位置做行索引- 单位置索引
df.iloc[0]———与df.loc['one']相同 - 多位置索引
df.iloc[[2,1]]———与df.loc['three','two']相同 - 切片索引
df.iloc[0:2]———与df.loc['one':'three']相同
- 单位置索引
3. 布尔型索引
df
a b c d
one 52.462365 92.336489 95.512607 85.587735
two 34.853185 12.887189 69.575950 79.705655
three 90.755125 98.826032 12.686749 99.404063
four 75.758254 97.520349 36.782117 18.956917
- 布尔型矩阵索引
b1 = df < 20得到与df同型的矩阵
a b c d
one False False False False
two False True False False
three False False True False
four False False False True
通过布尔型矩阵索引df[b1],False处的值为NaN,True的为相应值
a b c d
one NaN NaN NaN NaN
two NaN 12.887189 NaN NaN
three NaN NaN 12.686749 NaN
four NaN NaN NaN 18.956917
- 布尔型序列/行索引
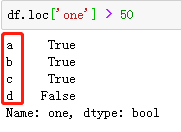
b2 = df['a'] > 50,得到布尔型序列
one True
two False
three True
four True
Name: a, dtype: bool <class 'pandas.core.series.Series'>
df[b2]
布尔型序列索引,得到的是布尔型序列为true所在的行
a b c d
one 52.462365 92.336489 95.512607 85.587735
three 90.755125 98.826032 12.686749 99.404063
four 75.758254 97.520349 36.782117 18.956917
不能通过相似的方法对行进行判断。列得到的是列名,与原始的DataFrame的index['one','two','three','four'],无法匹配
错误提示Boolean Series key will be reindexed to match DataFrame index.
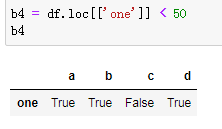
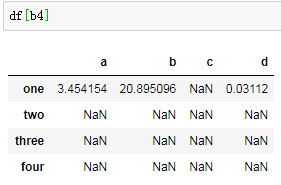
通过行索引方式为。df在行索引为真时,为原始值,其余地方为NaN
多列索引和多行索引
b3 = df[['a','b']] > 50 #两列
a b
one True True
two False False
three True True
four True True <class 'pandas.core.frame.DataFrame'>
df[b3] 布尔型DataFrame中为True的地方有值,其余的均为NaN.多行索引也是同样的效果
a b c d
one 52.462365 92.336489 NaN NaN
two NaN NaN NaN NaN
three 90.755125 98.826032 NaN NaN
four 75.758254 97.520349 NaN NaN
- 多重索引:比如同时索引行和列
df['a'].loc[['one','three']]
one 52.462365
three 90.755125
Name: a, dtype: float64
print(df[['b','c','d']].iloc[::2]) # 选择b,c,d列的one,three行
b c d
one 92.336489 95.512607 85.587735
three 98.826032 12.686749 99.404063

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









