




 本文介绍了二叉树的基本概念,包括前序、中序和后序遍历。详细讲解了LeetCode上的#144二叉树前序遍历和#94二叉树中序遍历问题,提供了迭代和递归两种解题思路,并分析了两种方法的运行时间。在实现过程中,特别强调了迭代解法中栈的使用和处理特殊情况的技巧。
本文介绍了二叉树的基本概念,包括前序、中序和后序遍历。详细讲解了LeetCode上的#144二叉树前序遍历和#94二叉树中序遍历问题,提供了迭代和递归两种解题思路,并分析了两种方法的运行时间。在实现过程中,特别强调了迭代解法中栈的使用和处理特殊情况的技巧。
基本概念:
Pre-Order Traversal: Root -> Left -> Right
In-Order Traversal: Left -> Root -> Right (常用语二分查找)
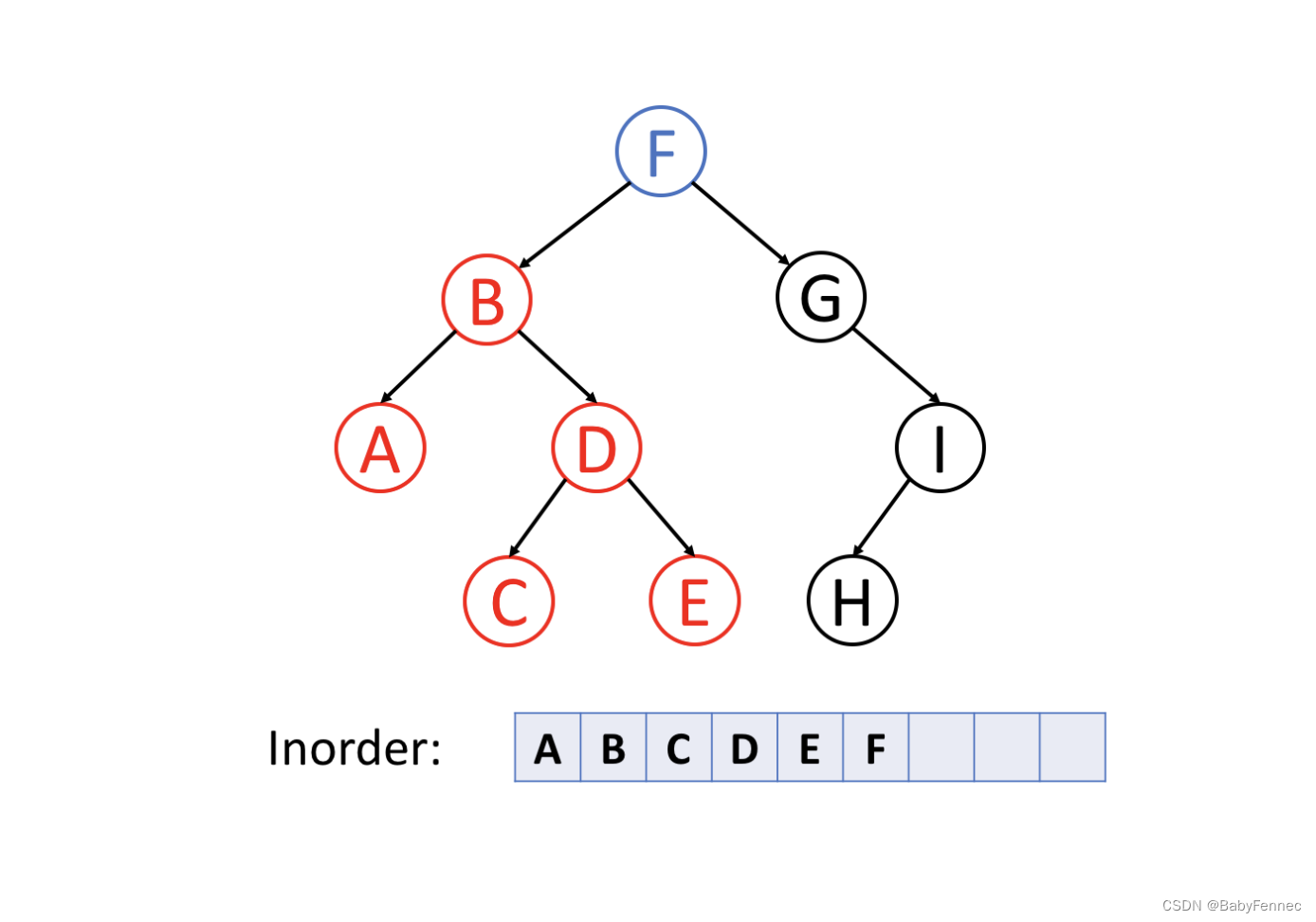
这个F之后的顺序是literally的先左后中,就看pointer的方向。
Post-Order Traversal: Left -> Right -> Root (常用于删除节点,以及数学运算)

Recursive or Iterative:尝试每题都用两种思维解决
#144 Binary Tree Preorder Traversal
Given the
rootof a binary tree, return the preorder traversal of its nodes' values.
解题思路:
借用stack的特点,last in first out. 存完root节点的信息,往后跟着从stack里pop出来的left node,如果有的话,再是right node.
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
out = []
stack = [root]
while stack:
node = stack.pop()
if node:
out.append(node.val)
stack.append(node.right)
stack.append(node.left)
return out
runtime:

看了15,16ms的解法也是用的stack。So下一题:
#94 Binary Tree Inorder Traversal
Given the
rootof a binary tree, return the inorder traversal of its nodes' values.Example 1:

解题思路:
iterative思路
更符合思路直觉,虽然写起来很复杂。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
if not root:
return root
res = stack = []
while True:
while root.left: # reach the deepest left node
stack.append(root)
root = root.left
res.append(root.val) # output left node first
root = stack.pop() # move back to the parent node
while root:
res.append(root.val) # output root node
if root.right:
root = root.right # move to the right node if it has one
break # to see if it has left node
else:
root = stack.pop() # move back to the upper parent node
return res
很奇怪的是,报错了。

说root是int object,没有attribute val。
改了res, stack = [], []之后。报错才消失。所以是我没有搞明白res = stack = [] 和 res, stack = [], []的区别。研究了一下,前者是不同的变量指向同一个对象。任意一个变,另外一个也跟着变。后者指向不同的对象,所以不会影响。
但改了之后,我之前的方法还存在一个问题,就是当stack为空集的时候,无法.pop()。没有考虑stack没了之后的情况。所以必须把stack存在这个条件放进循环条件里。

参考了Neetcode频道的解法,才发现stack那一步还是要先于判断左节点在不在,不在也要现存。看似短期多了一步先存再看左节点有没有,实则长期逻辑更为统一和简单,因为把左节点和母节点的stack.pop()和res.append()都合为一步处理了。
另外排除root是空集那一步也是多余。可以不用。root不存在,直接返回res空list。
最后离开循环的终止条件是无右节点也无母节点。

重新写了一遍。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
res, stack = [], []
while root or stack:
while root: # reach the deepest left node
stack.append(root)
root = root.left
root = stack.pop()
res.append(root.val) # output left node first
root = root.right # move to the right node if it has one
return res
runtime:

recursive思路
属于自己想不到系列……
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
res = []
def inorder(root):
if not root: return
inorder(root.left)
res.append(root.val)
inorder(root.right)
return res
inorder(root)
return res
runtime:

应该是recursive这里还缺基本功,但暂时不知道要补什么方面的功课。先走着。

















 3468
3468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









