



百趣代谢组学资讯:代谢组学(Metabonomics/Metabolomics)是继基因组学和蛋白质组学之后发展起来的新兴的组学技术,是系统生物学的重要组成部分,研究对象大都是相对分子质量1000以内的小分子物质。
代谢组学是对某一生物体组份或细胞在一特定生理时期或条件下所有代谢产物同时进行定性和定量分析,以寻找出目标差异代谢物。可用于疾病早期诊断、药物靶点发现、疾病机理研究及疾病诊断等。
国内外研究现状简述
国际上,代谢组学研究很活跃:美国国家健康研究所(NIH)在国家生物技术发展的路线图计划中制订了代谢组学的发展规划;许多国家的科研单位和公司均开始了代谢组学相关研究及业务,如英国帝国理工大学的Jeremy Nicholson实验室、美国加州大学Davis分校的Oliver Fiehn 实验室、美国Scripps实验室、荷兰莱顿大学的Jan van der Greef实验室等。其中许多机构已经开始了多组学整合研究工作。
国内多家科研机构已先后开展了代谢组学的研究工作,包括中国科学院大连化学物理研究所许国旺实验室、中国科学院武汉数学物理研究所唐惠儒实验室、上海交通大学贾伟实验室、军科院等。
没有任何一个分析技术能够同时分析代谢组中的所有化合物,只能通过选择性地提取结合各种分析技术的并行分析来解决。
样品之间的变异、仪器动力学范围的局限和分析误差的存在也给代谢组学分析带来巨大的挑战。因此在取样方法,新型分析仪器和分析技术的研发等方面,都需要进一步深入开发。
代谢组学分析产生出海量的数据,当前我们缺乏适当的代谢组数据库和数据交换版式,需要完善代谢组学数据库,建立代谢产物数据的标准,并且需要开发功能强大的数据分析工具。
代谢组学服务简介
上海阿趣生物科技有限公司(简称阿趣生物)成立于2012年3月,是一家专业提供生命科学前沿研究技术应用、咨询及开发的高新技术企业,是上海百趣生物医学科技有限公司(简称百趣生物)旗下全资子公司。

公司致力于大生命科学领域样本检测、大数据分析以及技术产品开发,承诺以客户为中心,提供专业的服务!公司愿景是成为大生命科学领域权威的检测分析服务机构。

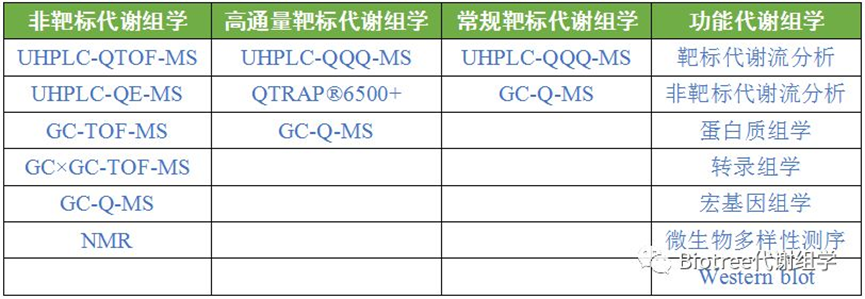
经过多年发展,公司已经建立并完善了包括非靶标代谢组、高通量靶标代谢组、常规靶标、脂质组学、代谢流检测等研究平台。
1非靶标代谢组学
经过多年发展,BIOTREE现已拥有完善的非靶标代谢组学平台,包括 UHPLC-QTOFMS、Orbitrap LC-MS、GC-TOF-MS、GC-Q-MS 等,能够准确、快速地分析各种生物样本(血、尿、动物组织、唾液、羊水、细胞和细胞液、植物、微生物等)中的小分子代谢物。最大程度反映生命体对外界刺激、病理生理变化、以及本身基因突变产生的代谢物水平的多元动态反应。为疾病诊断、病理研究、新药开发、药物毒理学、中医药现代化、食品营养、农林、环境毒理等研究提供新的探索视角。具体产品包括:
-
GC-MS非靶标代谢组学
-
LC-MS非靶标代谢组学
-
经典脂质组学
-
定量脂质组学
-
VOCs非靶标代谢组学
-
土壤代谢组学
-
中药非靶标代谢组学
-
肠道菌群非靶标代谢组学
2高通量靶标代谢组学
高通量靶标代谢组学整合了非靶标代谢组学和靶标代谢组学的技术优点,创造性实现了高通量、高灵敏度靶向代谢物检测,为定性、定量检测大批量、低丰度代谢物提供了高效的方法。高通量靶标代谢组学可分为高通量靶标定量和广泛靶标两种平台,该平台可以对不同结构的代谢产物或者不同功能途径中的代谢产物进行准确定性和精确定量。具体产品包括:
-
氨基酸高通量靶标定量
-
短链脂肪酸高通量靶标定量
-
游离脂肪酸高通量靶标定量
-
中心碳代谢高通量靶标定量
-
神经递质高通量靶标定量
-
全氟化合物高通量靶标定量
-
单、双糖高通量靶标定量
-
植物激素高通量靶标定量
-
多胺及其合成通路物质高通量靶标定量
-
胆汁酸高通量靶标定量
-
有机酸高通量靶标定量
-
维生素高通量靶标定量
-
动物激素高通量靶标定量
-
氧化三甲胺及相关代谢物高通量靶标定量
-
类胡萝卜素高通量靶标定量
-
动物广泛靶标代谢组
-
植物广泛靶标代谢组
-
类黄酮广泛靶标
-
花青素广泛靶标
3靶标代谢组学
靶标代谢组学是对样本中特定关注的物质进行绝对定量分析,具有高灵敏度、高特异性等特点。靶标代谢组学是对非靶标代谢组学的延伸与验证,应用前景非常广阔。针对客户提供的目标物质,用MRM的方法进行定量分析,需要提供标准品(可代购)。具体产品为:
-
MRM靶标定量
4功能代谢组学
功能代谢组学是在传统的以发现差异代谢物为主要目的的非靶标、靶标代谢组学基础上,综合结合分子细胞生物学实验、同位素标记、宏基因组、转录组和蛋白组等多种技术手段,探究差异代谢物的生物功能以及相关生理病理意义的一种新方法,是传统代谢组学概念的深化和延伸。具体产品包括:
-
靶标代谢流分析
-
非靶标代谢流分析
-
蛋白质组学
-
转录组学
-
宏基因组学
-
微生物多样性测序
-
Western blot
文/阿趣代谢组学


















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









