 张祥雨:ResNet的诞生与深度学习突破
张祥雨:ResNet的诞生与深度学习突破





ResNet怎么想出来的
参考一:张祥雨介绍文章
交通大学官方2021年发的:【校友建功立业风采】张祥雨:3年看1800篇论文,28岁掌舵旷视基础模型研究
原文链接:孙剑首个深度学习博士张祥雨:3年看1800篇论文,28岁掌舵旷视基础模型研究
以下文字摘取自文章的两部分内容:
- ResNet的诞生,
- “何张任”组合决心跟大厂们硬刚一下
在完成这份code以后,孙剑就把何恺明、任少卿、张祥雨拉到一起做深度学习,在组队之前,何恺明做了图像重建和哈希计算,任少卿做人脸。
经过一年的磨合,“何张任”组合在孙剑的带领下小有所成,ECCV、TPAMI等国际视觉会议的论文中开始出现这三个二十多岁中国人的名字。这几位年轻人真正爆发是在2015年。当时包括谷歌、百度在内的大厂都在参加ImageNet大规模视觉识别挑战赛,当时人类识别图像正确分类的误差率为5.1%,谁能打破5.1%,就代表在这一领域机器超越了人类,而2014年最好的成绩是6.67%,由谷歌创造,但依旧没能实现5.1%,百度也积极尝试,试图第一个打破5.1%。
事实证明,想要突破大厂们都还没打破的记录并非易事。主要是由于神经网络想提升能力就得持续加深,但一加深就不收敛,导致实验结果很不理想。
有一天,张祥雨突然意识到收敛的问题跟梯度消失有关系,如果做一些独立性假设的话,是可以推出一套参数初始化的法则,让梯度消失的问题解决。因此他推导出一组公式,后来在微软内部命名为“xiangyu初始化法”。
接着,“何张任”组合又引入一种新的修正线性单元(ReLU),将其称为参数化修正线性单元(PReLU),并且通过对修正线性单元的非线性特征进行直接建模,推导出一种符合理论的初始化方法,并直接从头开始训练网络,将其应用于深度模型的收敛过程。

这种方法应用到比赛之后结果出炉:错误率已降低至4.94%,超越人类!不过,张祥雨认为,打破记录确实可以长点脸,但是并不足以证明AI直接超过了人类。他们发现,挑战到了后面就完全变成了一个工程问题,成了怎么用有限的资源训练起来更大的网络。
“其实我个人是非常不满意的,因为虽然打败了人类,但更多是一个噱头,我们也知道这些方法并不很work,主要是靠调参和堆模型。”张祥雨说。
张祥雨又重新复盘,他发现2014年的ImageNet冠军谷歌GoogLeNet只用了一点几个G的复杂度就实现了非常高的准确度,他认为GoogLeNet可能是其他几个模型的必经之路。

经过几个月的研究,张祥雨发现,GoogLeNet最本质的是它那条1x1的shortcut。“说白了,可以把它简化到最简单,可以发现GoogLeNet只有两条路,一条是1×1,另一条路是一1x1和一个3x3”。
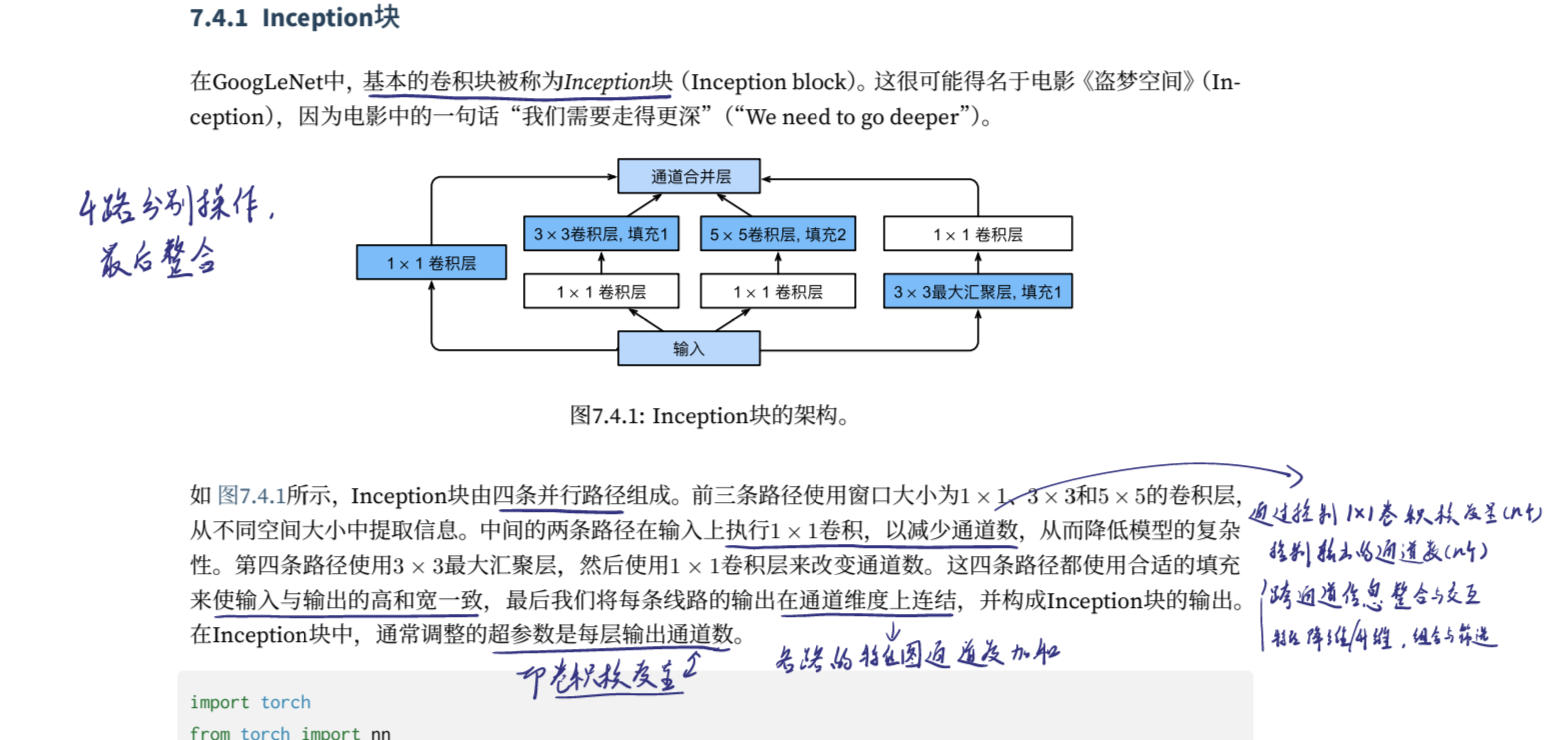
图出自《动手学深度学习》
到底是什么在很低的复杂度上支撑起了GoogLeNet这么高的性能?张祥雨猜想,它的性能由它的深度决定,为了让GoogLeNet 22层的网络也能够成功地训练起来,它必须得有一条足够短的直路。
基于这个思路,张祥雨开始设计一个模型,利用一个构造单元不断的往上分,虽然模型结构的会非常复杂,但是不管怎么复杂,它永远有一条路,但深度可以非常深。“我认为这种结构就可以保持足够的精度,同时也非常好训练,我把这个网络称为分形网。”
张祥雨把分形网的成果跟何恺明商量,何恺明的意见是:结构还是过于复杂。“复杂的东西往往得不到本质”,何恺明一语中的,并建议进一步对这个模型进行化解,用它的一个简化形式。
于是张祥雨又延伸之前的假设:最短的路,决定容易优化的程度;最长的路,决定模型的能力,因此能不能把最短路尽可能的短,短到层数为零?把最深的路,无限的变深?
基于这个思路,诞生了ResNet,有一条路没有任何参数,可以认为层数是0。
参考二:微软亚洲研究院的圆桌论坛
知乎文章:视觉顶会最佳论文得主圆桌论坛(完整文字版),这里张祥雨分享了 ResNet 背后的故事。
CCF计算机视觉专委会,B站视频:视觉顶会最佳论文得主圆桌论坛:好论文是怎么炼成的
张祥雨:ResNet是我14年到微软实习,在孙剑和何恺明老师指导下做出来的。其实我当时刚去微软的时候并没有接触过AI,因为我本科是软件工程专业的,主要是做软件设计,而当时孙老师招我去的主要原因也是因为我会写CUDA。但是做了一年后,就开始很有兴趣了,而且做深度学习正好可以发挥我的特长,就是工程能力比较好,idea也比较多。在这一年里,我做了一个名叫Spatial Pyramid Pooling (SPP)的工作,以及一个模型化简相关的工作。
时间来到14年7月,在当年的ImageNet比赛中Google和VGG分别获得了第一名和第二名。然后我们就想能不能从这里面挖掘一些insight。尤其是当时我们有一个很重要的想法,就是想着怎么把网络做深,因为从直观上来说,深度学习是基于函数复合的形式,当复合的层数越多,效果应该就越好。但是我们前期的一些实践表明,加深这一件事是非常困难的。尤其是VGG之前的plain network,当把层数加到7层、8层左右就会遇到非常严重的收敛性问题。一开始我们并不清楚是怎么回事。直到有一天我突然意识到这可能是出现了梯度消失这种情况,然后我给出了一个初始化方案,让梯度信号的幅值不至于逐层衰减。现在大家一般把这个初始化叫Kaiming初始化(有趣的是这个方法其实是我提的,当时在微软的时候我们内部其实叫Xiangyu初始化)。有了这个初始化以后,我们发现很多事情都得以解决,并成功将网络做到了十几层。
但是随着网络进一步加深,我们又遇到了新的问题:这时候网络收敛已经看上去没有任何问题了,但出现了严重的欠拟合(underfit)情况,这是非同寻常的。因为我们知道增加层数一般意味着增加参数,而传统的理论认为加参数会更容易导致过拟合(overfit)而不是欠拟合。那这个问题要怎么解决呢?于是我们就开始把视角转到GoogleNet。当时GoogleNet拿了第一,但是因为训练技巧特别复杂,学术界大多数人并不愿意follow。但是我们却发现了一个非常有趣的现象:虽然GoogleNet的参数量和计算量都远小于当时的VGG,但是它的精度并不比VGG低,甚至收敛更快,也能支持更多的层。这件事在我们看来是非同寻常的,我花了很长时间去研究,发现其实它真正work的不是论文里讲的多尺度,而是它始终有一条1x1的卷积分支,就是这个分支,按今天的话讲起到了shortcut的作用,从而让它的优化变得更容易。
虽然发现了这个shortcut非常有用,但是我一时也没想通这个shortcut该如何用于构建新的网络结构。于是,何恺明老师就建议能不能把这个工作再简化一些。其实当时我的第一个想法是设计一个更复杂、更fancy的结构,并搞出了一个叫“分形网络”的结构,性能还不错。但是何老师和我说,“你做这么多,结果还是一个Fancy的东西,还是得不到背后最本质的东西。你要么在理论上把它解释清楚,要么你就干脆放弃解释,用一个最基础、最本质的结构让它work,把解释这件事留给后人”,这给了我非常大的启发。于是,我们就尝试沿着这个方向去做,最后发现其实shortcut那条路甚至于可以不使用那个1x1的卷积,直接使用一个无参数的identity都是可以work的。当时ResNet最早的版本中identity不是加法而是concat,但是后来我们想了一下,其实concat和加法并没有本质的区别。所以最终采用identity+residual的设计方案。
最后我们得到了ResNet,它结构简单,扩展性强,调参也更容易,实验结果也非常好,并在当年的ImageNet图像分类、COCO检测和分割等赛道上均拿到了第一名。而今天ResNet无论在思想还是在应用上都得到了非常广泛的传播和使用。
不过当时我们刚做完这个工作的时候,其实还是有些不满意的,因为只是提出了一个方法,但是对于ResNet本身的理解和解释,当时我们是一点头绪都没有。之后我们继续做了一些关于ResNet理解方面的探索,比如我当时认为ResNet可能是促进了层之间正交的性质,因为根据随机矩阵理论,乘的越多,矩阵的条件数越大,最大特征值和最小特征值差距越来越大,不利于优化;而通过identity分支的引入,减少了矩阵的条件数,提高了收敛速度。
受此启发我们也做了一些将正交性引入plain network的尝试,也确实有一定效果,但依旧无法解释为什么ResNet能做到成百上千层。后来我们做了Preactivation的ResNet,经验性地发现将identity支路变得更通畅,可以进一步提升ResNet的性能,并且观察到训练过程中ResNet有效层数是不断增加的。这一效应在后续的工作中也陆续有人给出了解释,比如认为是BN和Shortcut的联合作用导致了有效层数的变化。关于ResNet我们还看到一些解释,例如有人将ResNet解释成一些浅层网络的ensemble,还有人从鞍点的分布以及loss landscape的平滑性来解释ResNet的易收敛性,但一直总还差点意思。
直到今天依然还有很多学者在关注这个课题,也提出了一些有趣的视角,例如Neural ODE把ResNet连续化来建模微分方程;再例如我非常喜欢的一个工作是马毅老师的MCR^2,这篇文章从信息压缩的角度去理解特征的学习,进一步通过ReduNet把这个过程用梯度下降展开,自然就得到了ResNet的形式,按马老师的话就是“这个是由不得你的,数学上就是这样”,我觉得特别有insight。关于ResNet的理解和改进至今仍在继续,我们最新的工作RepVGG和RepOPT就表明,架构和优化其实是相辅相成的,控制架构不变,通过修改优化过程,同样可能取得修改架构才能达到的效果,例如能使VGG-like的plain结构达到ResNet才有的性能。
ResNet二作:张祥雨

张祥雨是人工智能计算机视觉(CV)领域的杰出人才,现任旷视研究院base model组负责人、旷视首席科学家,也是西安交通大学人工智能学院兼职教授。
张祥雨2012年毕业于西安交通大学软件学院软件工程专业,获学士学位,之后在西安交通大学与微软亚洲研究院控制科学与工程专业学习,于2017年获得博士学位。在学期间,他曾拿下美国大学生数学建模竞赛(MCM)特等奖提名奖,凭借此获奖经历获得微软亚洲研究院实习资格,并最终成功留下。
他的主要研究方向包括深度卷积网络设计、深度模型的裁剪与加速、AutoML与自动化神经网络架构搜索等。张祥雨在CVPR、ICCV、ECCV、NeurIPS、TPAMI等顶级会议和期刊上发表论文60余篇,Google Scholar总计引用数超过20万次,单篇引用超过2万次,并获CVPR 2016最佳论文奖。
其代表作包括世界上第一个上百层的深度神经网络深度残差网络ResNet、移动端高效卷积神经网络ShuffleNet v1/v2、服务器端高效神经网络RepVGG、神经网络架构搜索算法SPOS等,这些成果在业界得到广泛应用。2019年,张祥雨入选福布斯中国30岁以下精英榜,同年入选智源青年科学家,2020年3月入选“AI 2000计算机视觉全球最具影响力学者”榜单第4位,2023年获得未来科学大奖“数学与计算机科学奖”。
张祥雨的研究方向
张祥雨的研究方向主要包括以下几个方面:
- 深度卷积网络设计:探索设计更高效强大的卷积神经网络架构,其成果有知名的 ResNet、面向移动端的 ShuffleNet v1/v2、适用于服务器端的 RepVGG 等,能依不同硬件环境与任务需求,提供高性能网络模型。
- 深度模型的裁剪与加速:研究像 CP、MetaPruning 等模型压缩裁剪算法,以削减模型参数量、计算量及存储大小,减少资源消耗,加快运行速度,助力深度学习模型在资源受限设备上高效部署应用。
- AutoML 与自动化神经网络架构搜索:借自动化技术探寻优质神经网络架构,减少架构设计对人工经验的依赖。SPOS 算法就是其在此方向的研究成果,可提升架构设计效率与性能,挖掘适配特定任务的更优架构。
- 视觉大模型研究:近年其聚焦于大模型探索,团队于通用图像、计算摄影、视频理解、自动驾驶感知大模型等四个方向展开科研与应用开发。追求以“大且统一”的模型,借大数据及强算力应对多模态多视觉任务。
研究方向:自动化神经网络架构搜索
自动化神经网络架构搜索(Automated Neural Architecture Search,简称NAS),是一种通过算法自动设计神经网络结构的技术,核心是替代传统依赖人工经验试错的网络设计方式,以高效找到性能更优、适配特定任务(如图像分类、目标检测)或硬件(如手机、嵌入式设备)的网络架构。
其核心逻辑可拆解为3个关键模块,通过“循环迭代”实现架构优化:
- 搜索空间(Search Space):定义可选择的网络“积木”范围,比如卷积层类型(普通卷积/深度可分离卷积)、卷积核大小(3×3/5×5)、网络层数、激活函数种类等,是NAS的“设计素材库”。
- 搜索策略(Search Strategy):决定如何从“素材库”中筛选组合架构,常见策略包括:
- 强化学习:用强化学习智能体(Agent)生成架构,以模型在任务上的精度为“奖励”,逐步优化生成策略;
- 进化算法:模拟生物进化,通过“初始化架构种群→评估性能→选择优秀个体→交叉/变异产生新种群”的循环迭代,筛选最优架构;
- 梯度下降:将架构参数(如各层的通道数、卷积类型)转化为可微分变量,用梯度下降直接优化,效率更高(如Google的NASNet、旷视的SPOS)。
- 评估策略(Evaluation Strategy):快速判断生成的架构是否“有潜力”,避免对所有候选架构都进行完整训练(耗时耗资源)。常见方式包括“权重共享”(让多个候选架构共享部分网络权重,减少重复训练)、“小数据集预训练+性能预估”等。
简单来说,NAS相当于给神经网络配备了“自动设计师”:无需人工手动调整卷积层、层数等细节,算法会自主尝试不同组合,并根据任务目标(如更高精度、更快速度)筛选出最优方案,大幅降低了神经网络设计的门槛,同时能发现人工难以想到的高效架构(例如张祥雨团队提出的SPOS算法,就是通过NAS思路优化了网络架构搜索效率)。
论文汇总
可以在论文网站搜索:Xiangyu Zhang
-
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》 2014年
- 作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- 会议:European Conference on Computer Vision (ECCV) 2014
- 网址:https://arxiv.org/abs/1406.4729
- 简介:提出空间金字塔池化(SPP)技术,解决卷积神经网络(CNN)对固定输入尺寸的依赖,通过多尺度池化提取更丰富的特征,显著提升模型在图像分类和目标检测任务中的性能,为后续ResNet的发展奠定基础。
-
《Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification》 2015
- 作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- 预印本:arXiv 2015年2月
- 网址:https://arxiv.org/abs/1502.01852
- 简介:提出参数化修正线性单元(PReLU)和鲁棒初始化方法,首次在ImageNet图像分类任务上超越人类水平(Top-5错误率4.94%),推动深度学习在计算机视觉领域的突破。
-
《Deep Residual Learning for Image Recognition》
- 作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
- 网址:https://arxiv.org/pdf/1512.03385
- 简介:于 2016 年获 CVPR 最佳论文奖,张祥雨与何恺明、孙剑、任少卿等共同完成。其提出深度残差网络 ResNet,引入残差连接解决深层神经网络训练梯度消失或梯度爆炸问题,使训练超百层网络成为可能,引用量超 23 万次,是本世纪热门深度学习论文之一。
-
《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices》
- 网址:https://arxiv.org/pdf/1707.01083
- 简介:是张祥雨团队 2017 年发布的面向移动端的高效卷积神经网络。其通过提出逐点分组卷积及通道混洗操作,显著减少计算成本与参数量,在保证精度的同时,实现移动端设备的快速运行。
-
《ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design》
- 网址:https://arxiv.org/pdf/1807.11164
- 简介:作为 ShuffleNet 系列的第二篇论文,其从内存访问成本等实际硬件限制出发,提出一系列构建高效 CNN 架构的实用准则,并基于这些准则设计了 ShuffleNet V2,进一步提升了移动端卷积网络的运行效率与性能表现。
-
《RepVGG: Making VGG-style ConvNets Great Again》
- 网址:https://arxiv.org/pdf/2101.03697
- 简介:于 2021 年 CVPR 发表。其提出 RepVGG 卷积神经网络架构,借结构重参数化技术让训练阶段多分支结构,转化为推理时 3×3 卷积和 ReLU 组成的单路径架构。实验表明其 ImageNet 数据集 top-1 准确率超 80%,GPU 上比 ResNet 快 83%,兼具高精度与高推理速度。
-
《Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs》
- 网址:https://readpaper.com/paper/663530411408506880
- 简介:发布于 CVPR 2022。其重新探索大卷积核在 CNN 中的设计应用,总结五条设计准则,并基于此提出 RepLKNet,卷积核尺寸可达 31x31,其在特定任务上性能可比肩或超越 Swin Transformer,且推理速度更快。
-
《Understanding Masked Image Modeling via Learning Occlusion Invariant Feature》
- 网址:https://arxiv.org/pdf/2303.16900
- 简介:发布于 2023 年,探讨遮蔽图像模型(MIM)学习原理,研究表明 MAE 核心是学习遮挡变换不变特征,有助于预判 MIM 模型在不同下游任务的效果。
一些张祥雨的其他的分享
张祥雨有一些公开的采访、分享内容等,以下为你总结部分有代表性的信息:
- 张小珺 Jùn 商业访谈 102 期 | 对话张祥雨:播客发布于 2025 年 6 月,张祥雨作为阶跃星辰首席科学家,在其中探讨多模态大模型、视觉推理、自主学习和无限长上下文建模等内容。其提到 2024 年底开始尝试在视觉空间引入 CoT 做推理的尝试与相关不理想的结果,并分析了原因,还指出将 RL+CoT 成功应用至视觉领域可促成视觉的 GPT-4 时刻等。播客链接,也可参考其文字稿。
- MegTech 2022 旷视技术开放日分享:在 2022 年 7 月 15 日的旷视技术开放日上,当时身为旷视研究院基础科研负责人的张祥雨分享了旷视关于 AI 基础研究的最新趋势洞察和研究成果,其提出**“大”和“统一”已成为视觉 AI 系统研究的新趋势**,强调基础模型科研需坚持长期主义等。详情可参考。
- 学术论坛上谈“好论文是怎么炼成的”:其参与了以“好论文是怎么炼成的?”为主题的圆桌讨论,分享了 ResNet 背后的故事,还谈及做开创性工作要设计远大正确的目标方向,自己养成探究实验现象原因、广泛梳理前人工作等习惯。优快云 对相关内容的总结链接。
- 厦门大学计算感知实验室学术分享:张祥雨曾向厦门大学计算感知实验室分享其关于密集物体检测的研究工作,讲述了 CrowdHuman 数据集构建的背景与历程,以及学术界和工业界研究要求存在差别等自身感悟等。相关内容的 PDF
- 对话旷视研究院张祥雨|ChatGPT的科研价值可能更大
- 旷视研究院基础科研负责人张祥雨:让人工智能尽早改造物理世界

















 3988
3988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









