




 DeepMind推出了一种名为α-Rank的新方法,用于评估多智能体的协作和竞争。该方法基于动态博弈理论,解决了以往评估指标在大规模多智能体交互中的局限性,能确保排名的唯一性和可计算性。α-Rank通过分析智能体之间的交互,形成种群动态系统,以马尔可夫-Conley Chains为基础,提供了对智能体优势和弱点的深入理解。已在AlphaGo、AlphaZero等游戏中得到应用。
DeepMind推出了一种名为α-Rank的新方法,用于评估多智能体的协作和竞争。该方法基于动态博弈理论,解决了以往评估指标在大规模多智能体交互中的局限性,能确保排名的唯一性和可计算性。α-Rank通过分析智能体之间的交互,形成种群动态系统,以马尔可夫-Conley Chains为基础,提供了对智能体优势和弱点的深入理解。已在AlphaGo、AlphaZero等游戏中得到应用。

大数据文摘出品
来源:Nature
编译:魏子敏、宁静
在开发通用人工智能的过程中,训练和评估算法同样重要。
评估指标不仅仅在培训结束时发挥作用,并且也是整个培训过程中智能体进化的关键驱动因素。
错误的排序和不合理的限制可能会让AI自行进化出奇怪的“心眼”。在之前我们的一篇报道中就总结了错误的评估方式导致的AI“钻空子”训练法,比如在让AI玩俄罗斯方块的时候,发现最佳完成任务的方式是直接暂停游戏;在玩井字棋的时候,AI发现它如果做出奇怪的步骤,对手会非常崩溃。
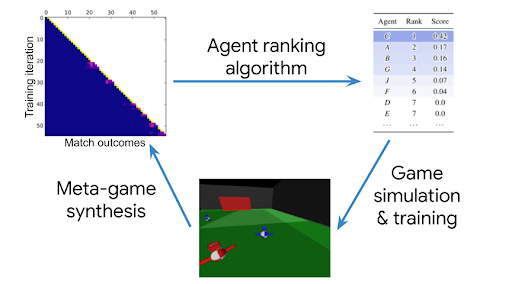
Deepmind一直致力于研发多智能体的训练算法,并且很看重过程中的评估。他们刚刚发布了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1362
1362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









