






 本文深入解析Seq2Seq模型及其注意力机制,探讨如何通过动态权重分配改善翻译精度,特别是在处理长句子时的对齐问题。通过实例代码,详细说明了如何在神经网络翻译中实现这一机制。
本文深入解析Seq2Seq模型及其注意力机制,探讨如何通过动态权重分配改善翻译精度,特别是在处理长句子时的对齐问题。通过实例代码,详细说明了如何在神经网络翻译中实现这一机制。
参考github: https://github.com/graykode/nlp-tutorial?tdsourcetag=s_pctim_aiomsg中的seq2seq attention部分
就是读懂了他的代码又自己写了一遍
原理
整个的神经网络翻译的结构是seq2seq ,原句从encode部分进入,每一步都会输出一个状态hj,结合每一步的hj可以得到一个综合输入信息的山下文向量context vector c
用这个context vector可以传给decode部分,在decode的第i步,结合当前要参考的输入上下文向量、上一步输出的词yi-1和当前的decode输出状态可以预测当前的词汇yi
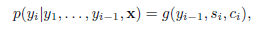
而当前的输出状态si由上一步的输出状态si-1,上一步的输出yi-1和当前的上下文向量共同决定
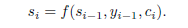
attention机制是作用在求这个context vector上。如果不考虑注意力机制,那么输入句子得到的上下文状态是一样的(可以认为每一步的hj权重都是1,求和得到总的向量),那么在翻译时,翻译每个词的时候参考的都是这个向量。
但是实际上翻译后的语言中的每个词对应着翻译前句子中的不同的词(或词组),比如中文的“啤酒”对应的其实是英文的“beer”一个词,那么在翻译时,“啤酒”和’beer"应该是对齐的,也就是翻译时应该分配更多的权重在beer上面
所以attention机制实质上就是对输入的h1…hT计算一个权重得分,最后的加权和就是为了翻译当前词yi的输入上下文向量ci
前面那个系数就是权重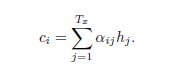
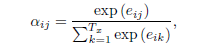 这实际是过了一个softmax,使得原始计算的得分加起来等于1,也就是权重,eij就是在decode第i步时对hj重要程度的打分
这实际是过了一个softmax,使得原始计算的得分加起来等于1,也就是权重,eij就是在decode第i步时对hj重要程度的打分
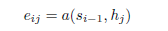
这里就是每一步的hj与每一步的decode si-1一个函数关系,在代码里为点乘(加系数)
代码
主要架构就是:
- 准备参数和数据
- 处理成批处理的数据
- 计算attention的权重
- encode-decode框架
- feed数据训练和测试
参数和数据部分
由于不是重点,就只用一个数组存了三句话,分别是input,output和target
batch_size = 1,词表就是这个数组中全部的词(n_class),词的表示用的one-hot而不是embedding,每句话的最大长度也就是n_step = max_sent_len = 5; 隐藏状态数n_hidden = 128
在计算attention权重时用到两个参数,att_p : [n_hidden,n_hidden]和根据si-1和context_vector计算输出的时候用到的参数out_P :[2*n_hidden,n_class]
由于这里batch_size=1,所以处理成批处理的数据只是将单词转化为对应的id,然后在转化成词表长度的one-hot矩阵,最后加一层括号表示batchsize
encoder_inputs: [batch_size,max_sent_len,n_class]
计算attention权重
这包括两部分
一个是get_attn_score(dec_output,enc_output) 也就是计算原理中得分eij的部分
dec_output是decode每一步的输出,[batch_size,1,n_hidden]
这里的参数enc_output并非全部h,而是一步的输出hj
计算的方式是:dec_output,att_P,enc_output的点乘
另一部分是最红的结果,也就是每一步的权重全部返回:
get_attn_weights(dec_output,enc_output)
这里的enc_output: [batch_size,n_step,n_hidden] dec_output [batch_size, 1,n_hidden]
这里经过一些transpose变换,让enc_output变成[n_step,batch_size,n_hidden],这样就循环每一step,调用get_attn_score计算得分
最后将这些得分经过softmax得到归一化的权重返回
encode decode 框架
encode 部分比较简单:
就是准本一个cell
然后dynamic_rnn,得到enc_outputs和最后一步的状态enc_state
enc_ouputs, enc_state = tf.nn.dynamic_rnn(cell,inputs=encoder_inputs,dtype=tf.float32)
decode部分,要再次基础上对每一步计算权重分布,从而计算上下文向量,有了上下文向量和rnn的输出状态,才能计算最终的概率分布:
for i in range(n_step):
# dec_outputs: [batchsize,1,n_hidden]
dec_outputs, dec_state = tf.nn.dynamic_rnn(cell=cell,inputs=tf.expand_dims(inputs[i],1),
initial_state=enc_state,dtype=tf.float32, time_major=True)
attn_weights = get_attn_weights(dec_outputs,enc_ouputs)
# [batchsize,1,n_step] [batchsize,n_step,n_hidden] ==> [batchsize,1,n_hidden]
context = tf.matmul(attn_weights,enc_ouputs )
context = tf.squeeze(context,axis=1) # [batchsize,n_hidden]
dec_outputs = tf.squeeze(dec_outputs,axis=1)
concat = tf.concat((dec_outputs,context),axis=1) # [batchsize,2*n_hidden] [2*hidden,n_class]
# [batchsize,n_class]
model.append(tf.matmul(concat,out_P))
feed数据训练和测试
prediction = tf.argmax(model,2)
cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=model,labels=targets))
optimizer = tf.AdamOptimizer(lr).minimize(cost)
在Session里面
多个epoch,读入批处理的数据,喂进去,得到这里的cost和optimizer
测试部分就是上面填进去的数据不一样,训练prediction

















 1637
1637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









