







 本文介绍如何使用卷积神经网络(CNN)进行句子级别的文本分类,包括模型架构、参数设置及训练流程。通过不同大小的卷积核提取文本特征,经过池化、全连接层后,利用softmax函数进行分类预测。
本文介绍如何使用卷积神经网络(CNN)进行句子级别的文本分类,包括模型架构、参数设置及训练流程。通过不同大小的卷积核提取文本特征,经过池化、全连接层后,利用softmax函数进行分类预测。
论文: Convolutional Neural Networks for Sentence Classification
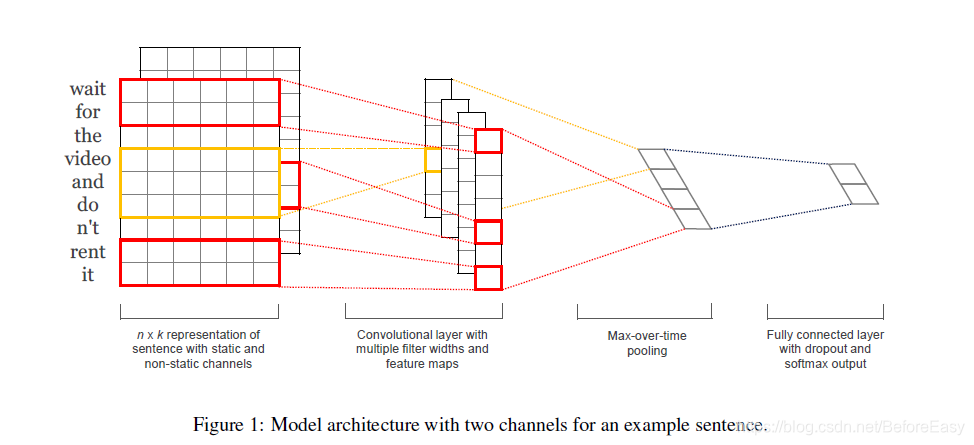
将每个词取出词向量的形式,作为卷积的输入。
通过filter获取不同的特征,经过池化和全连接,用softmax求出概率,进行分类
仍然是简化文本处理的部分,只用6个句子作为全部训练语句,同时batch_size =6
三部分
- parameters
- 计算卷积池化全连接的主体部分
- 训练和预测
参数部分:
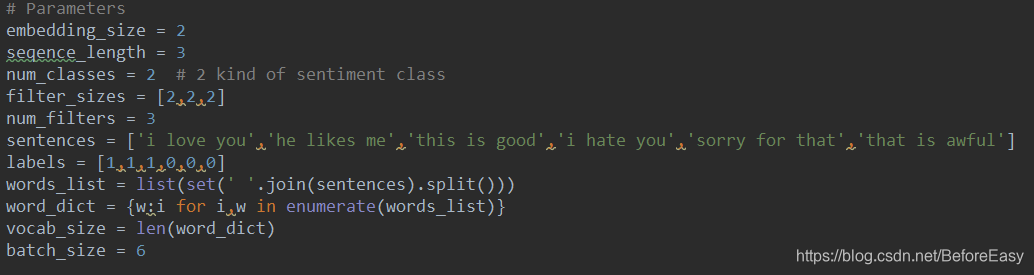
分别是向量维数,每个句子最大的长度,分类数,卷积核大小和数量,这里用了三个卷积核
然后就是常规的对训练语句分词处理,获得词汇表等

这里的XY分别是模型的输入和输出,输入是将单词转化为序号的序列,输出就是【0,1】表示的分类
为了简单,没有训练词向量,而是随机生成的
embedded_chars就是喂进去的句子的词向量表示,由于总共就只有6个句子,所以输入就是这六个
计算卷积池化全连接部分:
有三个卷积核,循环来处理
每次卷积核的大小:filter_shape =[filter_size,embedding_size,1,num_filters],表示[filter_height, filter_width, in_channels, out_channels]
用CNN处理自然语言处理时,卷积核的宽度至少要是词向量的维度,可以看第一张图的表示
论文中有两个输入channel,这里只有一个
filter的值W是随机生成的,大小就是filter_shape
然后经过tf.nn.conv2d
在加个bias,过relu激活函数
在经过max_pooling
得到的就是本次卷积池化后的结果,全部放到pooled_outputs =[]里,连接起来一起使用
concat后过一个全连接,前端连接的是总的num_filters数,后面就是类别数
得到的结果就是logit
训练和预测
就是喂进去训练语句转化为序号的句子,以及对应的label
预测时输入变为新的测试语句转化为的序号序列
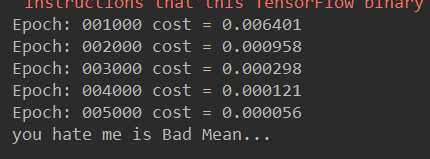
简单结果如下:

















 2445
2445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









