








摘要:
Neural machine translation 是用encoder 将源输入编码成固定长度的向量,然后再用decoder解码成目标语言。但是使用固定长度是受限制的,本文就是要提出一种新的机制,让decode的时候可以比较动态的search 源输入。其实也就是attention机制
introduction:
常用的encoder-decoder模式在编码成固定长度的向量时,可能会失去一些有用的信息,尤其是输入很长的时候。为了解决之歌问题,引入一种机制,让翻译和对齐同时进行。(直观的理解,中文的表达顺序并不是和英文输入一一对应,所谓对齐就是在生成第yt个目标词的时候应该更关注源输入哪个词,也就是说现在翻译的源输入中哪个词或哪几个词)
Background:
translation就是要找arg max P(y|x),也就是给定了输入x之后找概率分布中最大的那个为输出
Encoder-decoder模型:
encoder读入输入序列X,最终将其转化为语境向量c,用于decode
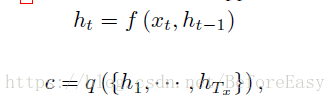
ht是t时刻的hidden state ,语境向量c是由hidden state相关的向量
decoder就是根据当前的语境向量c,以及已经预测出的序列y1,y2,,yt-1,来预测下一个词
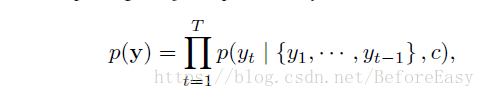
Learning to align and translate
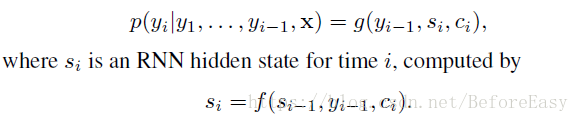
其实attention机制主要体现在语境向量c的计算上
相当于给每个输入的词的向量进行打分,预测的时候只需要关注得分更高的词组成的语境向量c
架构如图:
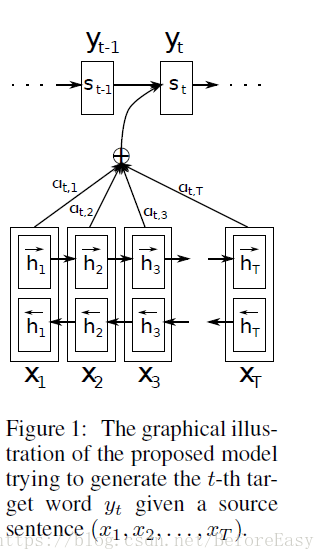

也就是aij相当于一个softmax过的得分,当前的语境向量ci就是一个得分的hidden state的加权和
eij就是alignment 模型中的一个评分,评定j位置的输入和i位置的输出之间的匹配程度
其训练方式就是和整个翻译模型一样的
Encoder是双向RNN,因为我们不仅仅想要一个词之前的词的信息,还想要后面的词的信息与关系

也就是前向来一次,后向再来一次,然后连接起来,共同构成hidden state hj
Expieriment
English-French parallel corpora
结果:
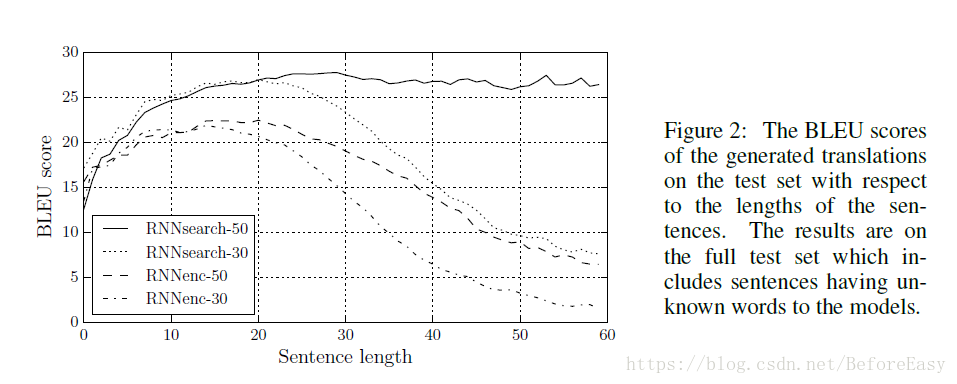
训练了RNN decoder-encoder模型和本文的RNN Search 模型

















 1636
1636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









