



别再只看故障率了,设备管理真正的三大核心指标一次讲清!
一说设备管理,大家第一时间想到的永远是——故障率。
但你真要问一句: “故障率低”的工厂,就一定设备管理好? “故障率高”的工厂,就一定管理差?
我在生产一线,见过太多反例。
有一次我去调研一家电子厂,老板自豪地跟我说:“我们设备故障率已经压到 2% 以下了。” 结果走到现场一看:产线效率低得吓人,设备开机率不高,微停不断,保养随缘,巡检靠师傅的心情。
这就是典型的:报表很好看,产能很难看。
所以今天这篇文章,我想说一个可能不那么好听的观点:
在今天这种节奏越来越快、设备越来越贵的生产环境里——只盯故障率,不仅落后,还可能害厂。
真正的设备管理,它至少包含三个关键指标: OEE、MTBF/MTTR、保养达成率(PM Compliance)。
这三件事,才是真正能提升产能、延长设备寿命、减少停机损耗的底层逻辑。
下面我给你讲清楚为什么。
一、别再只看故障率了
很多工厂的误区在于: 故障率可控,但设备问题却无处不在。
比如:
- 一天停一次机 vs 一小时停 10 次微停机,你觉得哪个更影响产量?
大部分人会本能觉得“停一次机更严重”。
但如果你算过 OEE,你就知道:
真正把产能拖垮的是微停机,是不稳定,是效率波动。
也就是说:故障率低 ≠ 没问题;故障率高 ≠ 不能救。
你要真正把设备管理拉到一个更专业、更可控的层级,就得把“只看故障率”的思路放下。
https://s.fanruan.com/0d30s
二、设备管理真正的三大核心指标
设备管理体系里,有很多 KPI。
但能决定你的设备“到底是不是在为企业赚钱”的三大核心指标只有:
1. OEE
2. MTBF / MTTR
3. PM 完成率(保养达成率)
它们不是并列关系,而是因果关系。 你做设备管理,其实就是围绕这三件事不断闭环。
下面我一条条讲。
核心指标 1:OEE(真正衡量设备价值的指标)
OEE (Overall Equipment Effectiveness)是设备综合效率。
你想真正算清楚:
- 设备有没有发挥应有价值
- 产能到底是从哪儿掉的
- 为什么两条产线设备一样,产出却能差 30%
- 为什么老板总觉得设备利用率不高
那 OEE 是唯一能给你完整答案的指标。
OEE 的构成你可能知道:
- 可用性(Availability)
- 性能(Performance)
- 良品率(Quality)
但大部分工厂卡在第一步:
可用性这项就有 40% 的工厂算不准确。 因为微停从来没被真正记录,换线时间和等料时间混在一起,保养时间和故障停机混在一起。
所以 OEE 不是算公式,而是算认知。
你只有真正把一个设备从 8 小时班里到底“有效工作”了多久搞清楚,你才能知道自己到底损失了多少。 而这个东西,到今天仍然靠纸笔、靠经验、靠师傅记忆的工厂非常非常多。
有的工厂会用低代码或工单系统把这些记录流程做起来,比如很多厂现在用 简道云设备管理系统 去做设备台账、保养任务、停机信息、点检记录,甚至接设备信号做自动采集。
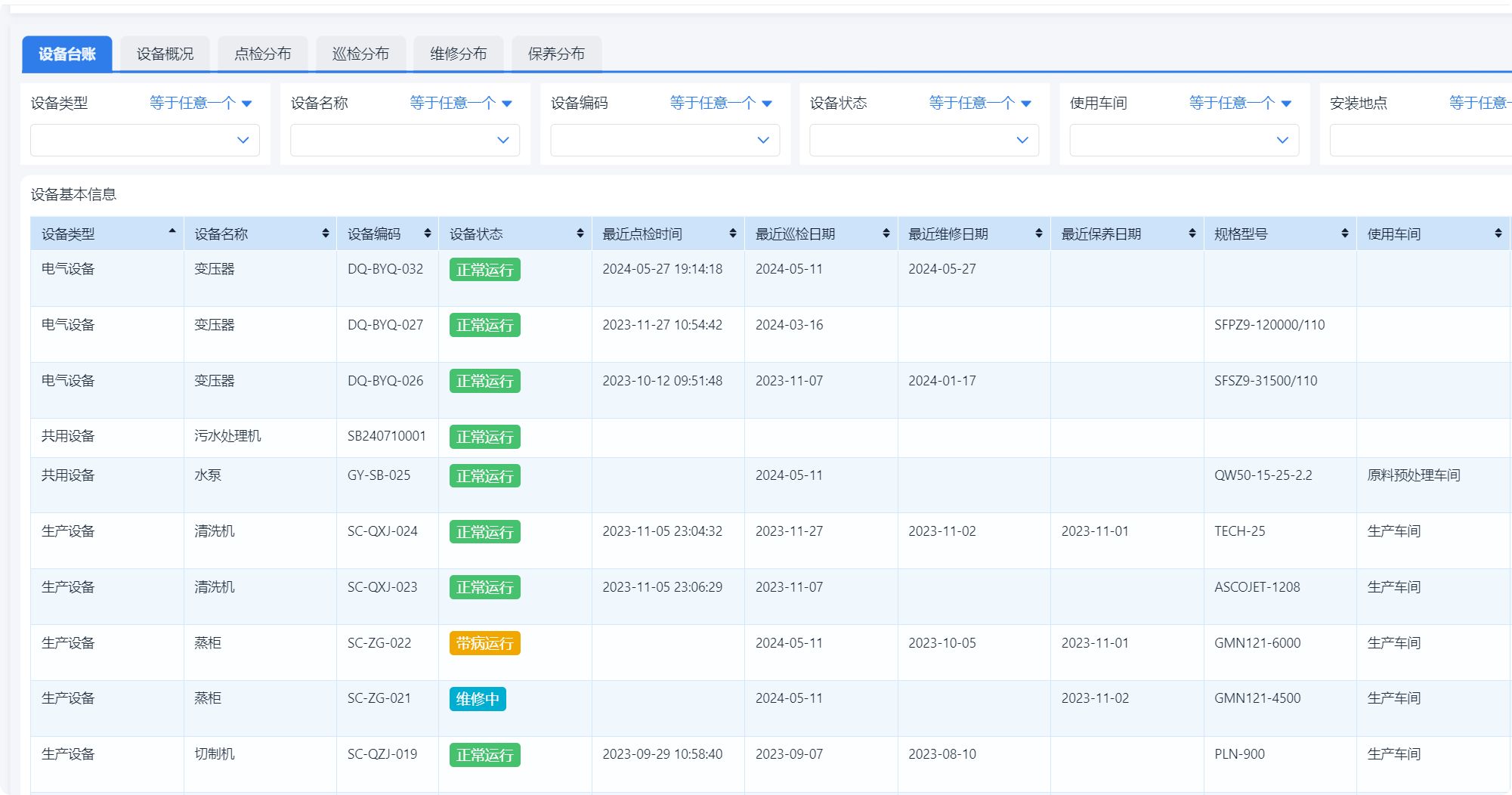
它不是“自动化系统”那种重投入,而是填一个字段、设一个字段、拉一张仪表盘就能上手,逻辑非常轻——但对 OEE 的提升意义巨大。
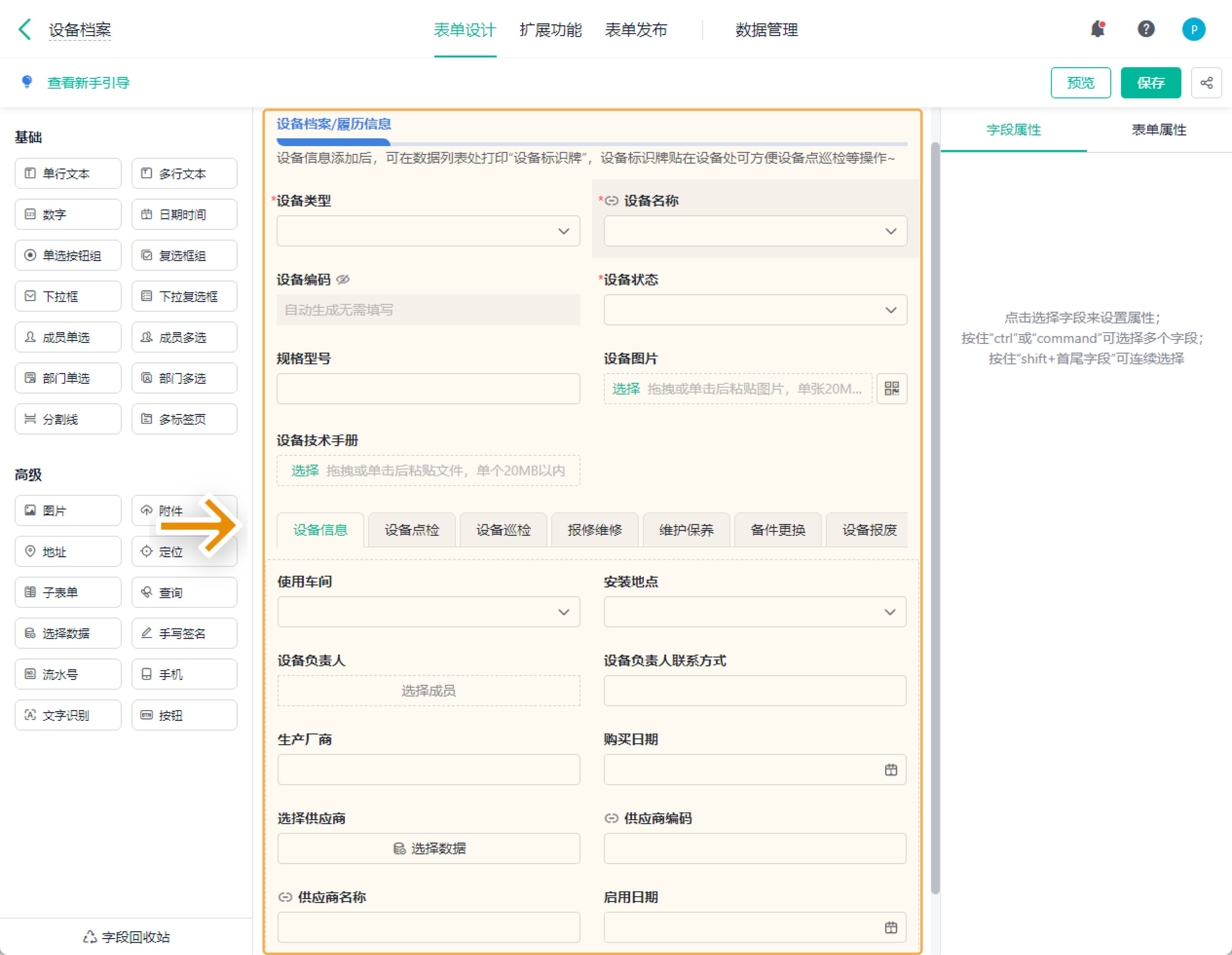
因为当你把停机原因拆清楚,把微停记录下来,把换线时间分类清楚,你会发现:
你的 OEE 并不是提升,而是第一次被看见。
核心指标 2:MTBF / MTTR
第二个指标其实是两个: MTBF(平均无故障时间) MTTR(平均修复时间)
它们代表的不是“设备坏没坏”, 而是:设备为什么坏、坏得是否正常、修得是否专业。
举个简单例子:
同样是每月故障 4 次的设备:
- A 设备:每次修 10 分钟
- B 设备:每次修 2 小时
你觉得哪个更严重?
多数工厂只看件数(4 次),但不看停机损失。 这是非常危险的判断方式。
相反,有的设备一年坏 10 次,但每次只停 5 分钟,间隔 3 个月坏一次。 这反而是“正常损耗”。
要看 MTBF,你会自动看到两个东西:
- 是不是某个点位反复坏(根因分析是否有效)
- 设备寿命是不是健康(属于材料老化还是人为操作问题)
要看 MTTR,你会看到:
- 维修班效率到底高不高
- 备件是不是准备合理
- 维修流程是不是规范
很多工厂的维修效率低,不是师傅不专业,而是:
- 备件找不到
- 故障信息记录不全
- 历史维修记录查不到
- 工单派发慢
- 维修结果没有复盘
所以 MTBF/MTTR 看起来像数据,但它背后是整个维修体系的成熟度。
简道云设备管理 + 巡检系统在很多工厂的玩法是:
- 工单一键派出
- 故障点位自动记录在台账
- 每次维修自动积累历史记录
- 备件消耗自动扣减
- 维修完成后的确认必须闭环
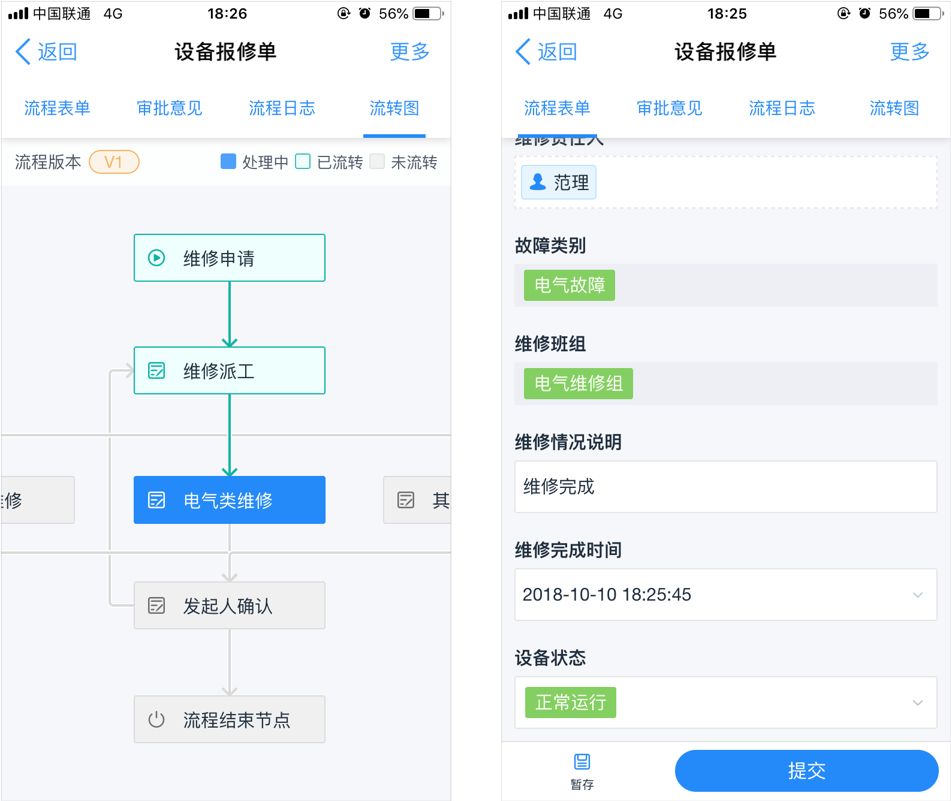
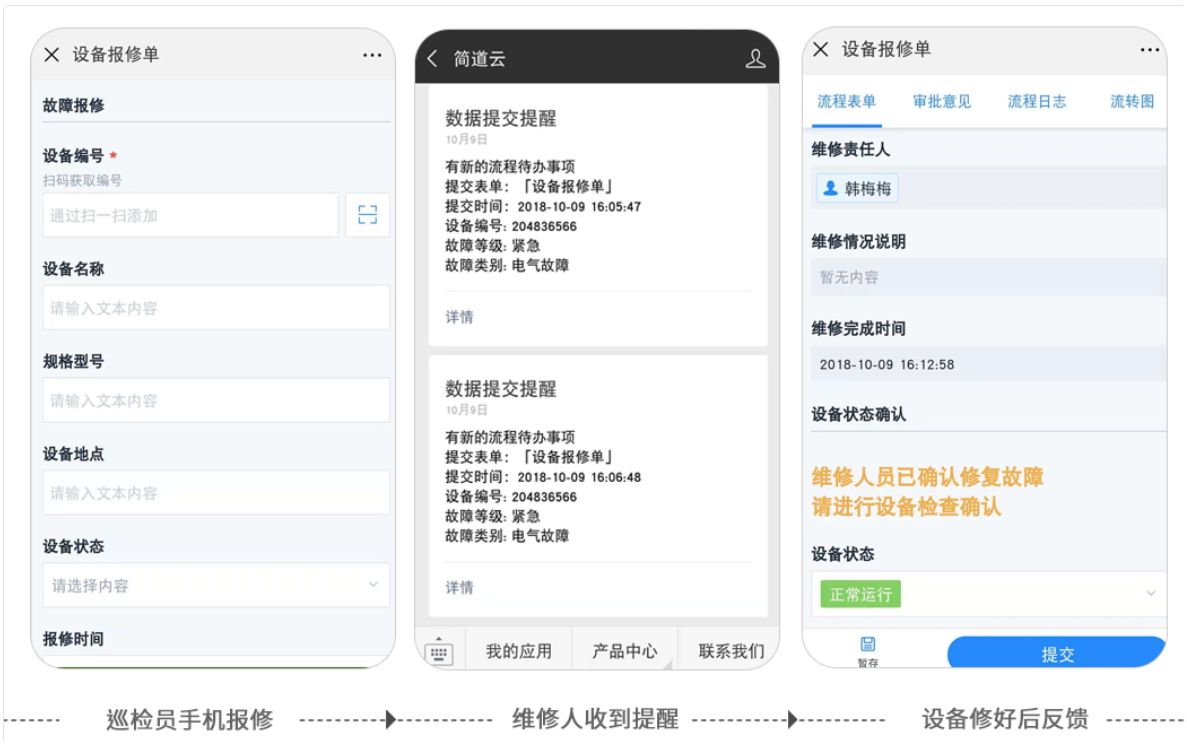
很多设备班长说得很实在:
“不是系统让我们更专业,是系统让我们没机会做不专业的事。”
这话挺扎心,但很真实。
核心指标 3:PM 完成率(保养达成率)
保养达成率为什么这么重要?
因为设备问题里有 70% 是—— 因为没有保养造成的。
我说句行业里的真话:在中国大部分工厂里,保养不是按照计划做的,是按照感觉做的。
典型表现:
- 忙的时候不做
- 赶订单不做
- 感觉没问题就不做
- 没提醒就忘了做
- 做了没记录
- 记录了没人看
- 表格堆了一桌子但没有一次复盘
这就是为什么同样的设备,有的工厂能用 10 年,有的工厂 3 年就老化。
保养达成率这个指标值,就是告诉你:
你到底有没有真正管理设备寿命,而不是等待设备坏。
用系统进行设备保养:
- 保养计划可以按周期自动生成任务
- 巡检表单可以根据工艺/设备类型自动套模板
- 每次巡检异常直接生成工单
- 保养执行必须签到、拍照、上传记录
- 逾期会自动提醒
- 负责人、班组长、设备主管都能看到执行情况
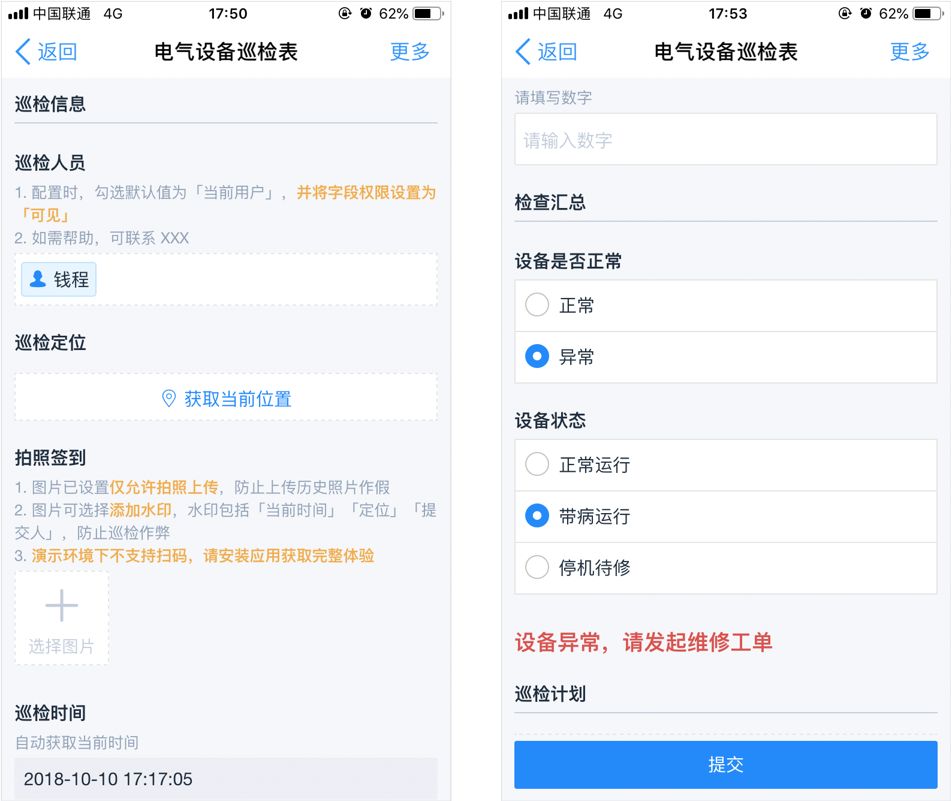
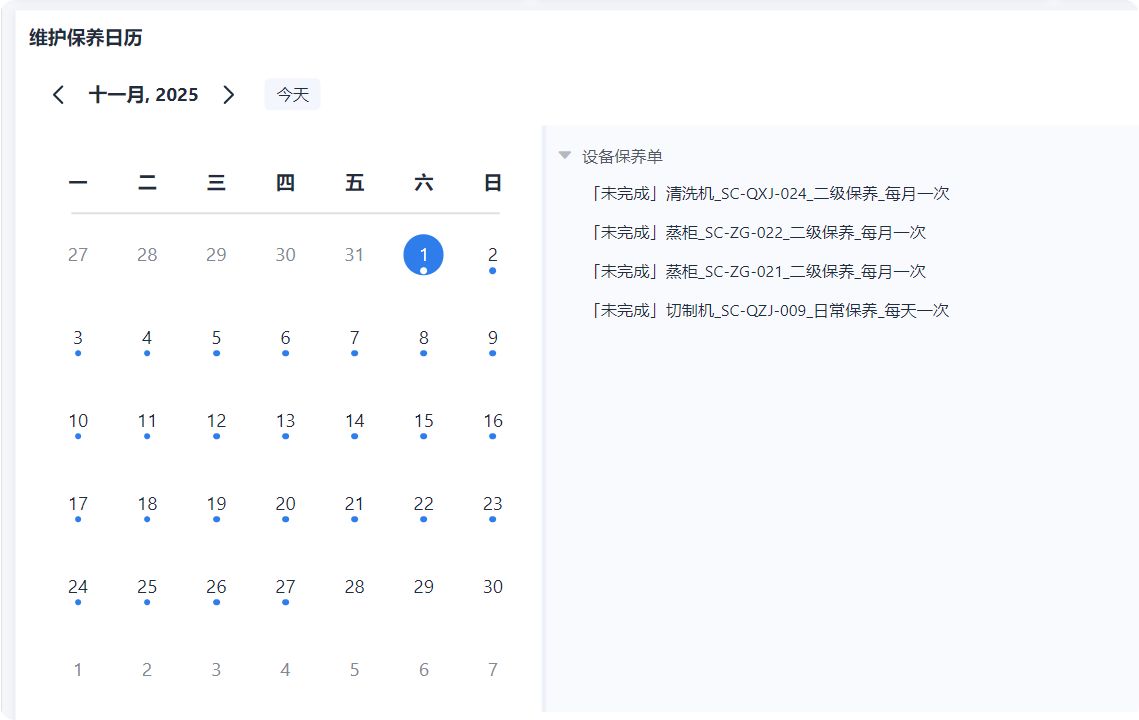
它解决的不是“保养本身”, 而是保养不透明、不可追踪、不闭环的问题。
你只要把 PM 完成率做到稳定在 90% 以上,设备的“随机坏”“突然坏”“当天坏三次”的情况会明显减少。
为什么很多工厂做不好?因为缺的是体系,不是工具
很多老板以为“设备管理不行”是因为:工程师水平不够、维修人员太忙、设备太老......
但我看过的工厂越多,越确定一件事:设备管理的问题,90% 是体系问题,而不是人员能力问题。
比如:
- 有巡检,但没有巡检闭环
- 有保养,但没有保养提醒
- 有台账,但没有台账更新
- 有维修记录,但无法查询历史
- 有工单,但无法跟踪进度
- 有 KPI,但算不准
- 有报表,但无人看
这就是为什么很多工厂看着“有制度”,但效果一直起不来。
三、设备管理升级:最务实的路径是什么?
我见过一些工厂花几百万上大型设备管理系统,结果因为太复杂,现场不愿用,最后不了了之。
我也见过更多工厂从 Excel、微信群、纸质巡检表起家,体系永远上不去。
真正务实的路径是什么?
其实是:先把制度数字化,而不是先把设备数字化。
你可以从这几步走:
- 用工具把工单管理跑起来
- 把巡检/点检的过程标准化
- 把保养计划做成自动提醒
- 把台账、备件、维修记录全部沉淀
- 把停机原因分类,开始计算 OEE
这些事情,都不需要很重的投入, 但结果对设备管理的提升,是巨大且立即可见的。
这就是为什么很多中小工厂愿意从简道云这种低代码工具开始做设备管理,不是为了“上系统”,而是为了把流程跑顺,把数据沉淀,把体系建立起来。
四、写在最后
你想让设备管理真正提升,别再盯着故障率这个“冰山上的数字”了。
故障率只是结果,体系才是原因
今天的工厂竞争,拼的不再是“谁的设备坏得少”, 而是:
谁能用体系把设备潜能榨得更高,把损耗降得更低,把效率做得更稳。
而体系怎么落地? 靠流程、靠机制,也靠工具。
如果你现在还只盯着故障率,其实不是落后,而是错位。 你盯的是结果, 但真正影响利润的是过程。
希望以上对你有帮助。

















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









