




Transformer
- Transformer是基于Encoder-Decoder结构的,将Seq2Seq中的RNN/GRU部分更换为Self-Attention部分
位置编码
- Positional Encoding
Self-attention丢失了位置信息
-
CNN 卷积神经网络可以保存相邻的位置信息
-
RNN 是顺序输入的,是包含了位置信息的
-
Self-Attention 是并行计算的,丢失了位置信息,位置编码为Self-Attention补充位置信息
为什么不用token的索引直接作为位置编码:
- 序列的长度是可以变化的,如果出现句子非常长的情况,模型的泛化能力较差,因此使用索引作为位置编码会损害模型的泛化能力,缺乏处理没见过的长度的能力
- 如果用norm对序列长度进行归一化,会出现相同的位置编码在不同的长度中对应不同的位置,不利于计算
位置编码希望达到的情况:
- 为每个时间步骤(单词在句子中的位置)输出唯一的编码。
- 任何两个时间步骤之间的距离在不同长度的句子之间应该是一致的。
- 我们的模型应该方便地推广到更长的句子。它的值应该是有界的。
- 位置信息必须是确定性的。
位置编码的方式:
- 固定位置编码
- 可学习位置编码
固定位置编码
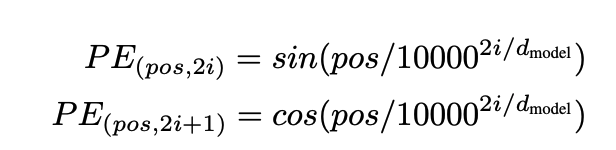
pos是位置,i是维度索引,d_model是嵌入总维度.
频率和波长呈反比关系,波长越长,变化越慢,频率越低
很明显波长的计算和 10000^2i / d_model 有关系
"""
位置编码
"""
class PositionalEncoding(nn.Module):
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个全为0的足够长的P
self.P = torch.zeros((1, max_len, num_hiddens))
# 根据上面的公式进行计算
X = torch.arange(max_len, dtype=torch.float32).reshape(-1, 1) /
torch.pow(10000, torch.arange(0, num_hiddens, 2, dtype=torch.float32)
/ num_hiddens)
# 计算后引入Sin Cos
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
def forward(self, X):
# 将计算好的Positional Encoding和原始的X即嵌入进行融合
X = X + self.P[:, :X.shape[1], :].to(X.device)
# dropOut(X)
return self.dropout(X)
网络模块
AddNorm
-
使用 self.ln(self.dropout(Y) + X) 实现
-
Residual connection and LayerNormalization 残差链接和层归一化
"""
残差连接后进行层规范化
"""
class AddNorm(nn.Module):
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
Positional-wise Feed-Forward Network
位置前馈网络是Transformer模型中的一个重要组成部分,它通过提供额外的非线性变换和深度,增强了模型对输入序列的理解能力,从而提高了模型在各种自然语言处理任务上的性能。
- Positional-wise Feed-Forward Network
使用基于位置的前馈网络对所有位置进行变换
- 基于多层感知机MLP
- 输入X ( batch_size,time_steps,hidden_num ),被两层的感知机转换为(batch_size,time_steps,ffn_num_outputs)
- 可以实现,对所有的位置进行变换,相同的输入和相同的位置得到的输出也是相同的
#@save
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
Q:位置前馈网络的作用
- 增加模型的非线性能力
- 增强表示能力:FFN通过两层全连接层(线性变换)来增加模型的深度
- 保持位置不变性:虽然FFN本身对每个位置独立地应用相同的变换,但它并不改变序列中元素的相对位置关系。
- 与自注意力机制互补:在Transformer模型中,FFN通常与自注意力机制(Self-Attention)一起使用。自注意力机制允许模型在处理序列时考虑不同位置之间的关系,而FFN则提供了一种方式来进一步处理这些关系,以生成更丰富的特征表示。
Q:位置前馈网络和位置编码的关系?
位置编码(Positional Encoding)和位置逐元素前馈网络(Position-wise Feed-Forward Network)是Transformer模型中的两个关键组件,它们在模型中扮演着不同的角色,但又相互关联。
- 位置编码(Positional Encoding):
- 位置编码的主要作用是为模型提供序列中词的位置信息。由于Transformer模型中的自注意力机制本身不包含任何关于词顺序的信息,位置编码通过在每个词的嵌入向量中添加一个唯一的位置向量来解决这个问题。
- 位置编码可以是绝对位置编码,也可以是相对位置编码。在原始的Transformer模型中,通常使用正弦和余弦函数的不同频率来生成位置编码,这种编码方式被称为Sinusoidal Positional Encoding。
- 位置编码通常与词嵌入向量相加,为模型提供关于词位置的信息,帮助模型理解输入序列中的顺序关系。
- 位置逐元素前馈网络(Position-wise Feed-Forward Network):
- 位置逐元素前馈网络位于自注意力层之后,它对每个序列位置的输出进行独立的线性变换,通常包括两个线性层,中间夹着一个ReLU激活函数。
- 这个网络的目的是捕捉序列中的局部特征,它与自注意力层一起工作,自注意力层负责捕捉序列中的长距离依赖关系,而位置逐元素前馈网络则负责学习更深层次 的特征表示。
- 由于这个网络对每个位置单独应用,因此被称为“位置逐元素”的,意味着它在每个序列位置进行相同的操作,但操作是独立进行的。
在Transformer模型中,位置编码通常在自注意力机制之前添加到输入序列中,而位置逐元素前馈网络则在自注意力机制之后应用。这样,模型首先利用位置编码来理解词的顺序信息,然后通过自注意力机制捕捉词之间的依赖关系,最后通过位置逐元素前馈网络进一步提取特征,从而实现对序列数据的深入理解
Self-Attention
-
每个Q都会关注所有的Key-Value并生成一个注意力输出;
-
如果查询、键和值来自同一组输入,就称为Self-Attention(intra-Attention);
不同的注意力计算方式用于计算α评分函数的方式不同;
加性注意力
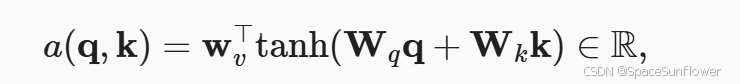
- 其中的Wv Wq Wk都是可以学习的参数
class AdditiveAttention(nn.Module):
"""加性注意力"""
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys)
# 在维度扩展后,
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使用广播方式进行求和
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# self.w_v仅有一个输出,因此从形状中移除最后那个维度。
# scores的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = self.w_v(features).squeeze(-1)
self.attention_weights = masked_softmax(scores, valid_lens)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
return torch.bmm 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











