







八大数据结构——哈夫曼树(七)
树是数据结构中非常重要的一项,有关树的数据结构有许多种,本文重点研究的是哈夫曼树(最优二叉树)。
基础定义
路径: 对于一棵子树中的任意两个不同的结点,如果从一个结点出发,按层次自上而下沿着一个个树枝能到达另一结点,称它们之间存在着一条路径。可用路径所经过的结点序列表示路径,路径的长度等于路径上的结点个数减1。
权重: 无论是节点还是路径都可以带有一个权重,通常可以是一个数值。这个权重在不同的情况下可以代表不同的含义,比如路径的权重可以代表这条路的实际距离,节点的权重可以代表这个节点出现的频率等。总之要放在具体情况下分析。
树的带权路径长度(WPL): 树的所有叶结点的带权路径长度之和,称为树的带权路径长度表示为WPL。
树的带权路径长度记为WPL=(W1L1+W2L2+W3L3+…+WnLn),Wi是每一个叶节点的权重,Li是相应的叶结点的路径长度。
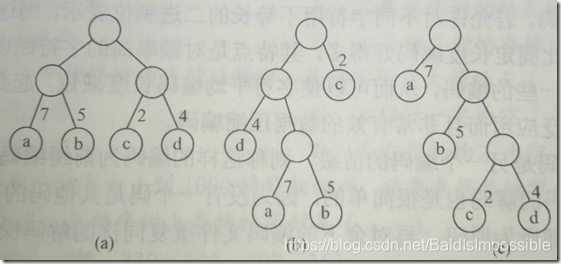
比如上图中的三个二叉树,WPL分别为:
( a ) WPL = 7x2+5x2+2x2+4x2=36
( b ) WPL = 2X1+4X2+7X3+5X3 = 46
( c ) WPL = 7x1+5x2+2x3+4x3 = 35
我们可以看出,不同的构造方式,算出来的WPL是不一样的。由此我们引出哈夫曼树的定义。
哈夫曼树: 给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。(即我们要构造一个WPL最小的二叉树,这个二叉树就是哈夫曼树)
特点:
1.是一个二叉树。
2.WPL最小。
适用场景:
数据压缩和解压缩,哈夫曼编码。
哈夫曼树的构造
首先,给定好要用的叶子节点。node=[7,2,5,4]
1.将node排序,然后拿出前面最小的两个数,创建左右子节点,并赋值,再新建一个父节点,值为左节点值+右节点值。然后,如果node里面不为空,那就将父节点的值放入node。

2.再将node排序,然后拿出前面最小的两个数,创建左右子节点,并赋值,再新建一个父节点,值为左节点值+右节点值。注意,此时如果拿出的一个值是上一步新加进来的值,那么此时不需要为它去创建一个节点,找到之前创建的节点就可以了。然后,如果node里面不为空,那就将父节点的值放入node。
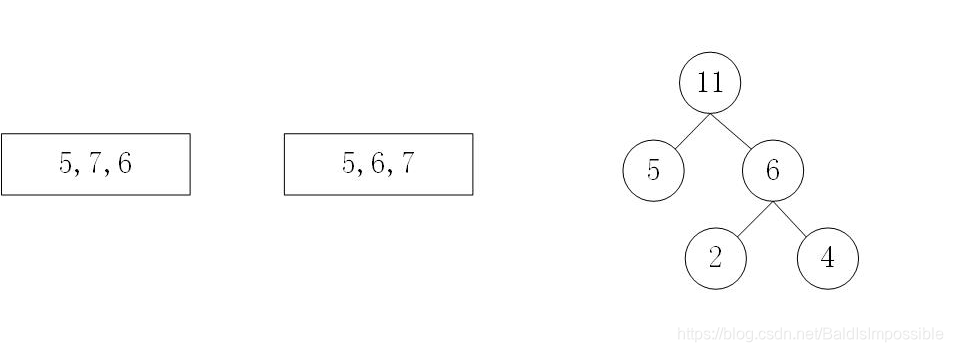
3.再将node排序,然后拿出前面最小的两个数,创建左右子节点,并赋值,再新建一个父节点,值为左节点值+右节点值。注意,此时如果拿出的一个值是上一步新加进来的值,那么此时不需要为它去创建一个节点,找到之前创建的节点就可以了。然后,此时node里面已经为空,那就创建完毕,结束。

注意:哈夫曼树的构架并不唯一,只要保证WPL最小原则,且是二叉树即可。

使用node=[2,3,4,5]构建哈夫曼树,上图两种结果都对,甚至还有其他结果。
(1)5x1+4x2+2x3+3x3 = 28
(2)2x2+3x2+4x2+5x2 = 28
哈夫曼树编码
通过哈夫曼树,我们可以对字符进行二进制编码,并得到唯一的编码结果。如我们需要对[a,b,c,d,e,f]这些字符进行编码。
1.首先我们统计不同字符在文章里出现的频率,以此作为权重。假设现在的统计结果是a:45、 b:13、 c:12、 d:16、 e:9、 f:5。
2.构建哈夫曼树。
3.我们规定,连接左子节点的路径为0,连接右子节点的路径为1。那么现在我们对a进行编码:从根节点出发,要走左节点方向,那么就是“0”,然后就找到了。所以a:0;
再比如我们要编码b,从根节点出发,走右节点方向,那么就是“1”,再走左节点方向,那么就是“10”,就是在后面添加0或1! 再走右节点方向,那么就是“101”,然后就找到了,所以b:101。
同理可得:c:100、d:111、e:1101、f:1100 。
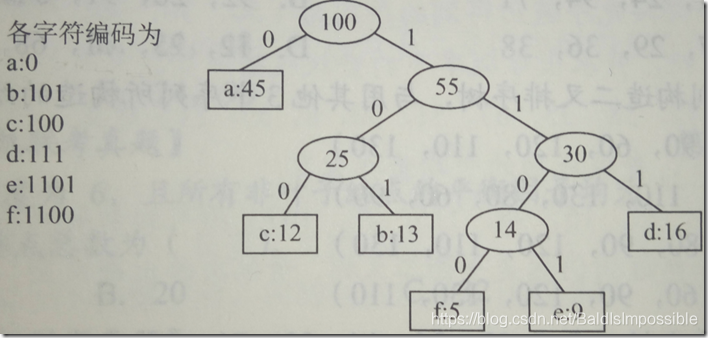
我们发现,越是权值大的字符,越靠近根节点,编码位数也越短,因为权值大的字符表示出现的频率高,如果只需要较短的位数就能表示,那么就可以大大缩小所需的空间量。
在处理字符串序列时,如果对每个字符串采用相同的二进制位来表示,则称这种编码方式为定长编码。
若允许对不同的字符采用不等长的二进制位进行表示,那么这种方式称为可变长编码。可变长编码其特点是对使用频率高的字符采用短编码,而对使用频率低的字符则采用长编码的方式。这样我们就可以减少数据的存储空间,从而起到压缩数据的效果。而通过哈夫曼树形成的哈夫曼编码是一种的有效的数据压缩编码。
假设现在我们有a,b,c,d四个字符需要编码,如果使用定长编码,二进制中需要多少位能表示4个数呢?答案是两位,那么结果就是a:00、b:01、c:10、d:11。那么“aaabbcd”这么一串字符串,编码结果就是“00 00 00 01 01 10 11”,一共是14位。
但如果使用可变长编码,用哈夫曼树编码结果a:0、b:10、c:110、d:111。那么“aaabbcd"的编码结果就是“0 0 0 10 10 110 111”,一共是13位。
可以看出,使用可变长编码,可以减少高频率字符的编码长度,最终起到一定的压缩效果。另外,我们也发现,如果是“abcd”,那么定长编码是8位,可变长编码是9位,说明在某些时候,频率较为一致的时候,定长编码有它的优势,但在实际应用中,大多数时候我们的数据不会那么规律,通常是有些字符大量重复出现的,这时候就需要可变长编码了。
另外,可变长编码中,还有一个原则,即一个字符的编码不能是另一个字符编码的前缀。比如a:0、b:00。此时a就是b的一个前缀了,比如当我们有这样一个编码时 000 ,我们是理解为“aaa”,还是“ab”,或者是“ba”?所以可变长编码要满足这个原则。
哈夫曼树解码
解码就是我已知一段编码0101,要把它翻译回字符。
下面具体步骤:
1.从根节点开始,读到下一个是0,那么就走到左子节点上,发现左子节点是一个叶子节点,那么就将该叶子节点保存的字符读出来,就得到“a”。
2.读出一个字符后,又回到根节点,读下一个是1,那么往右子节点上走,此时它不是叶子节点,那么继续读下一个是0,那就再往左子节点走,发现也不是叶子节点,那么继续读下一个是1,那就再往右子节点走,发现此时是叶子节点,读到“b"
3.此时,已经读到的结果是“ab”,发现编码也读完了,那么就是最后结果“ab”。
另外,在我学习的时候,有一个小疑惑,那就是如果有权值相同的时候怎么办
1.在构建哈夫曼树时,有权值相同的不用管它,每次排好序后,就取前面最小的两个。并不影响构建,只是最后构建出的哈夫曼树会不同,但正如前面所说,哈夫曼树的构建结果不唯一!
代码实现
基于Java,jdk1.8,实现一个哈夫曼树。
这里实现的哈夫曼树节点没有保存字符,只保存了权值,要弄完整一点,可以多保存个字符在节点里。
1.定义节点类。
class HuffmanNode{
int val;
HuffmanNode left;
HuffmanNode right;
}
2.定义属性,在构建哈夫曼树时,我们需要用一个容器来保存待选节点,且要频繁删除和增加待选节点,所以我们使用链表来存储待选节点,这样处理起来速度会比数组快。
private HuffmanNode root;//根节点
private LinkedList<HuffmanNode> list;//使用链表来处理待选节点,因为要频繁增删
3.定义构造方法,构建哈夫曼树。第一次排序时,我使用快排,快排数据量大时,会快一些,后面每次的排序用遍历找到正确位置,插入进去即可。快排我之前自己有写好,这里是直接调的。不懂快排,点这里
public HuffmanTree(int[] vals){
QuickSort.randomQuickSort(vals,0,vals.length-1);//先用快排排序
list = new LinkedList<>();
for(int val:vals){
HuffmanNode node = new HuffmanNode();
node.val = val;
list.insert(node);
}
buildHuffmanTree();
}
// 循环构建哈夫曼树
private void buildHuffmanTree(){
if(list.size()==1){
root=list.remove(0);
return;
}
while (list.size()>1){
HuffmanNode left = list.remove(0);
HuffmanNode right = list.remove(0);
HuffmanNode parent = new HuffmanNode();
parent.val = left.val+right.val;
parent.left = left;
parent.right = right;
root = parent;
int n = list.size();
for(int i = 0; i<n; i++){
if(list.get(i).val>parent.val){
list.insert(parent,i);
break;
}else if(i==n-1){
list.insert(parent);
}
}
}
}
4.进行编码,这里是输入一个权值,然后返回对应编码,没有为null,如果哈夫曼树只有一个根节点,那返回为空串。有兴趣的可以自己改进一下,原理都一样。
这里是使用递归实现的,终止条件为,如果找到了就在编码后面添加一个“#”,如果后面的程序检测到已经有“#”,就知道找到了,就会一直退出,直到结束整个递归。如果查找完整个树也没有,就会返回null。
// 给出每一个节点的编码。
private String code(HuffmanNode node,int val,String code){
if(node.val==val&&node.left==null&&node.right==null){
return code+"#";
}
if(node.left!=null){
String str = code(node.left,val,code+"0");
if(str.contains("#")){
return str;
}
}
if(node.right!=null){
String str = code(node.right,val,code+"1");
if(str.contains("#")){
return str;
}
}
return code.equals("")?"":code.substring(0,code.length()-1);
}
public String code(int val){
String code = code(root,val,"");
return code.equals("")?null:code.substring(0,code.length()-1);
}
5.解码。输入一段编码,返回对应的权值,一次只能解一个,多次其实只是用个循环多次调用而已。
// 通过编码找到对应的叶子节点
public int decode(String s){
if(s==null){return -1;}
HuffmanNode node = root;
int i = 0;
while (i<s.length()){
if(s.charAt(i)=='0'){
node = node.left;
}else {
node = node.right;
}
++i;
}
return node.val;
}
完整代码
import SortAlgorithm.QuickSort;
//哈夫曼树(最优二叉树)
public class HuffmanTree{
private HuffmanNode root;//根节点
private LinkedList<HuffmanNode> list;//使用链表来处理待选节点,因为要频繁增删
public HuffmanTree(int[] vals){
QuickSort.randomQuickSort(vals,0,vals.length-1);//先用快排排序
list = new LinkedList<>();
for(int val:vals){
HuffmanNode node = new HuffmanNode();
node.val = val;
list.insert(node);
}
buildHuffmanTree();
}
// 循环构建哈夫曼树
private void buildHuffmanTree(){
if(list.size()==1){
root=list.remove(0);
return;
}
while (list.size()>1){
HuffmanNode left = list.remove(0);
HuffmanNode right = list.remove(0);
HuffmanNode parent = new HuffmanNode();
parent.val = left.val+right.val;
parent.left = left;
parent.right = right;
root = parent;
int n = list.size();
for(int i = 0; i<n; i++){
if(list.get(i).val>parent.val){
list.insert(parent,i);
break;
}else if(i==n-1){
list.insert(parent);
}
}
}
}
// 递归计算带权路径长度WPL
private int Weight(HuffmanNode node, int depth){
if(node.left==null&&node.right==null){
return node.val*depth;
}
return Weight(node.left,depth+1) + Weight(node.right,depth+1);
}
public int Weight(){
return Weight(root,0);
}
// 给出每一个节点的编码。
private String code(HuffmanNode node,int val,String code){
if(node.val==val&&node.left==null&&node.right==null){
return code+"#";
}
if(node.left!=null){
String str = code(node.left,val,code+"0");
if(str.contains("#")){
return str;
}
}
if(node.right!=null){
String str = code(node.right,val,code+"1");
if(str.contains("#")){
return str;
}
}
return code.equals("")?"":code.substring(0,code.length()-1);
}
public String code(int val){
String code = code(root,val,"");
return code.equals("")?null:code.substring(0,code.length()-1);
}
// 通过编码找到对应的叶子节点
public int decode(String s){
if(s==null){return -1;}
HuffmanNode node = root;
int i = 0;
while (i<s.length()){
if(s.charAt(i)=='0'){
node = node.left;
}else {
node = node.right;
}
++i;
}
return node.val;
}
// 前序遍历
private void DLR(HuffmanNode node) {
if (node == null) {
return;
}
System.out.println(node.val);
DLR(node.left);
DLR(node.right);
}
public void DLR() {
DLR(root);
}
}
class HuffmanNode{
int val;
HuffmanNode left;
HuffmanNode right;
}

















 1678
1678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









