




 Lifelong Language Knowledge Distillation(L2KD)结合知识蒸馏技术,提出了一种在终身学习场景下,不增加模型容量也能有效学习新任务的方法。L2KD在LAMOL模型基础上,通过教师模型指导学生模型,减少遗忘,提高模型在新任务上的表现。教师模型在每个新任务上训练后丢弃,以节省内存。L2KD包括词级、序列级和软序列级的知识蒸馏策略。
Lifelong Language Knowledge Distillation(L2KD)结合知识蒸馏技术,提出了一种在终身学习场景下,不增加模型容量也能有效学习新任务的方法。L2KD在LAMOL模型基础上,通过教师模型指导学生模型,减少遗忘,提高模型在新任务上的表现。教师模型在每个新任务上训练后丢弃,以节省内存。L2KD包括词级、序列级和软序列级的知识蒸馏策略。
链接:http://arxiv.org/abs/2010.02123
简介
Lifelong Language Knowledge Distillation终身语言知识提炼,是一种利用知识蒸馏的终身学习方法。
其主要思想是:每次遇到新任务时,不直接让model去学习,而是先在任务上训练一个teacher model,然后运用知识蒸馏技术,将知识传递给model。
- 知识蒸馏:有两个模型: student model(小)和teacher model(大)。student model需要通过训练,模仿teacher model的行为并使得两者性能相近。
本文将知识蒸馏的思想运用到了终身学习的语言领域。但不同之处在于: L2KD的student model和teacher model是一样大的。
如下图所示。这种方法只需要为每个新任务多花一点时间训练一个一次性teacher model,在学习下一个任务时可以丢弃该模型;因此,L2KD不需要额外的内存或模型容量,这使得提出的模型在实际使用中更有效。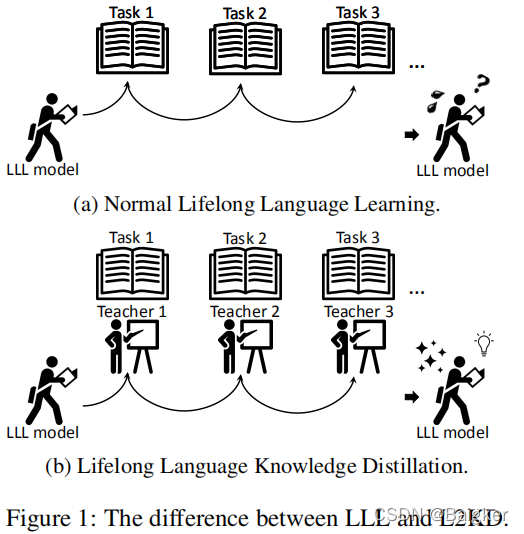
必须要指出的是:L2KD作为一种方法而非具体模型,可以加到大部分LLL模型上去。
因此,本文就将L2KD加到了LAMOL上去。
LAMOL介绍:https://blog.youkuaiyun.com/Baigker/article/details/121650749?spm=1001.2014.3001.5501
Proposed Approach
正如在简介中提到的,L2DK本质是一种知识蒸馏,并且在实际运用中要加到其他模型上去。因此本文也遵循这一顺序,即:先介绍LAMOL,再介绍知识蒸馏,最后才说明L2KD的原理。
LAMOL
在LAMOL的setting中,语言数据集中的所有样本都有三个部分:上下文、问题和答案。我们可以简单地将这三个部分连接成一个句子,并训练模型根据上下文和前面的问题生成答案。
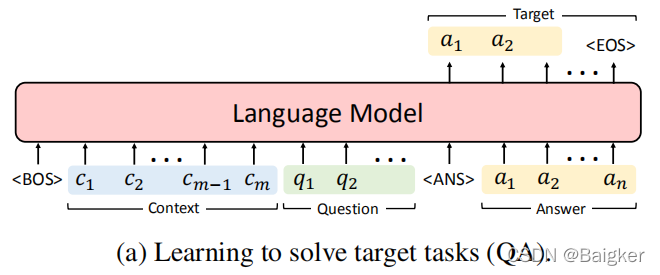
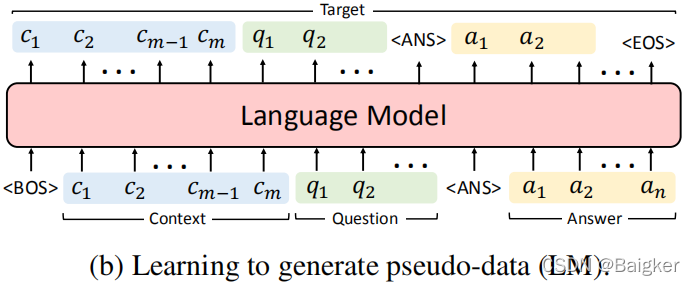
除了生成给定问题的答案外,该模型还可以同时学习对整个训练样本建模。
通过这样做,在训练下一个任务时,模型可以生成前一个任务的样本(被称为伪数据),同时训练新任务的数据和前一个任务的伪数据。
因此,模型在适应新任务时忘记的更少。
知识蒸馏
语言模型
一般来说,语言模型的目标是使预测下一个词时的负对数似然(NLL)最小化: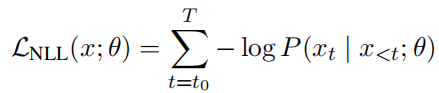
而在知识蒸馏中,我们将student model和teacher model之间的预测误差最小化。
被认为是误差的目标单元可能在单词级或序列级进行。
Word-Level (Word-KD)
在预测下一个词时,我们最小化student和teacher的输出分布之间的交叉熵:
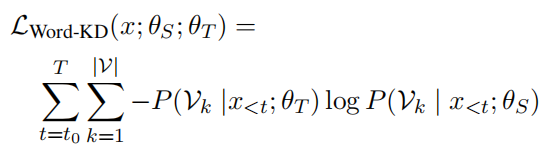
其中输入x<tx_{<t}x<t来自标准答案(ground truth)序列。VVV表示词汇集,VkV_kVk为VVV中的第kkk个单词。
θSθ_SθS和θTθ_TθT分别为学生模型和教师模型的参数。
Sequence-Level (Seq-KD)
我们将teacher model中的贪心解码或beam search输出序列x^\hat xx^<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









