







 本文探讨了模型训练中的误差来源,包括偏差(bias)和方差(variance)。偏差导致欠拟合,可能因模型过于简单;方差导致过拟合,可能因模型过于复杂。解决方案包括增加特征输入、选择更复杂的模型来降低偏差,或通过获取更多数据、使用正则化来减少方差。最终目标是在两者间找到最佳平衡,以最小化总误差。n折交叉验证是评估模型在训练数据上的表现和泛化能力的有效方法。
本文探讨了模型训练中的误差来源,包括偏差(bias)和方差(variance)。偏差导致欠拟合,可能因模型过于简单;方差导致过拟合,可能因模型过于复杂。解决方案包括增加特征输入、选择更复杂的模型来降低偏差,或通过获取更多数据、使用正则化来减少方差。最终目标是在两者间找到最佳平衡,以最小化总误差。n折交叉验证是评估模型在训练数据上的表现和泛化能力的有效方法。
Basic Concept
1.Error
Error 来源于bias(误差,期望歪了)和variance(方差,模型能覆盖的范围)。
bias大:underfitting欠拟合
原因:模型不够复杂,覆盖范围不够广
Variance大:overfitting过拟合
原因:模型太复杂,覆盖范围太大
2.Solution
Bias:
- more feature input
- more complex model
Variance
- more data(最有效,但有时很难实现)
- regularization(使函数变平滑)
数据不够时,可以自己造一些,如:
- 手写识别:调整字的大小,倾斜字体
- 声音识别:用变声器
3.模型选择
在bias和variance中做权衡,最终最小化总误差。
bias和variance的判断方法:符合training data是variance,不符合的是bias。
n折交叉验证
N-fold Cross Validation
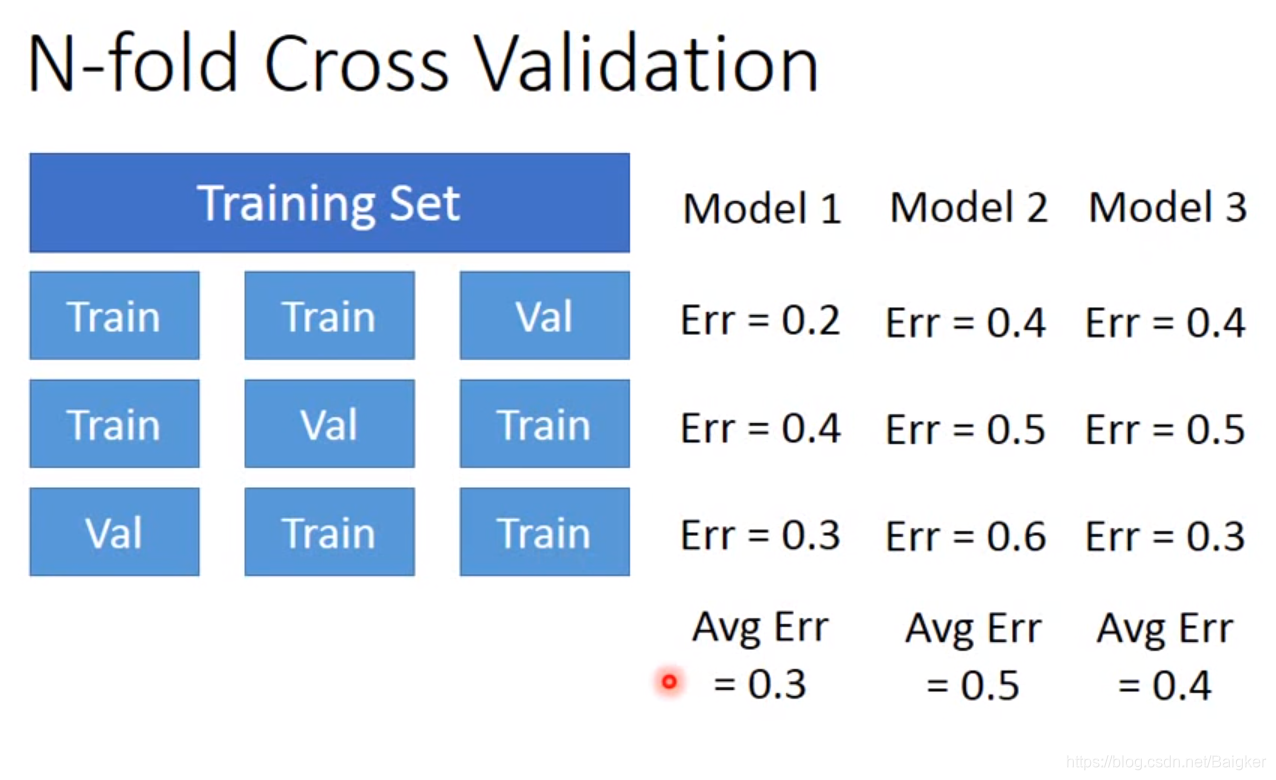
然后选择最好的一个模型,用全部Training Set进行训练。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









