




1. 研究背景
1.1 Embedding 模型在 RAG 中的重要性
检索增强技术(RAG)提供了一种高效地更新领域知识,并且缓解模型幻觉问题的方法。在通常的 RAG 流程中,首先以向量数据库、索引库的形式存储领域知识;在用户提问时,在向量库和索引库中匹配与用户问题相关性最高的知识片段;最后,大模型根据用户问题和检索得到的知识片段,推理归纳并给出回答。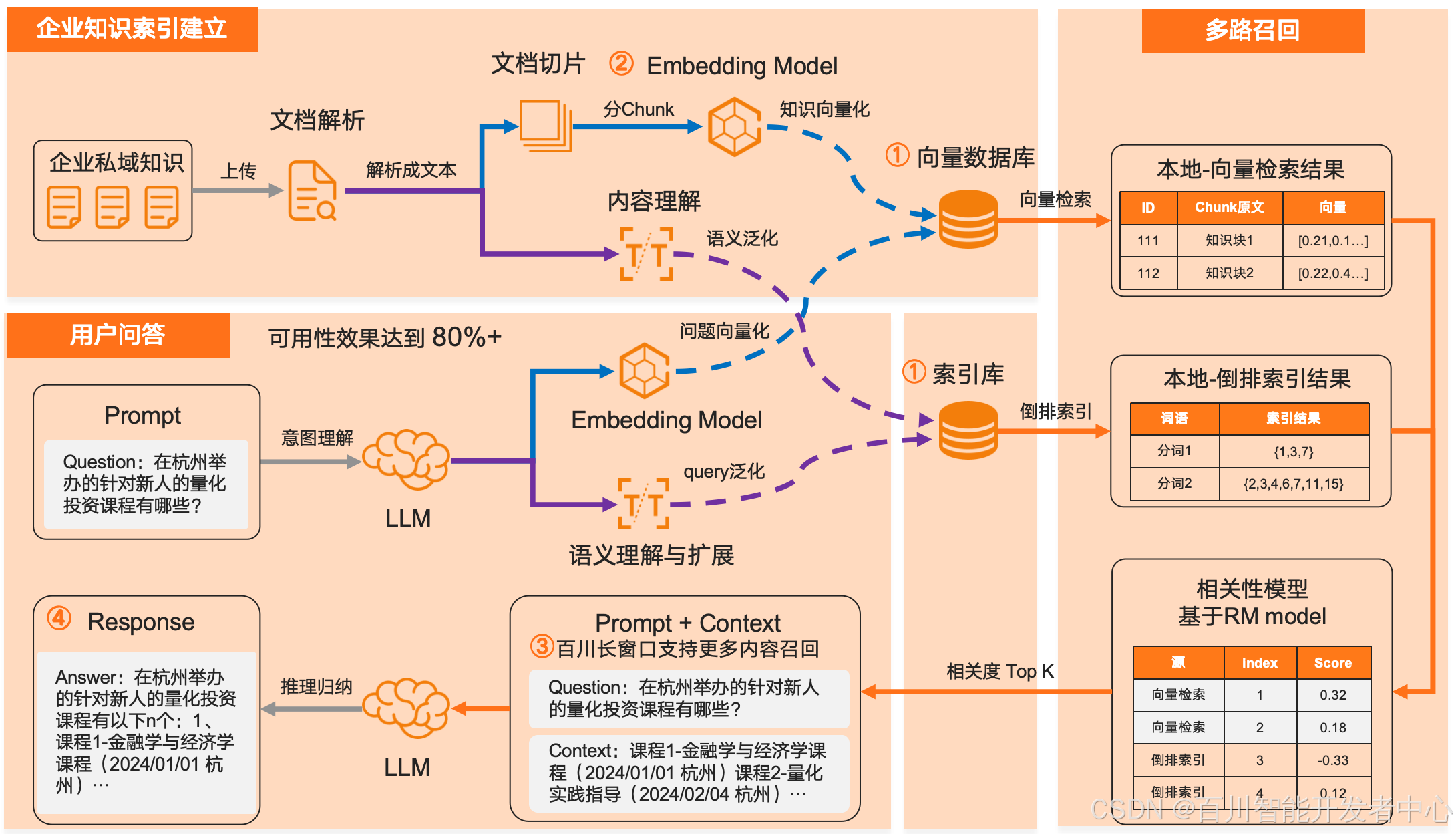
在 RAG 方法中,检索到正确的知识片段是最终能正确回答用户问题的前提。在稠密向量检索过程中,Embedding 模型将知识片段、用户问题转换为向量,通过计算向量间的余弦相似度得到与用户问题相关性最高的知识片段。因此 Embedding 模型决定了稠密向量检索的结果,一个好的 Embedding 模型可以让 RAG 整体效果显著提升。
1.2 真实场景需要增强Embedding模型效果
近年来,Embedding 模型得到学术界和工业界广泛的关注,并发布了一系列优秀的研究工作和开源模型。在众多主流的开源 Embedding 模型中,bge-m3 基于 BERT 模型通过多阶段训练得到,因其较小的参数规模、较长的窗口长度和较强的通用能力被广泛使用;gte 系列模型基于通义千问大模型训练得到,在众多评测集中表现出色;在前沿探索中,基于Mistral大模型训练的 NV-Embd、E5-Mistral 和 bge-icl 等模型在训练中引入了 few-shot 方法和更多的数据处理策略。
但是,以上 Embedding 模型的工作更多关注在通用领域,Embedding 模型还没有学习到企业内部数据和知识,在实际落地实践中效果并不好。比如,在金融领域 Embedding 模型评测集 FinMTEB 中可以发现,当前的主流 Embedding 模型在金融领域 hard 测试集表现一般,相比在通用评测集 MTEB 的平均分数有较大程度下降。在客户场景快速增强 Embedding 模型并提升在领域测试集的效果,是值得研究的课题,也是企业落地 RAG 的重要工作。
2. 48 小时内快速领域增强 Embedding 模型
大模型在医疗、金融、教育、政务等领域有巨大的应用前景,百川智能与行业客户也在这些领域深度打磨产品。在提升产品效果过程中,百川智能逐步探索出 Embedding 模型快速领域增强的通用解决方案。
Embedding 模型领域增强的目标是在领域测试集上效果显著提升,同时要尽量减少在通用测试集上效果的损失,也要控制训练的机器成本并且不需要人工标注训练集。下面将以金融领域增强的 Embedding 模型 FinRet-v1 为例,介绍百川在 Embedding 模型领域增强的实践。
Fi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









