




 本文深入解析Spark中RDD(弹性分布式数据集)的概念,介绍其作为Spark数据处理基石的作用,涵盖转换与行动算子的详细说明,包括map、filter、reduceByKey等常见操作,以及如何利用RDD进行数据处理和分析。
本文深入解析Spark中RDD(弹性分布式数据集)的概念,介绍其作为Spark数据处理基石的作用,涵盖转换与行动算子的详细说明,包括map、filter、reduceByKey等常见操作,以及如何利用RDD进行数据处理和分析。
RDD
RDD(Resilient Distributed Dataset)即弹性分布式数据集。
RDD是spark的基石,是实现spark数据处理的核心抽象。是spark中最基本的数据抽象,它代表一个不可变,可分区,里面的元素可并行计算的集合。
RDD是基于工作集的工作模式,更多的是面向工作流。
RDD支持两种类型的操作:转换(从现有操作创建新的数据集)和动作(在操作数据集上进行计算后,将值返回给驱动程序)。
spark使用的是惰性计算模式,像scala里的懒加载一样,RDD第一次在行动操作中才会被正真计算。
Transformations(转换算子)
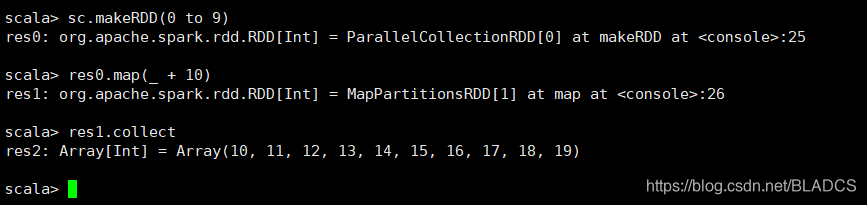
1.map(func)
官网api:返回一个新的分布式数据集,该数据集是通过将源的每个元素传递给函数func形成的。
返回的是一个旧RDD里的元素经过func函数处理后新的集合(RDD)。
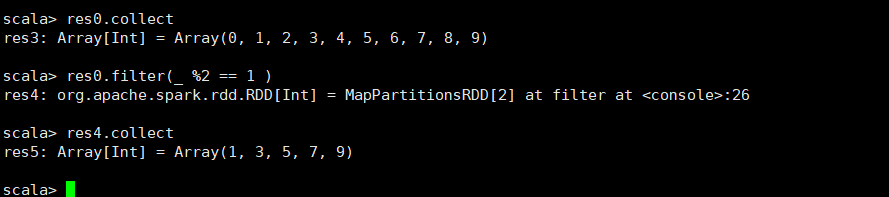
2.filter(func)
api:返回一个新的数据集,该数据集是通过选择源中func返回true的那些元素形成的。
旧RDD通过func函数返回为真的集合RDD。
3.flatMap(func)
api:与map相似,但是每个输入项都可以映射到0个或多个输出项(因此func应该返回Seq而不是单个项)。
func返回的是一个序列。

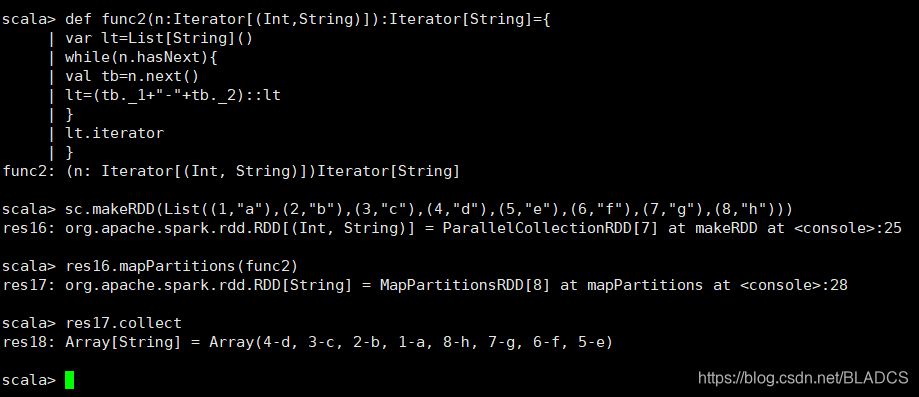
4.mapPartitions(func)
api:与map相似,但是分别在RDD的每个分区(块)上运行,因此func在类型T的RDD上运行时必须为Iterator => Iterator < U >类型。
独立的在RDD的每一个分区运行,有多少个分区mapPartitions(func)就被调用多少次。
def func2(n:Iterator[(Int,String)]):Iterator[String]={
var lt=List[String]()
while(n.hasNext){
val tb=n.next()
lt=(tb._1+"-"+tb._2)::lt
}
lt.iterator
}
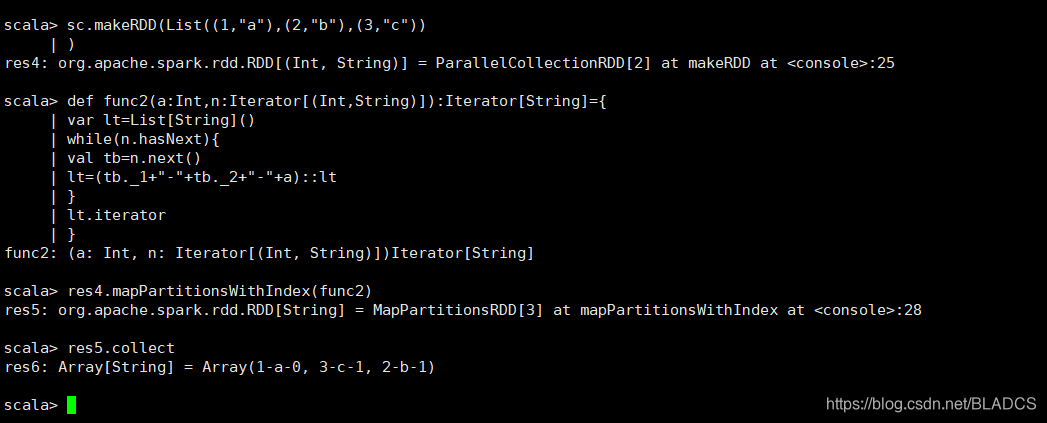
5.mapPartitionsWithIndex(func)
api:与mapPartitions相似,但它还为func提供表示分区索引的整数值,因此当在类型T的RDD上运行时,func必须为(Int,Iterator < T >)=> Iterator < U >类型。
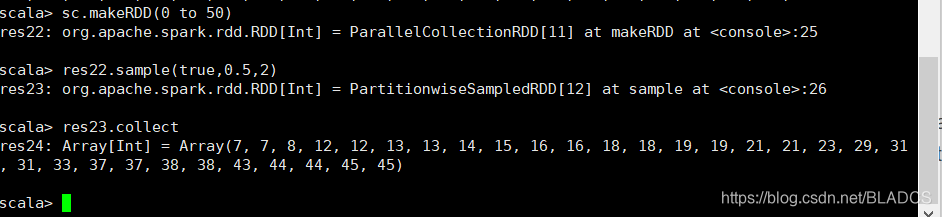
6.sample(withReplacement,fraction,seed)
api:试分数分数的数据的/样本分数数据的分数(Sample a fraction fraction of the data)(卒~),具有或不具有替换,使用给定的随机数发生器的种子。
withReplacement:是否放回抽样。fraction随机抽样的数量。seed随机数的种子。
7.union(otherDataset)
api:返回一个新的数据集,其中包含源数据集中的元素和参数的并集。
对旧RDD和传进的RDD经行求并集。

8.intersection(otherDataset)
api:返回一个新的RDD,其中包含源数据集中的元素和参数的交集。
对于旧RDD和传进的RDD进行求交集。

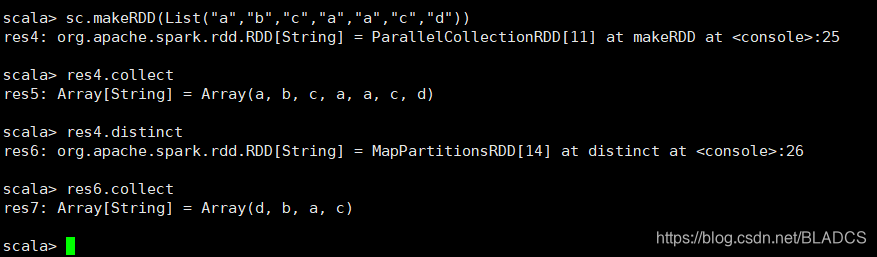
9.distinct([numPartitions]))
api:返回一个新的数据集,其中包含源数据集的不同元素。
去重。numPartitions:是分区数。
10.groupByKey([numPartitions])
api:在(K,V)对的数据集上调用时,返回(K,Iterable )对的数据集。
注意:如果要分组以便对每个键执行聚合(例如求和或平均值),则使用reduceByKey或aggregateByKey将产生更好的性能。
注意:默认情况下,输出中的并行度取决于父RDD的分区数。您可以传递一个可选numPartitions参数来设置不同数量的任务。
对key经行操作,将key经行聚合。

11.reduceByKey(func, [numPartitions])
api:在(K,V)对的数据集上调用时,返回(K,V)对的数据集,其中每个键的值使用给定的reduce函数func进行汇总,该函数必须为(V,V)=> V.与in一样groupByKey,reduce任务的数量可以通过可选的第二个自变量配置。
使用func函数,对key进行聚合。
12.aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions])
api:在(K,V)对的数据集上调用时,返回(K,U)对的数据集,其中每个键的值使用给定的Combine函数和中性的“零”值进行汇总。允许与输入值类型不同的聚合值类型,同时避免不必要的分配。像in中一样groupByKey,reduce任务的数量可以通过可选的第二个参数进行配置。
对value,经行操作。

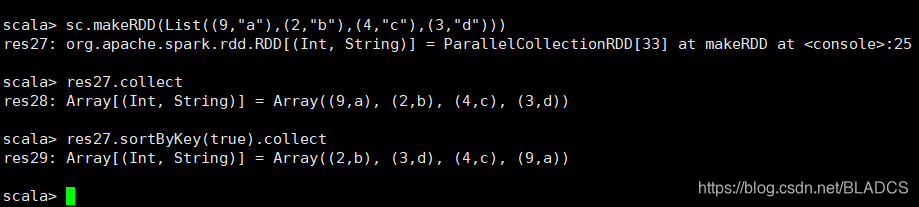
13.sortByKey([ascending], [numPartitions])
api:在由K实现Ordered的(K,V)对的数据集上调用时,返回(K,V)对的数据集,按布尔值指定,按键以升序或降序排序ascending。
对RDD进行排序。
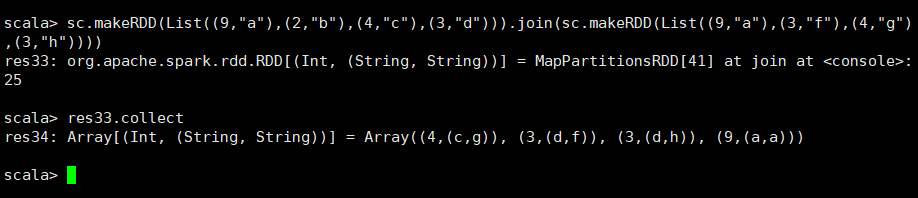
14.join(otherDataset, [numPartitions])
api:在(K,V)和(K,W)类型的数据集上调用时,返回(K,(V,W))对的数据集,其中每个键都有所有成对的元素。外连接通过支持leftOuterJoin,rightOuterJoin和fullOuterJoin。
对旧RDD加入传入的RDD
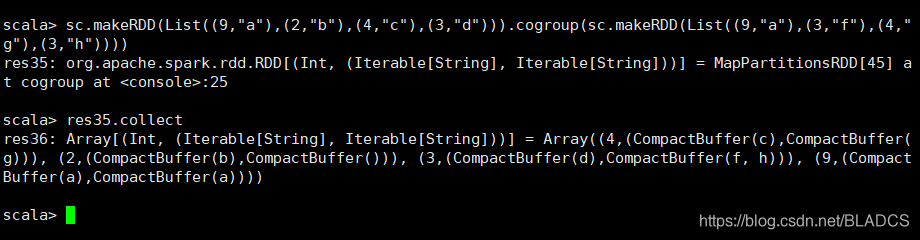
15.cogroup(otherDataset, [numPartitions])
api:在(K,V)和(K,W)类型的数据集上调用时,返回(K,(Iterable ,Iterable ))元组的数据集。此操作也称为groupWith。
对传入RDD进行V和M操作。
16.cartesian(otherDataset)
api:在类型T和U的数据集上调用时,返回(T,U)对(所有元素对)的数据集。

17.pipe(command, [envVars])
api:通过外壳命令(例如Perl或bash脚本)通过管道传输RDD的每个分区。将RDD元素写入进程的stdin,并将输出到其stdout的行作为字符串的RDD返回。
18.coalesce(numPartitions)
api:将RDD中的分区数减少到numPartitions。筛选大型数据集后,对于更有效地运行操作很有用。

19.repartition(numPartitions)
api:在RDD中随机重排数据以创建更多或更少的分区,并在整个分区之间保持平衡。这总是会通过网络重新整理所有数据。

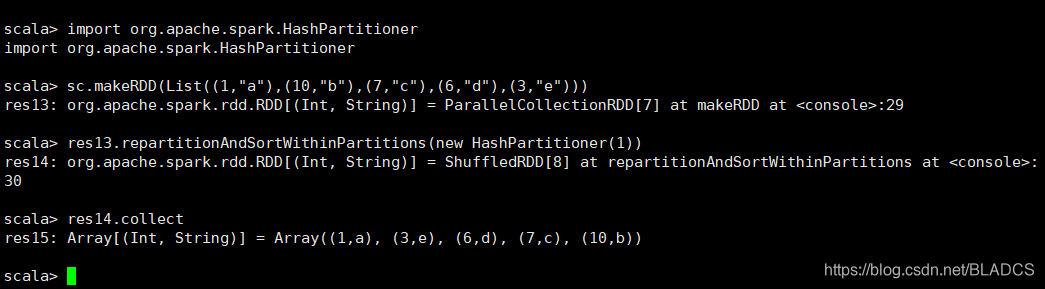
20.repartitionAndSortWithinPartitions(partitioner)
api:根据给定的分区程序对RDD重新分区,并在每个结果分区中,按其键对记录进行排序。这比repartition在每个分区内调用然后排序更为有效,因为它可以将排序推入洗牌机制。
Action(行动算子)
1.reduce(func)
api:使用函数func(使用两个参数并返回一个参数)聚合数据集的元素。该函数应该是可交换的和关联的,以便可以并行正确地计算它。
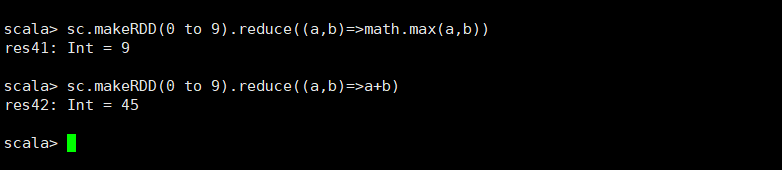
2.collect()
api:在驱动程序中将数据集的所有元素作为数组返回。这通常在返回足够小的数据子集的过滤器或其他操作之后很有用。
3.count()
api:返回数据集中的元素数。

4.first()
api:返回数据集的第一个元素(类似于take(1))。

5.take(n)
api:返回具有数据集的前n个元素的数组。

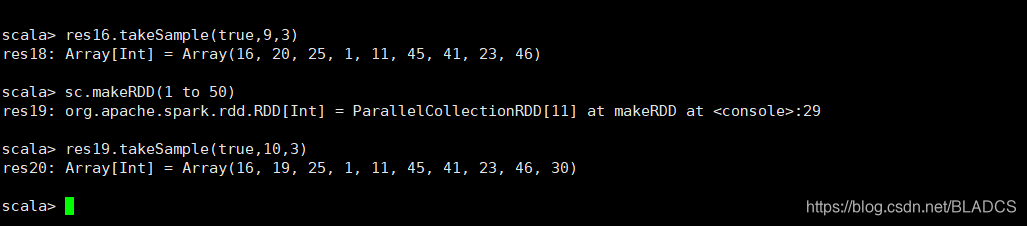
6.takeSample(withReplacement, num, [seed])
api:返回带有数据集num个元素的随机样本的数组,带有或不带有替换,可以选择预先指定一个随机数生成器种子。
7.takeOrdered(n, [ordering])
api:使用自然顺序或自定义比较器返回RDD 的前n个元素

8.saveAsTextFile(path)
api:将数据集的元素以文本文件(或文本文件集)的形式写入本地文件系统,HDFS或任何其他Hadoop支持的文件系统中的给定目录中。Spark将在每个元素上调用toString,以将其转换为文件中的一行文本。

9.saveAsSequenceFile(path)
api:在本地文件系统,HDFS或任何其他Hadoop支持的文件系统的给定路径中,将数据集的元素作为Hadoop SequenceFile写入。这在实现Hadoop的Writable接口的键/值对的RDD上可用。在Scala中,它也可用于隐式转换为Writable的类型(Spark包括对基本类型(如Int,Double,String等)的转换)。
10.saveAsObjectFile(path)
api:使用Java序列化以简单的格式编写数据集的元素,然后可以使用进行加载 SparkContext.objectFile()。
11.countByKey()
api:仅在类型(K,V)的RDD上可用。返回(K,Int)对的哈希图以及每个键的计数。

12.foreach(func)
api:在数据集的每个元素上运行函数func。通常这样做是出于副作用,例如更新累加器或与外部存储系统交互。
注意:在之外修改除累加器以外的变量foreach()可能会导致不确定的行为。有关更多详细信息,请参见了解闭包。

官网指南
这篇是我的学习笔记,参考了官网原文。
官网RDD编程指南https://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-distributed-datasets-rdds

















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









