




- 了解大厂经验
- 拥有和大厂相匹配的技术等
希望看什么,评论或者私信告诉我!
一、前言
线上实时任务,通过 FlinkSQL 关联 Iceberg 维表,维表大搞有 60w,首先通过 FlinkSQL关联 Iceberg 维表上线了,经过一番调优后:TaskManager Memory 给到了 16G,但通过监控可以轻易的发现 Heap 没下来过 10GB
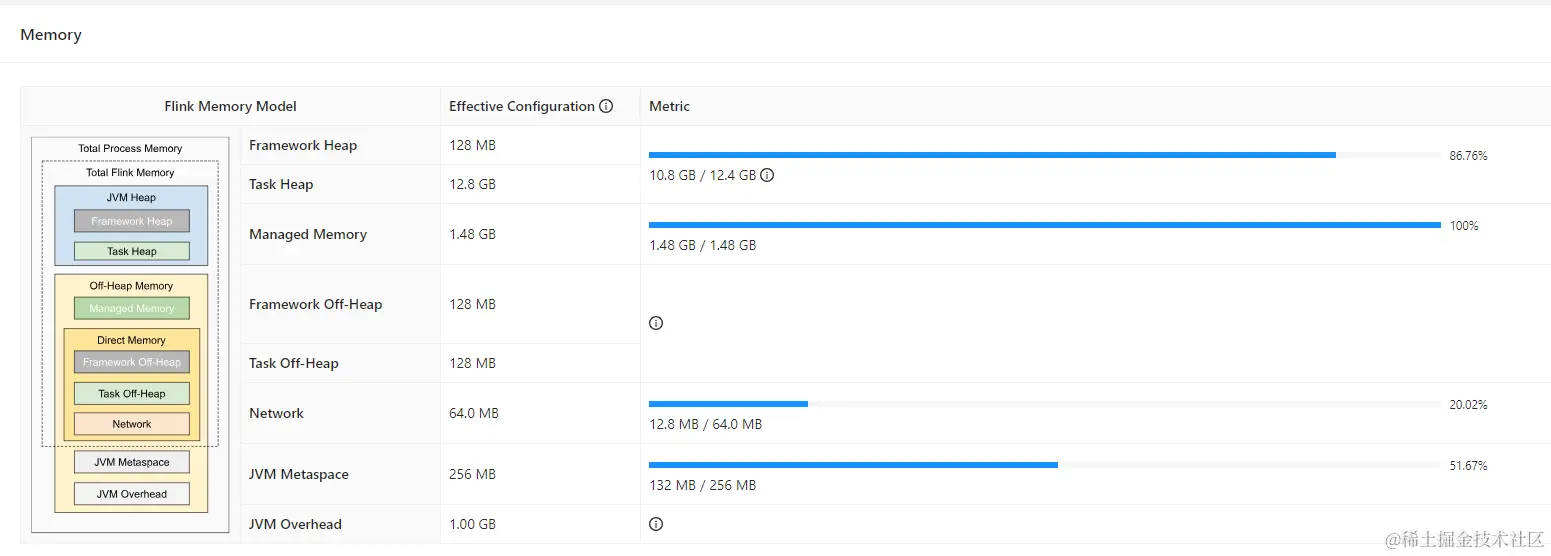
二、优化
2.1 分析 Iceberg lookup 部分源码
因为 Iceberg 的 lookup 是公司内部自己实现的,就不贴源码了,但核心一点就是,look up 维表 cache 的数据会存在内存中,这就是为什么堆内存没有下来过 10GB
2.2 切换到 paimon 维表
TaskManager Memory 给到了 4G,程序运行的轻轻松松,另外为了增加 rocksdb 性能,也适当的增加了 rocksdb 的内存
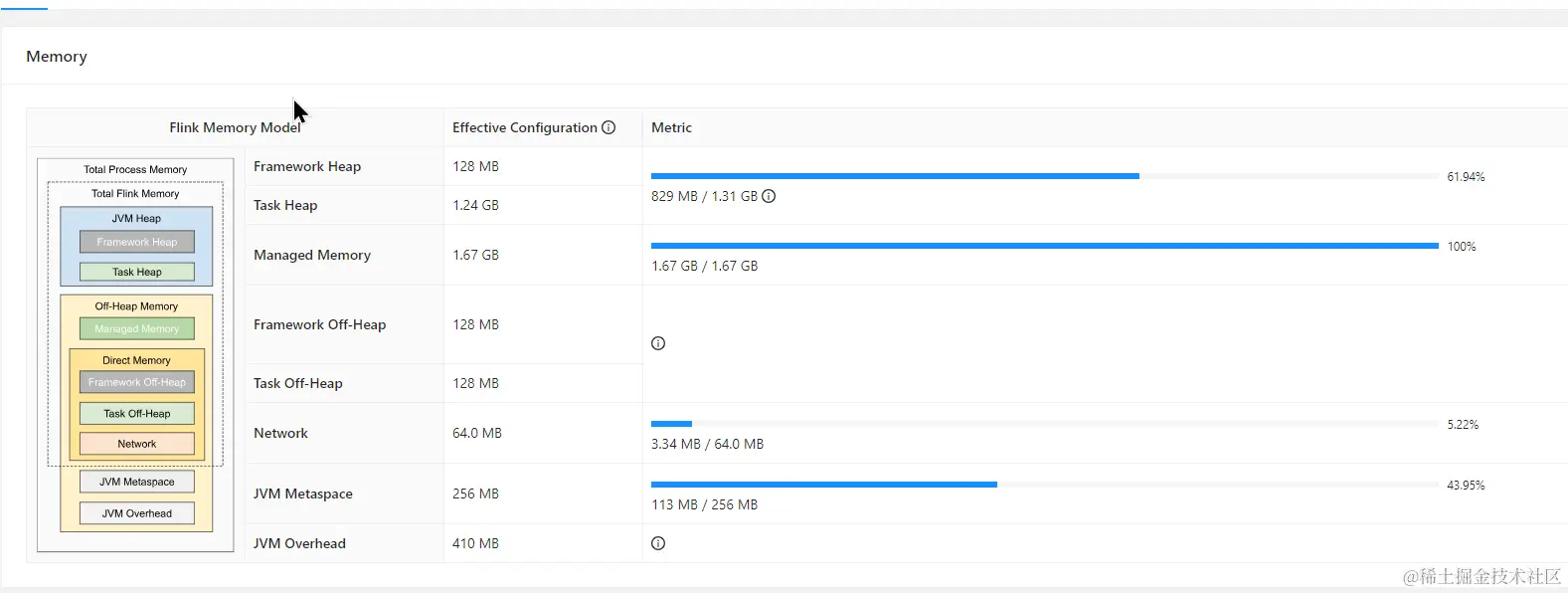
为了替换 paimon 后内存可以下降那么多呢?
2.3 paimon 维表原理分析
首先来看一下 FlinkSQL look up paimon 的维表的源码,这里我们以 flink1.15 为例。 下载完 paimon 源码后,找到 moudle paimon-flink-1.15
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









