 RAGLAB:检索增强生成统一框架研究
RAGLAB:检索增强生成统一框架研究





论文信息
论文标题:RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation - EMNLP 24
论文作者:Xuanwang Zhang - Nanjing University
论文链接:https://arxiv.org/abs/2408.11381
代码链接:https://github.com/fate-ubw/RAGLab
论文关键词:RAG
研究背景
1.大型语言模型(LLMs)的挑战
尽管LLMs在对话、推理和知识保留方面表现出接近人类的能力,但其仍面临以下瓶颈:
- 幻觉问题 (Hallucinations):生成内容可能与事实不符;
- 知识实时更新困难 :模型参数固定后难以动态更新知识;
- 私有数据保护需求 :需在不存储参数化知识的情况下实现外部知识调用。
2.检索增强生成(RAG)的兴起
RAG技术通过为LLMs配备外部知识库,成为缓解上述问题的有效方案。然而,现有RAG算法存在以下局限性:
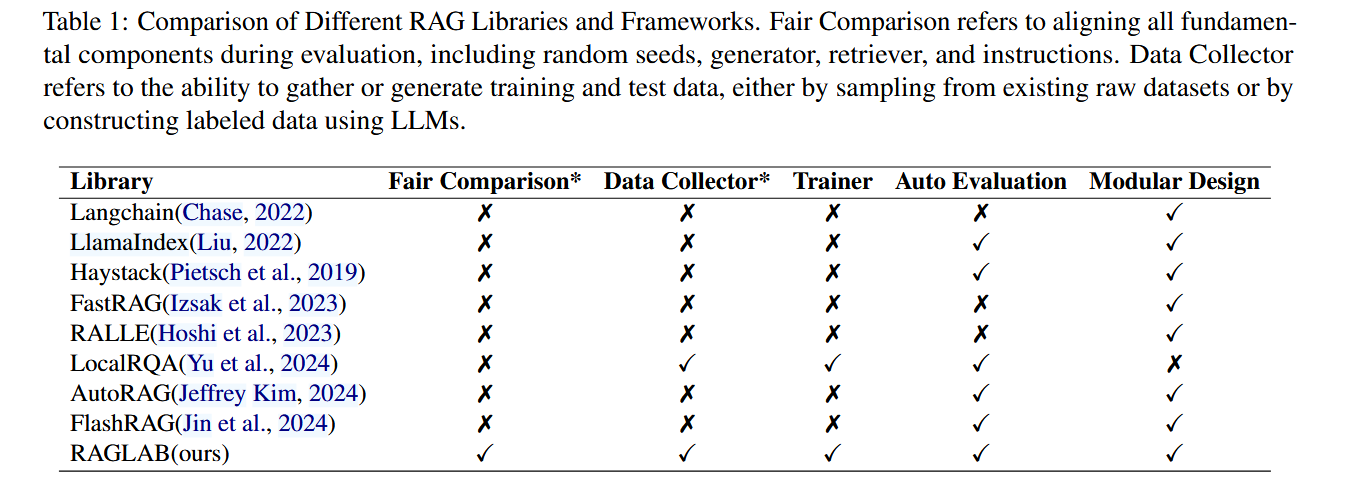
- 缺乏公平比较 :不同算法的实现组件(如检索器、生成器、指令模板)差异显著,导致实验结果难以横向对比;
- 开源工具透明度不足 :如LlamaIndex和LangChain采用高度封装的设计,限制了新算法开发和评估指标的扩展。
3.研究目标
作者提出RAGLAB ,旨在解决以下问题:
- 提供模块化框架以支持灵活配置;
- 构建标准化实验环境以实现算法公平比较;
- 简化新算法开发流程并支持高效训练与评估。
主要贡献
- 模块化架构设计: 将RAG系统拆分为Retriever、Generator、Instruction Lab等独立组件,支持灵活替换与组合
- 公平比较平台: 首次在统一实验条件下(相同检索器、知识库、指令模板)对比6种主流RAG算法(NaiveRAG、RRR、ITER-RETGEN、Active RAG、Self-Ask、Self-RAG)
- 交互式模式与训练支持: 提供交互式接口(如5行代码快速部署)、LoRA/QLoRA微调技术集成,支持70B参数模型训练
- 预处理数据集与评估体系: 提供Wikipedia 2018/2023语料库及索引,集成Factscore、ALCE等先进评估指标
- 开源生态建设: 开源代码、处理脚本及用户文档,推动社区协作与算法迭代
框架结构与核心组件
系统架构
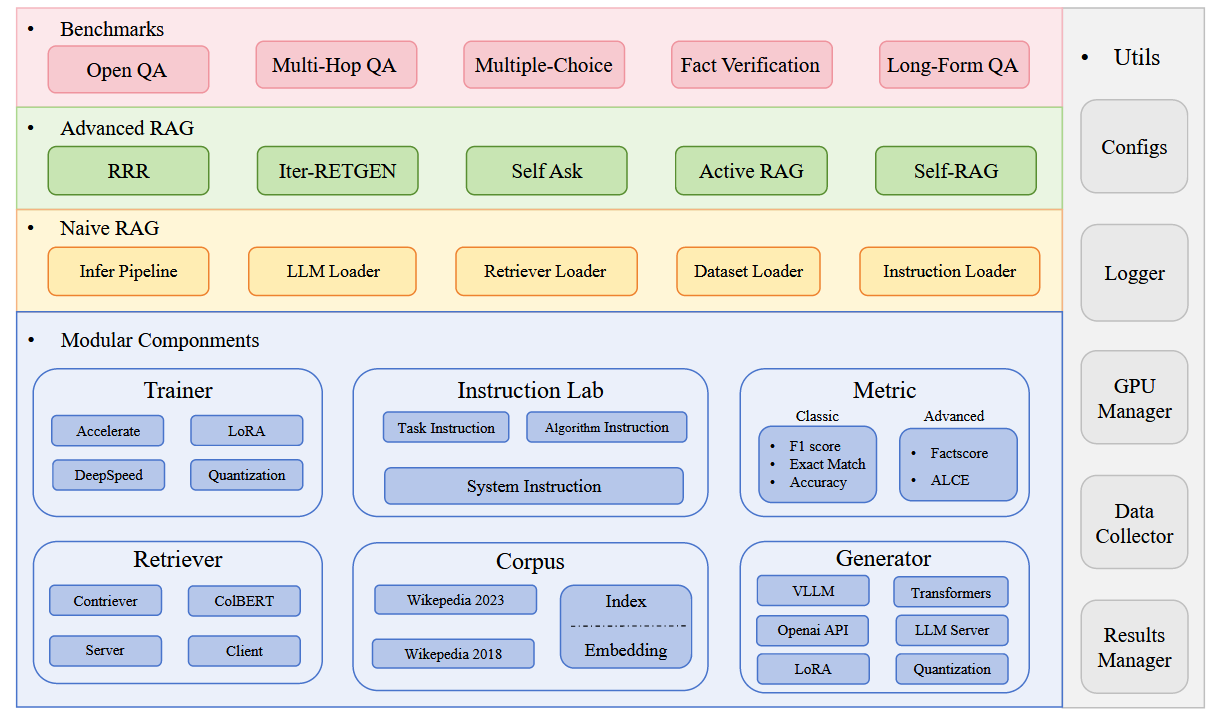
RAGLAB旨在提供一个模块化、研究导向、可复现且支持公平比较的RAG实验平台,其核心组件如下
:
- Retriever(检索器):集成 Contriever 与 ColBERT 两种高性能模型,统一查询接口,并设计检索服务器/客户端架构及检索结果缓存,支持并行高并发访问与快速复用检索结果(<0.1s);
- Corpus(语料库):提供预处理后的 Wikipedia 2018 与 2023 数据集,包含对应的索引与嵌入,且开源处理脚本,便于用户替换或扩展知识库 ;
- Generator(生成器):兼容HuggingFace Transformers、VLLM和OpenAI API,支持量化(Quantization)与LoRA微调;
- Instruction Lab(其实就是 Prompt pool) :将 System、Task、Algorithm 三类指令分离管理,用户可自由组合与调参,确保不同算法间指令对齐,从而实现公平比较;
- Trainer(微调器):基于 Accelerate 与 DeepSpeed,支持 LoRA、QLoRA 以及在微调中添加特殊 token,方便复现带特殊标记的算法;
- Dataset & Metric(数据集与指标) :覆盖10个基准任务(OpenQA、多跳问答等),提供经典(F1、ACC)与前沿(Factscore、ALCE)评估指标。
复现的 RAG 算法
RAGLAB 内置并复现六种经典RAG算法:
-
Naive RAG
-
RRR (Query Rewriting)
-
ITER-RETGEN (Iterative Retrieval-Generation)
-
Self-Ask
-
Active RAG
-
Self-RAG
每种算法均封装为独立类,用户仅需继承NaiveRAG、重写 __init__和 infer 方法,即可实现新算法开发,且框架自带交互与评估功能,只需 5 行脚本即可运行 。
如何使用RAGLAB 去快速复现和评估一个 RAG算法。

如何使用 RAGLAB 去设计一个新的RAG算法。(RAGLAB 中的RAG算法都是基于 Naive RAG 进行修改得到的)

实验设计与结果分析
实验设置
- 基线模型 :Llama3-8B(全量微调)、Llama3-70B(QLoRA微调)、GPT-3.5(无Self-RAG);
- 知识库 :Wikipedia 2018(ColBERT检索器);
- 评估任务 :涵盖OpenQA、多跳问答、多选题等10个基准(表2);
- 控制变量 :固定随机种子、采样策略、检索文档数(N Docs=10)及生成长度(Max Length=300)。
三组实验
-
Experiment 1:基础模型 Llama3-8B,使用 Self-RAG 数据微调得到 selfrag-llama3-8B ;对比模型 llama3-8B-baseline 全权重微调 。
-
Experiment 2:基础模型 Llama3-70B,采用 QLoRA 微调分别得到 selfrag-llama3-70B 与 llama3-70B-baseline 。
-
Experiment 3:基础模型 GPT-3.5,因闭源限制未包含 Self-RAG 算法 。
每组实验抽样 500 条数据,计算多项指(Accuracy、F1、FactScore、ALCE) 。
实验结果和讨论
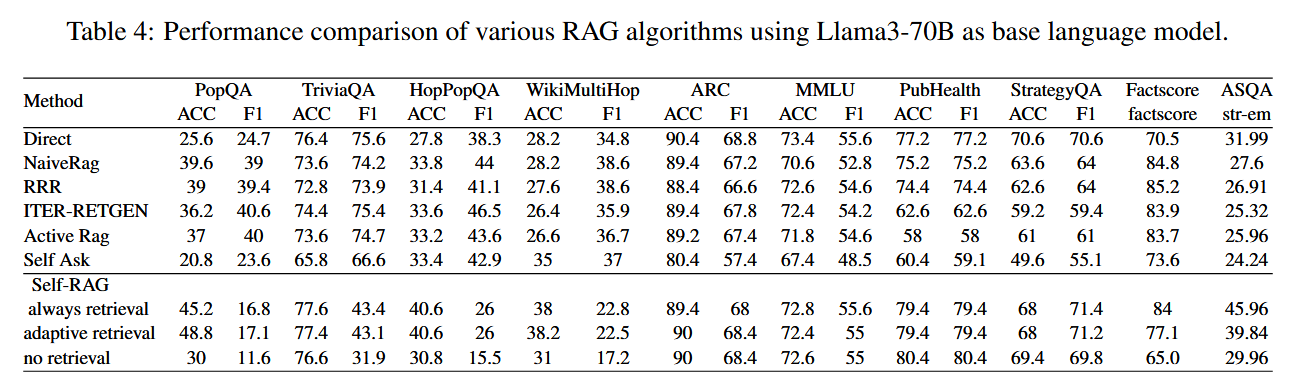
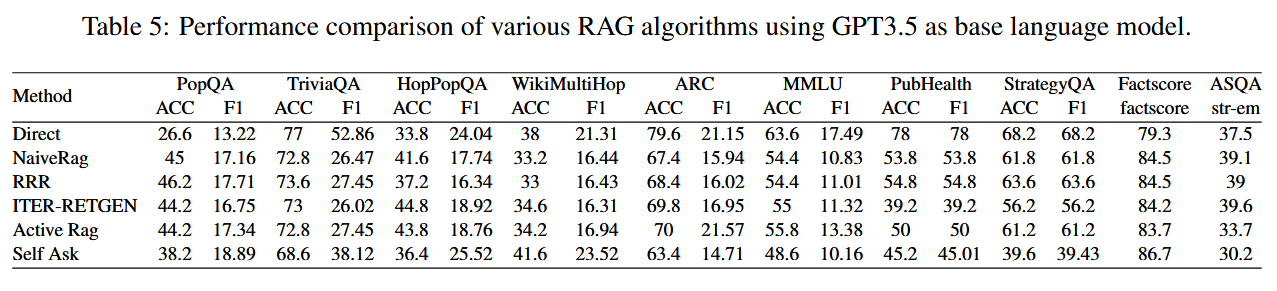
-
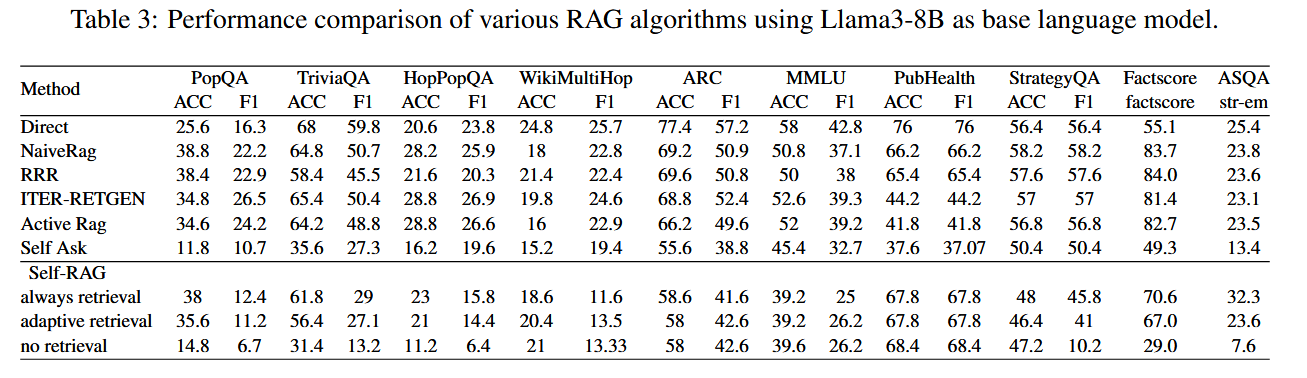
Self-RAG 性能提升。 在 8B 规模上,selfrag-llama3-8B 并未显著超越其他算法;但在 70B 规模上,selfrag-llama3-70B 几乎在所有 10 个基准上表现领先,FactScore 达到最高 。
-
迭代检索对多跳QA的贡献。 ITER-RETGEN 在 Multi-HopQA 任务(如 HotpotQA、2WikiMultiHopQA)中表现尤为突出,说明多轮检索与生成协同有助于复杂推理 。
-
多选题场景下直问优势。 在 ARC、MMLU 等多选任务中,直接使用 LLM(Direct)往往优于 RAG,可能因检索内容干扰了候选答案列表,导致生成模型被误导 。
-
其他算法比较。 Naive RAG、RRR、Active RAG 四者总体表现相近,表明在相同生成器与检索器设置下,简单的检索增强已能带来相似提升 。
用户研究
参与者: 20 名至少使用 RAGLAB 三天的 NLP 研究者
调查结果:
-
85% 认为 RAGLAB “显著提高研究效率”
-
90% 愿意推荐给他人
-
收集了关于界面、扩展性等方面的改进建议,将用于后续迭代 。
用户评价与局限性
总结
贡献:
-
提出第一个兼顾模块化、透明度与复现性的统一 RAG 框架,支持公平比较与快速算法开发
-
综合评估了 6 种算法在 10 个基准上的性能,提供了多项有价值洞见。
局限与未来工作:
-
当前仅复现 6 种算法、10 个基准,后续将持续跟进新算法与更多数据集
-
将探索更多检索器与知识库组合对性能的影响
-
扩展对资源消耗与推理时延的全面评估指标

















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









