




目录
2.3 梯度消失与梯度爆炸
2.5.1 双向RNNs(Bidirectional RNNs)
一、基础知识
1.1 如何用数据表示文字(语义建模方法)
一般有独热编码(One-hot Encoding)和词嵌入(Word Embedding)两种方法。
1.1.1 独热编码(One-hot Encoding)
这是一个比较朴素的思想,将每个字表示为一个高维稀疏向量,其中只有对应类别的位置为1,其余为0,但缺点也是显而易见的,如图。

通俗来说就是像给每个学生分配唯一的学号(如2023001),仅用于标识身份,无法反映学生之间的关系。
1.1.2 词嵌入(Word Embedding)
将单词映射到低维稠密向量,向量中的每个值表示某种潜在语义特征。

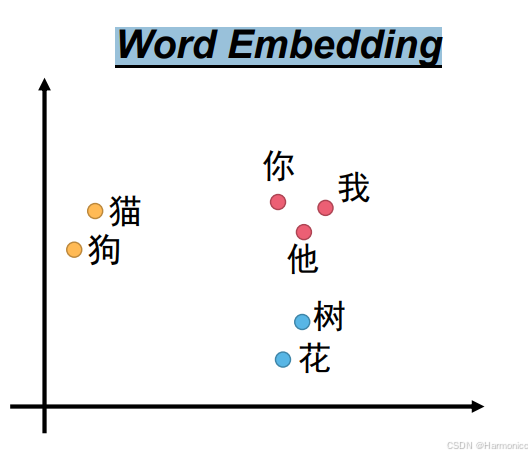
通俗来说像根据学生的兴趣、成绩、性格等生成一份“综合档案”,档案相似的学生可能有共同点(如都喜欢玩原神)。
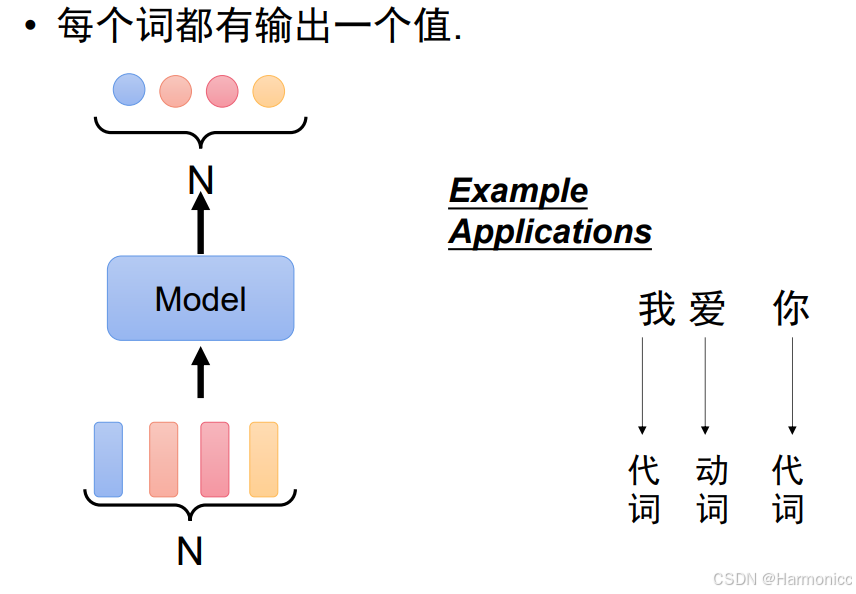
1.2 输入文字常见的三种输出
- 每个输出对应一个值
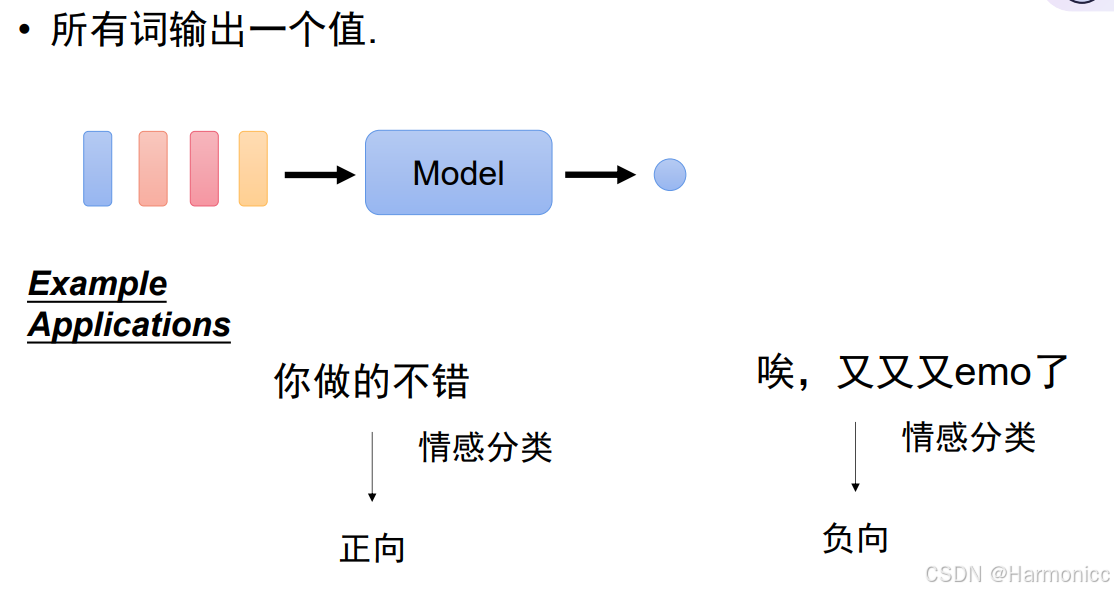
- 所有词输出一个值
- 输入输出长度不对应
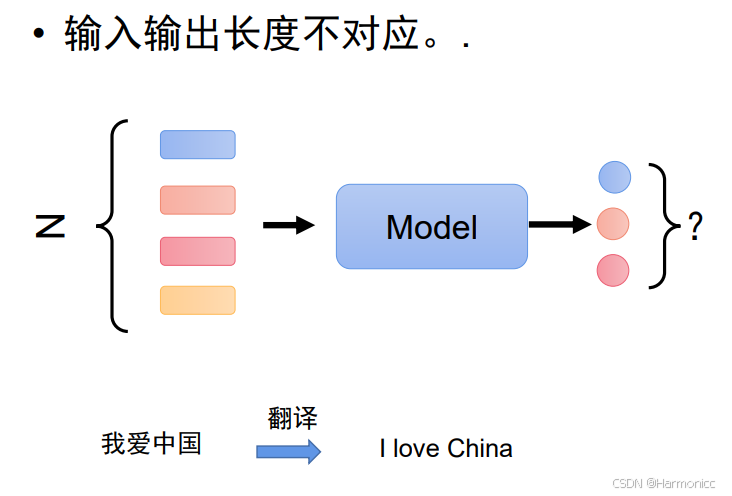
本节概论只说前两种,后一种在生成任务细说。
二、序列数据处理模型
2.1 LM(语言模型)
语言模型(language models)是NLP的基础技术之一,我们给出以下两种定义:


就定义一我们可以很简单举个例子:
2.1.1 N-gram语言模型
所谓的N-gram,就是指一堆连续的词,根据这一堆词的个数,我们可以分unigram,bigram,trigram等等。如果我们需要得到一个N-gram的LM,它的意思就是希望我们可以通过N-1个词预测第N个词的概率。那么如何学习得到一个N-gram的LM呢?一个直接的思路就是,我们可以收集关于语料中的各个N-gram出现的频率信息。
比如我们想得到一个3-gram的LM,那么就是说想预测一段文本的下一个词是什么的话,只用看这个词前面2个词即可。
举个例子

LM的几个缺陷:

2.2 RNN(循环神经网络)
一图搞懂RNN
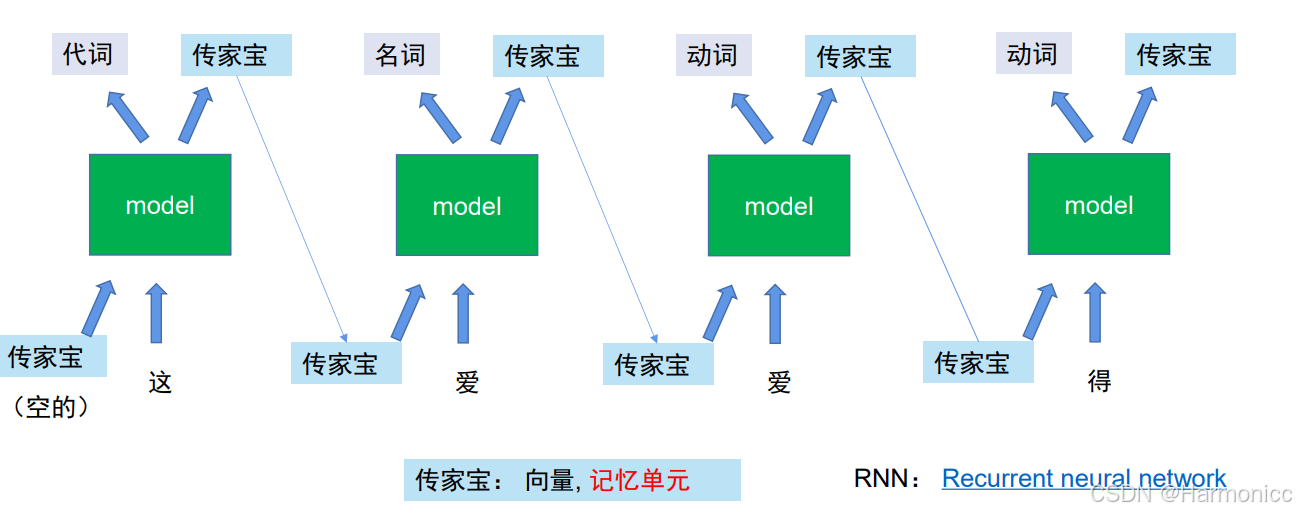
- 绿色 “model” 单元:代表 RNN 的一个处理单元,依次处理序列中的每个元素(如词语)。每个单元接收当前输入(如 “这”“爱”“得”)和前一时刻的记忆(“传家宝”),输出当前元素的属性(如词性:代词、名词、动词)。
- 输入与输出:
- 第一个单元处理 “这”,输出为 “代词”。
- 第二个单元处理 “爱”,输出为 “名词”;第三个单元再次处理 “爱”,结合记忆输出为 “动词”;第四个单元处理 “得”,输出为 “动词”。
- 这种变化体现了 RNN 根据上下文(通过记忆单元传递信息)动态判断词语属性的能力。
最主要的idea——
3.“传家宝”(记忆单元):图中 “传家宝” 表示 RNN 的记忆向量,用于保存序列中先前元素的信息。例如,处理后续词语时,会结合之前传递的 “记忆”,使模型能感知上下文。如不同位置的 “爱” 因上下文不同(通过记忆单元传递的信息),被判断为不同词性(名词或动词)。
本质上就是可以利用“传家宝”处理词性不同的问题,但RNN有个弊端就是在处理长距离依赖时,因记忆传递不畅而容易丢失关键信息的缺陷,无法很好地捕捉和利用远距离的上下文关联。

更严谨的定义解释
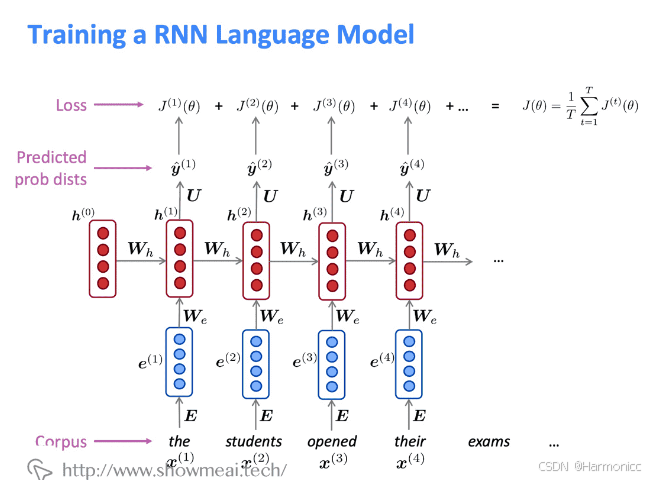



这玩意其实就是上面说的传家宝

RNN的loss

RNN的评价指标

2.3 梯度消失与梯度爆炸

可以看出,「当W很小或者很大,同时i和j相差很远的时候」,由于公式里有一个「指数运算」,这个梯度就会出现异常,变得超大或者超小,也就是所谓的“梯度消失/梯度爆炸”问题。
为什么梯度消失是个问题?
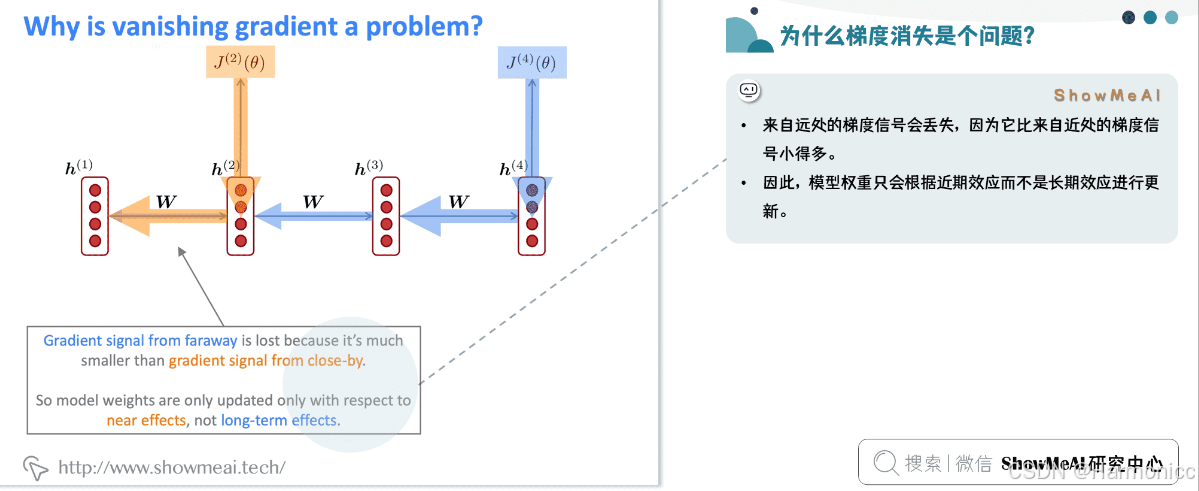
这样会导致RNN模型无法在测试时预测类似的长距离依赖关系
为什么梯度爆炸是个问题?
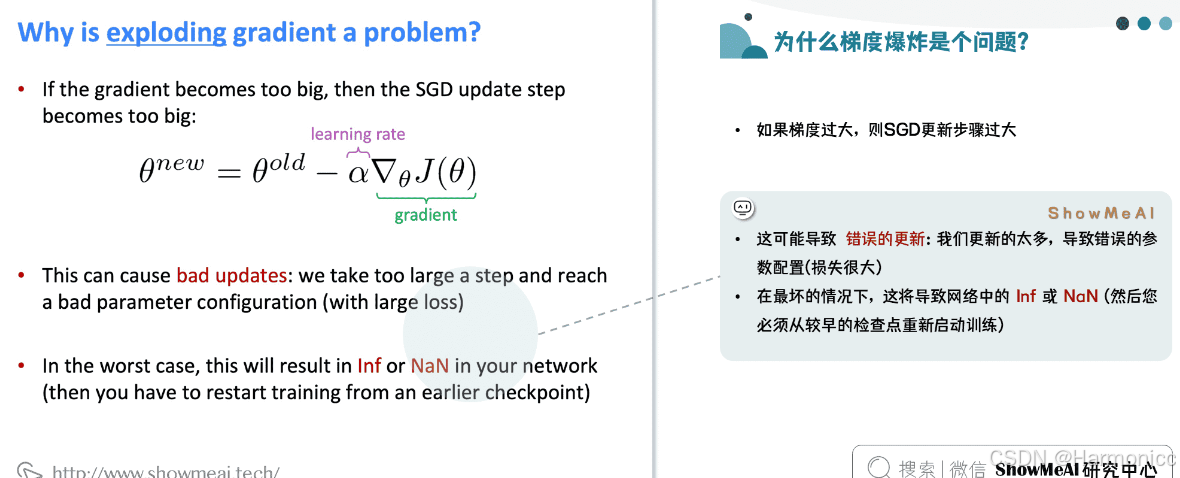
会导致在梯度下降的时候,每一次更新的步幅都过大,这就使得优化过程变得十分困难。
如何解决梯度爆炸?
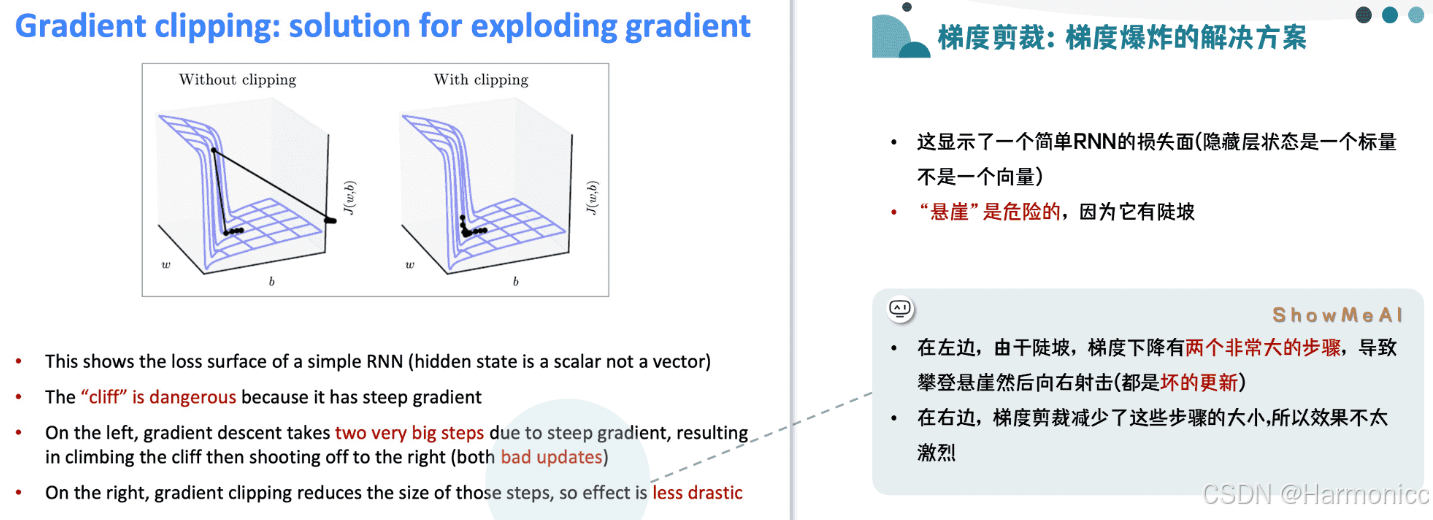
实际上剪裁的核心是限制梯度向量的模长(Norm),并非’磨光‘

如何解决梯度消失?
这就引出了2.3的LSTM
2.3 LSTM(长短期记忆网络)
一图搞懂LSTM
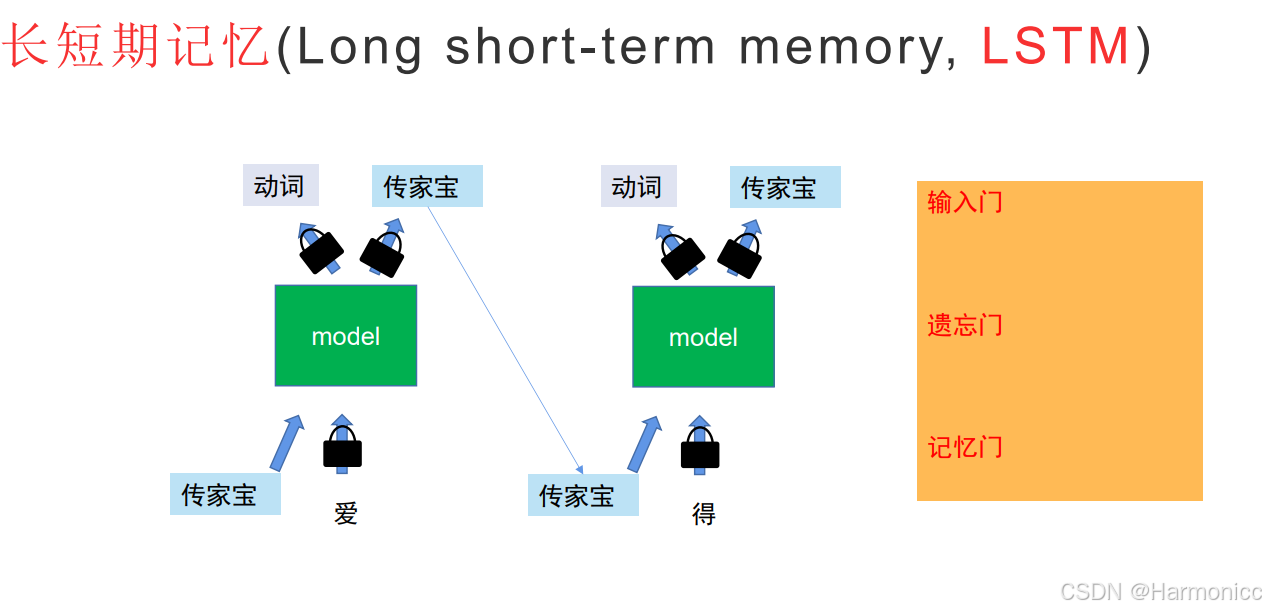

主要是有门控机制做决策官。
同样,我们对LSTM给出更加严谨的定义解释:
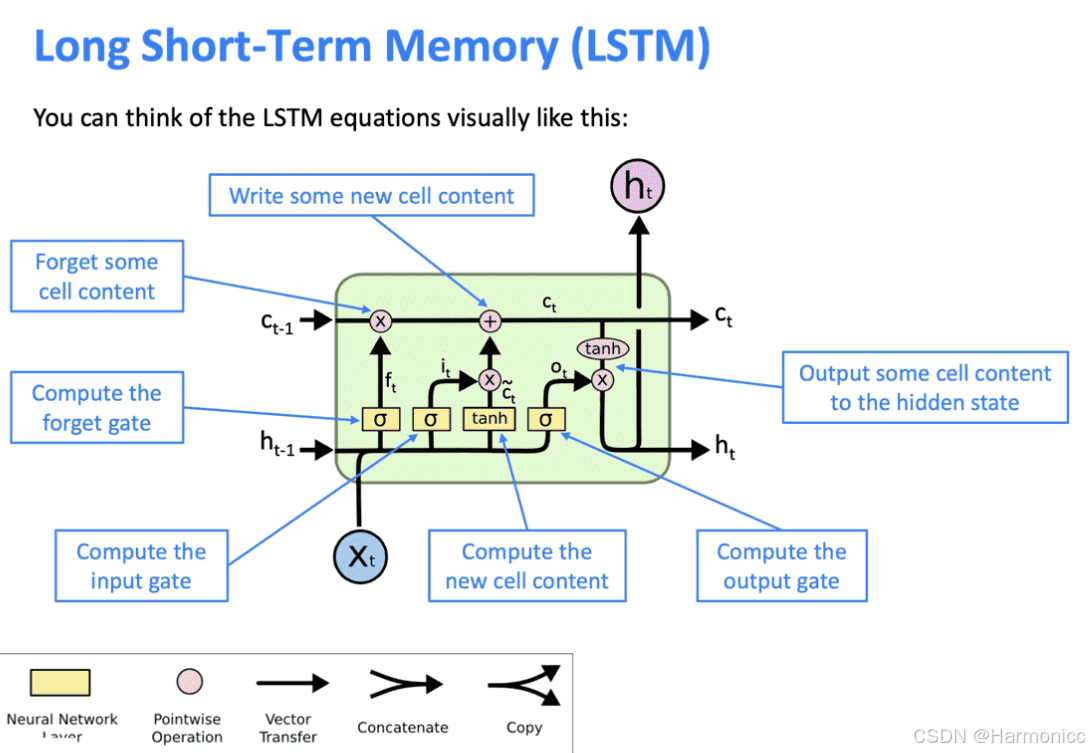



由此,LSTM解决了RNN的长期依赖问题
2.4 GRU
GRU实际上是对LSTM的一个简化,GRU也是由“门”构成的网络,它只有两个门:更新门(update gate)和重置门(reset gate)。 它主要对LSTM简化了什么地方呢?GRU在表示当前的信息的时候,只使用了一个更新门,而LSTM则使用了一个遗忘门和一个输入门:
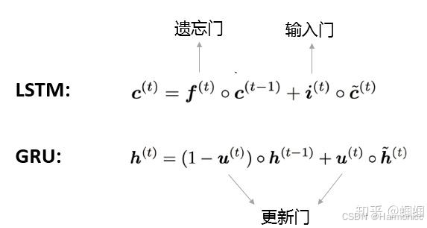
GRU也是可以通过调整两个门的开合情况来控制历史信息的保留和当前信息的更新,从而让模型更好地应对长距离依赖和梯度消失的问题。
2.4.1 LSTM VS GRU

2.5 RNN变种
前面介绍的LSTM和GRU属于RNN单元内部的升级,在单元外部,我们可以设计一些更复杂的结构,来提高模型的综合效果。
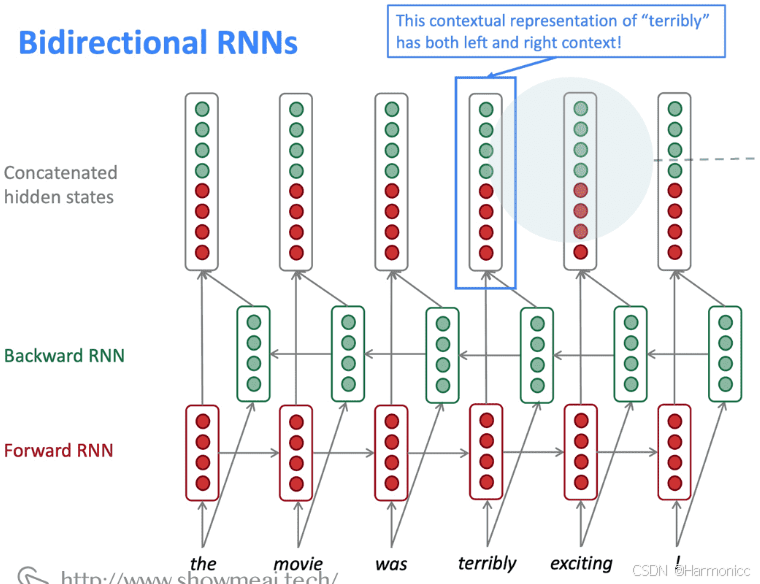
2.5.1 双向RNNs(Bidirectional RNNs)
RNN是按照顺序处理一个序列的,这使得每个step我们都只能考虑到前面的信息,而无法考虑到后面的信息。而很多时候我们理解语言的时候,需要同时考虑前后文。因此,我们可以将原本的RNN再添加一个相反方向的处理,然后两个方向共同表示每一步的输出。
2.5.2 多层RNN(Multi-layer RNNs)
其实就是叠叠乐
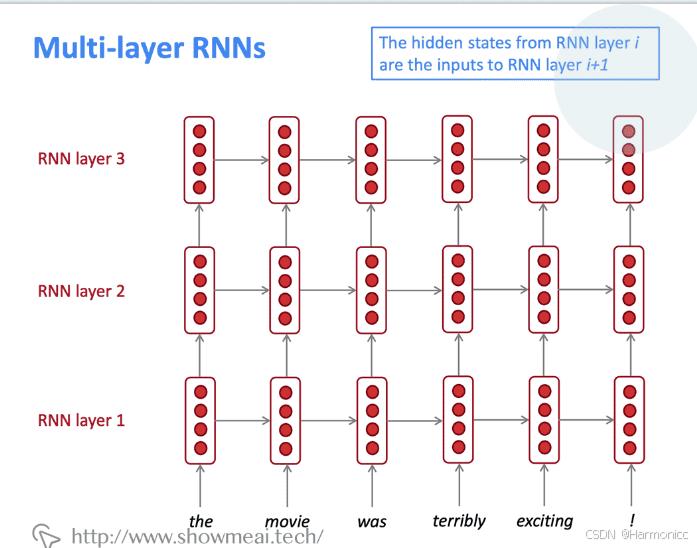
- 高性能的RNNs通常是多层的(但没有卷积或前馈网络那么深)
- 例如:在2017年的一篇论文,Britz et al 发现在神经机器翻译中,2到4层RNN编码器是最好的,和4层RNN解码器
- 但是,skip-connections / dense-connections 需要训练更深RNNs(例如8层)
- RNN无法并行化,计算代价过大,所以不会过深
- Transformer-based 的网络(如BERT)可以多达24层
- BERT 有很多skipping-like的连接
2.6 Transformer
总体模型架构
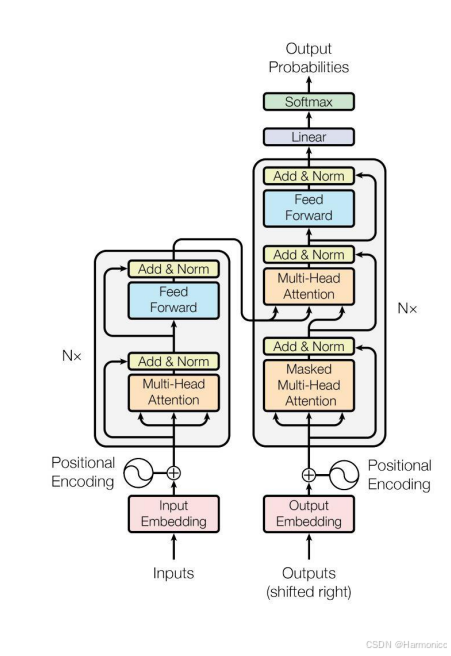
核心是自注意力机制,那么注意力机制和自注意力机制有什么区别?
举个例子:

总结来说,自注意力是注意力机制的一种特殊形式,专攻序列内部的关系挖掘,而普通注意力更擅长处理跨序列的关联。自注意力让模型像人类一样,通过上下文理解每个词的含义。
2.6.1 注意力计算
什么是注意力?说白了就是一种权重分配机制
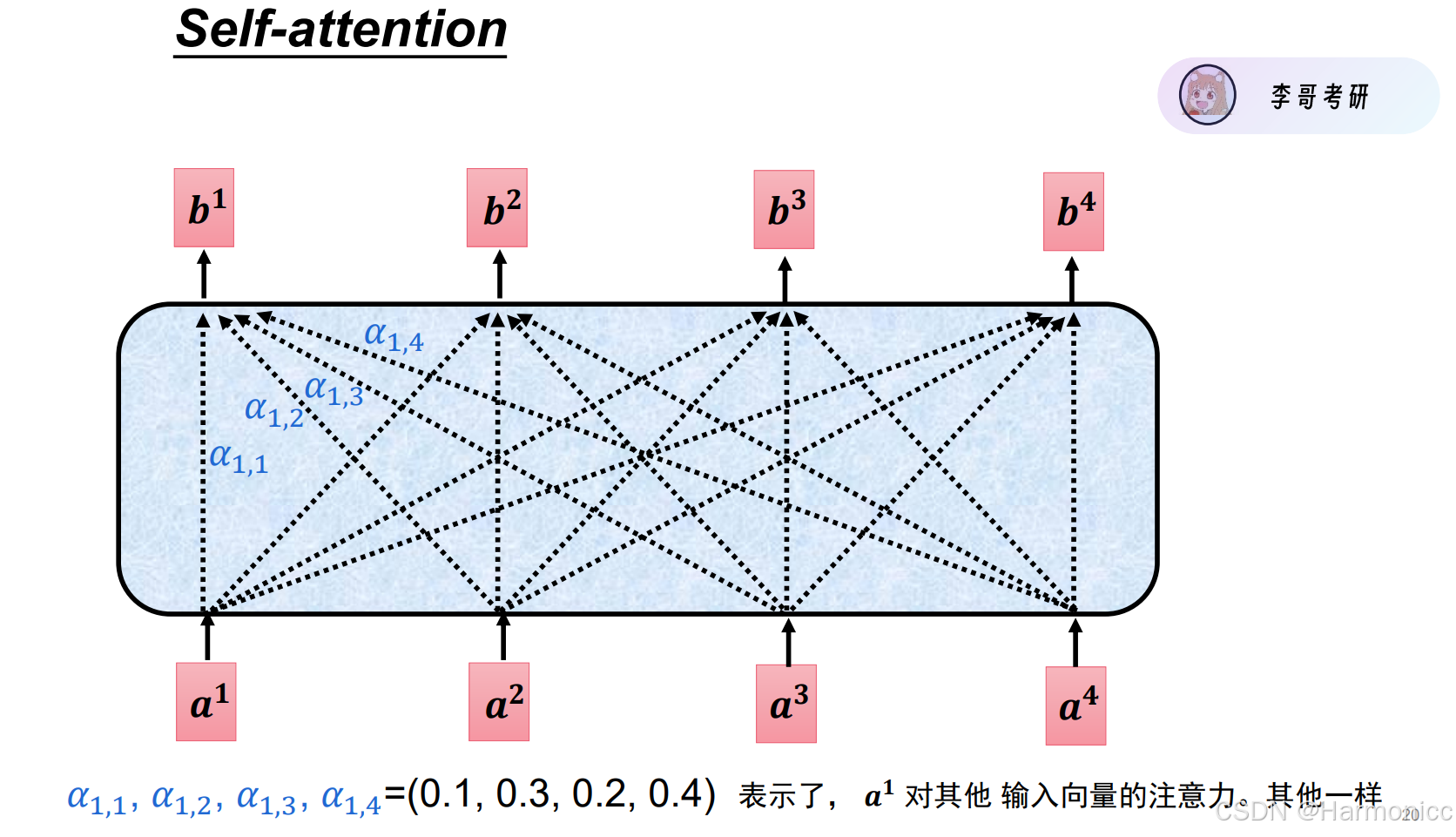

对于注意力计算有两种方法
第一种方法比较朴素,即与
做点乘得到
,这个方法的缺点就是相乘结果始终是一个固定值,缺乏灵活性。
第二种方法是本节的核心之处,动态分配权重,自注意力机制。
2.6.2 自注意力机制
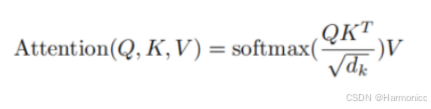
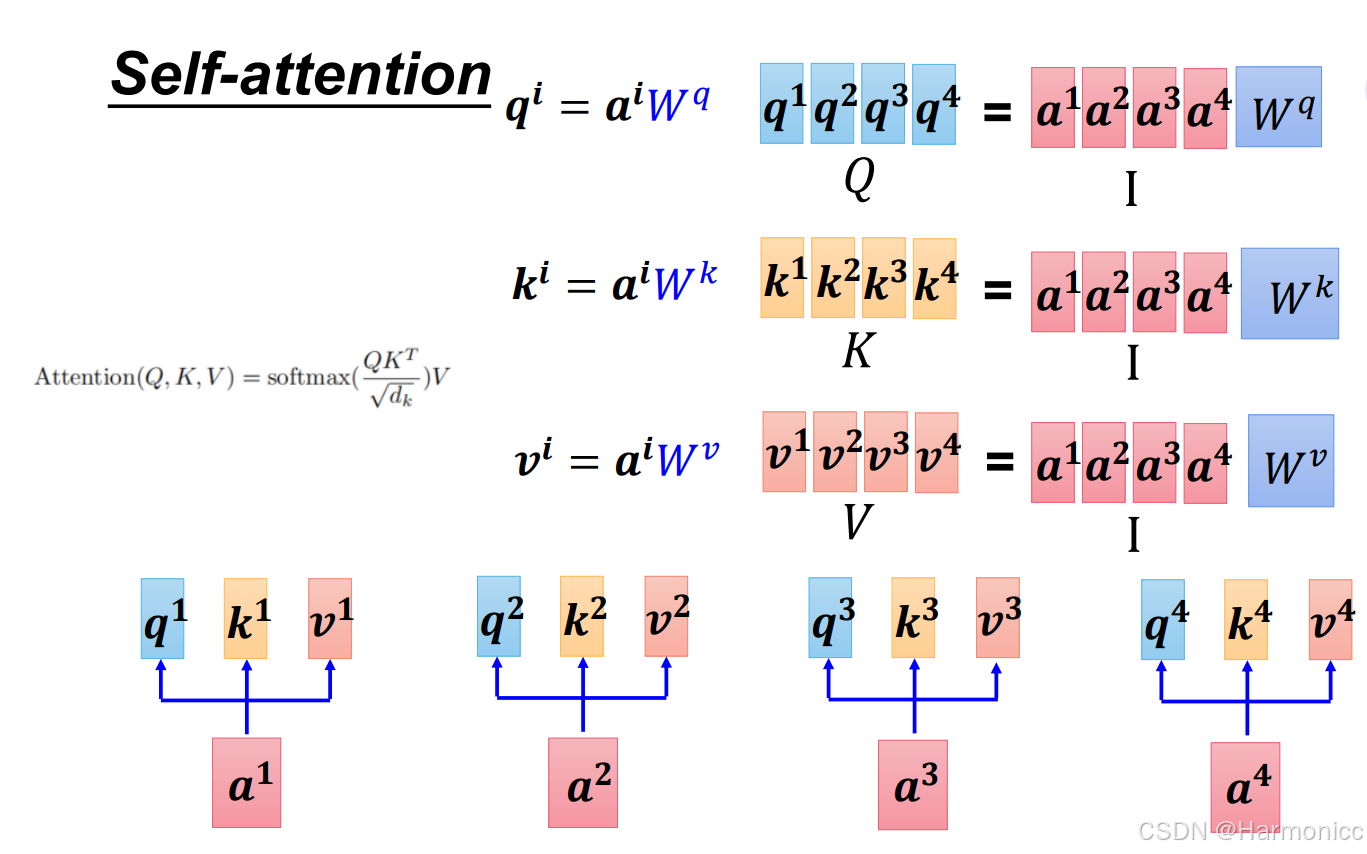
简单示例:
注意力机制可以类比为图书馆的智能推荐系统:当你想找一本关于“如何暴富”的书(Query),图书管理员会将你的需求与所有书的标题(Key)逐一比对,计算匹配度(如《致富思维》得90分),并通过除以书名长度()防止复杂书名干扰结果;接着用softmax将分数转化为权重(如80%关注《致富思维》),最后按权重融合相关书籍的内容(Value),生成一份综合“暴富指南”。整个过程就像管理员动态筛选并整合信息,精准匹配你的需求。

计算过程:

要注意的维度问题:

2.6.3 多头自注意力机制
自注意力机制和多头自注意力机制的联系与区别
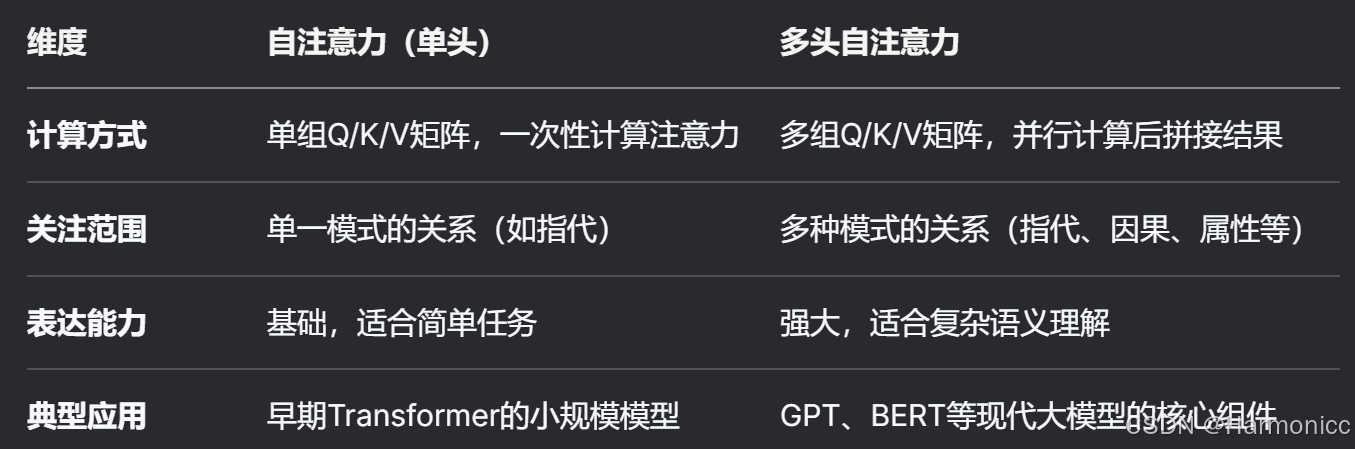
简单理解就是并行计算拼接结果提高效率
技术细节

三、Bert具体原理
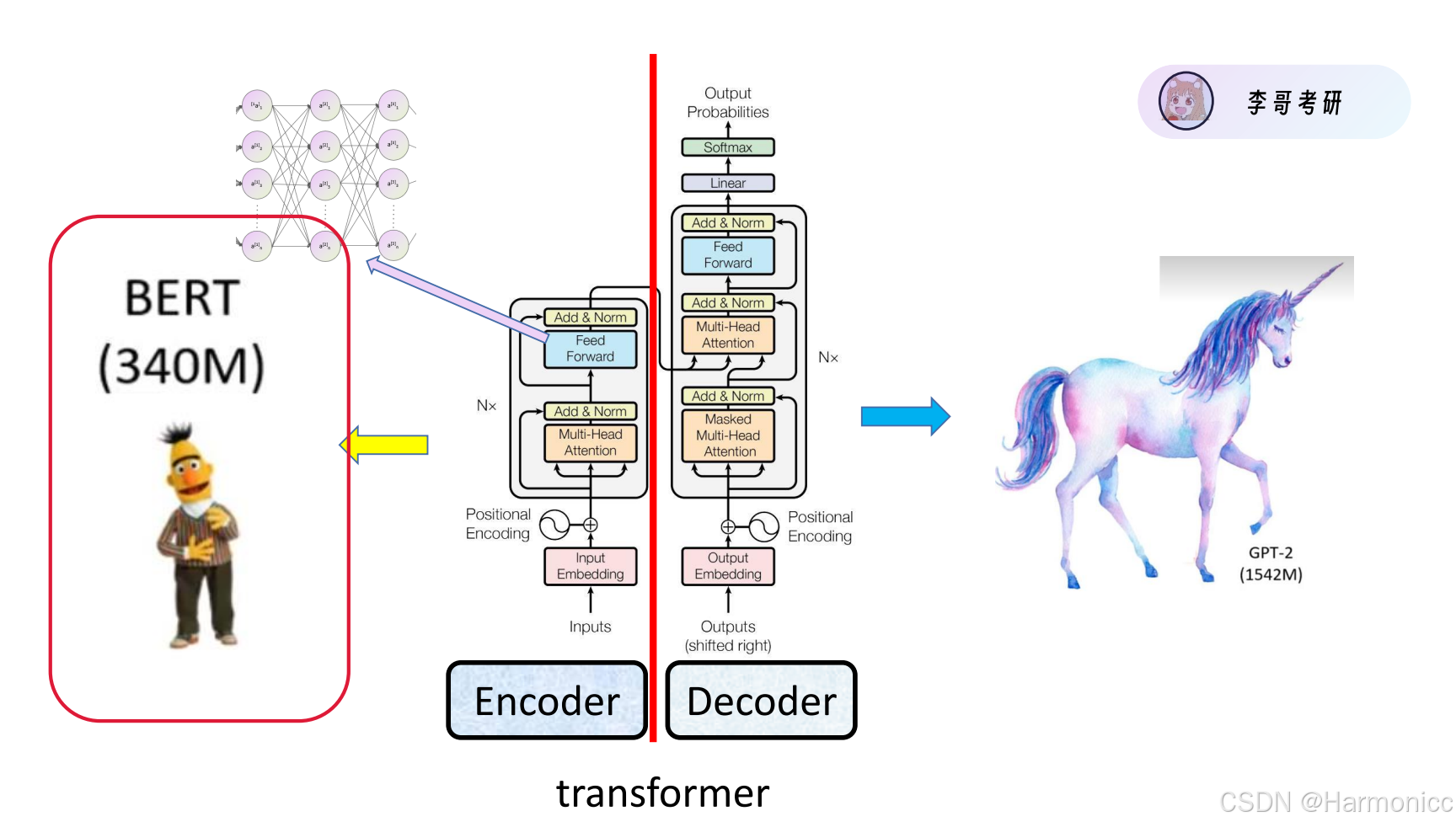
我们来通俗地解释一下transformer
首先是Encoder,这其实就是一个特征提取器,例如Bert
1.词嵌入

2.编码过程

其次是Decoder
1.解码过程

2.文字生成

要搞清楚一个模型,需要紧抓这个模型的输入和输出。
3.1 迁移学习
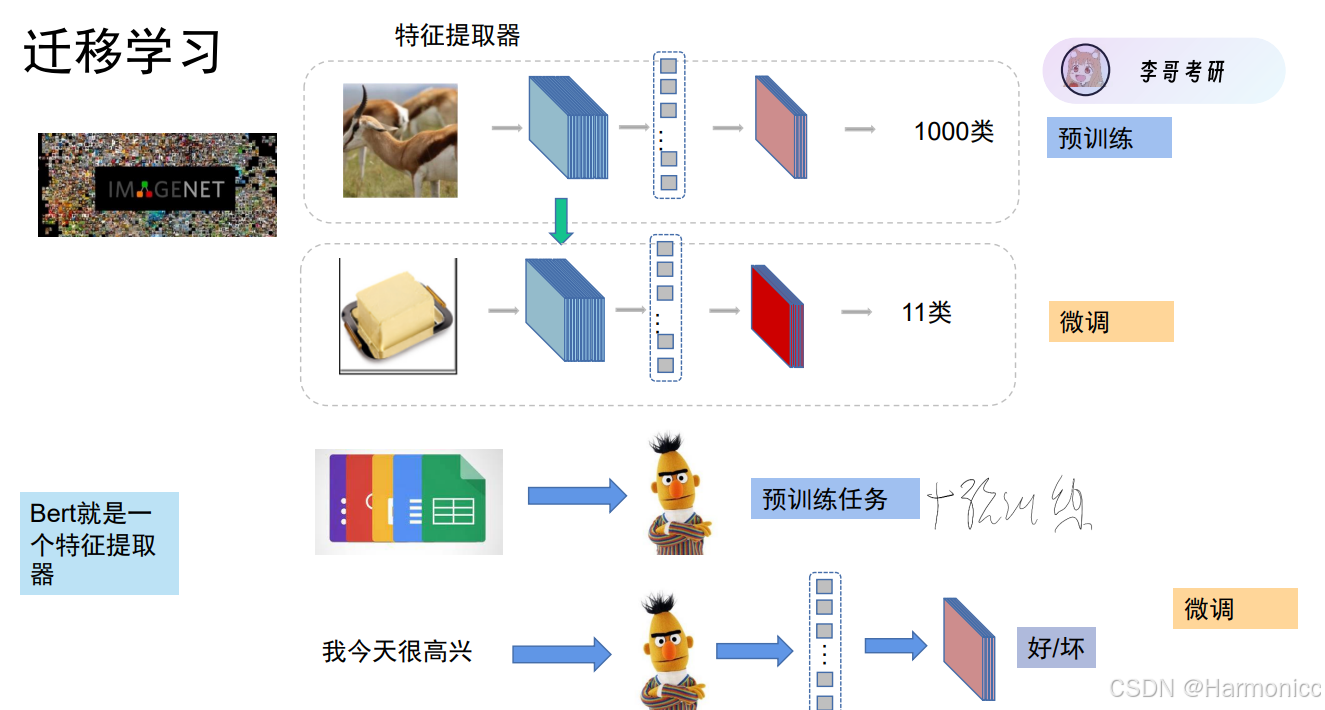
算力资源充足的大佬们负责搞定预训练任务,然后捣鼓出来的特征提取器给我们微调(且加上我们具体任务时的分类头)即可。
3.2 Bert模型结构
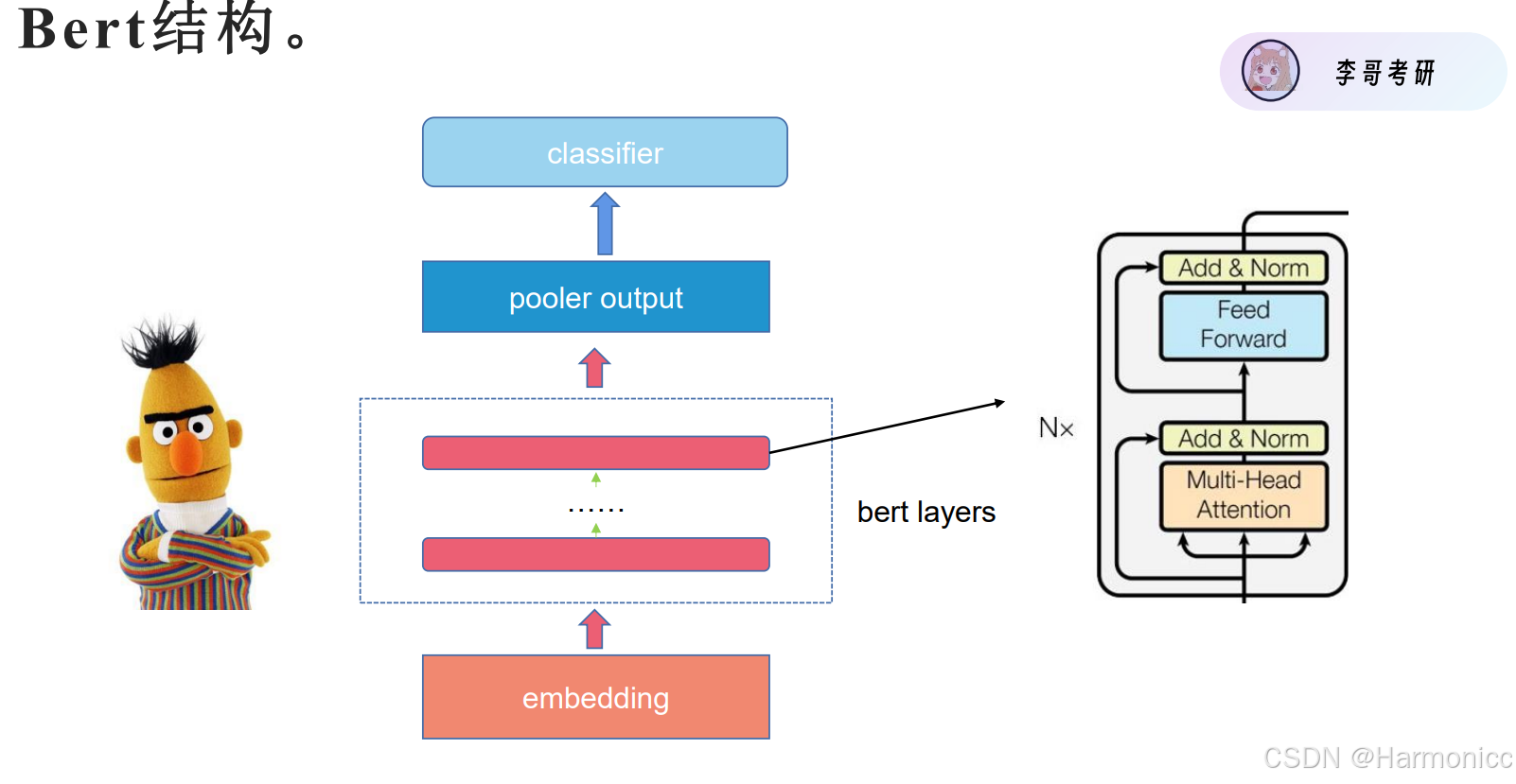
这个就是迁移学习的具体应用,加了个池化层而已。
3.3 Bert的输入输出
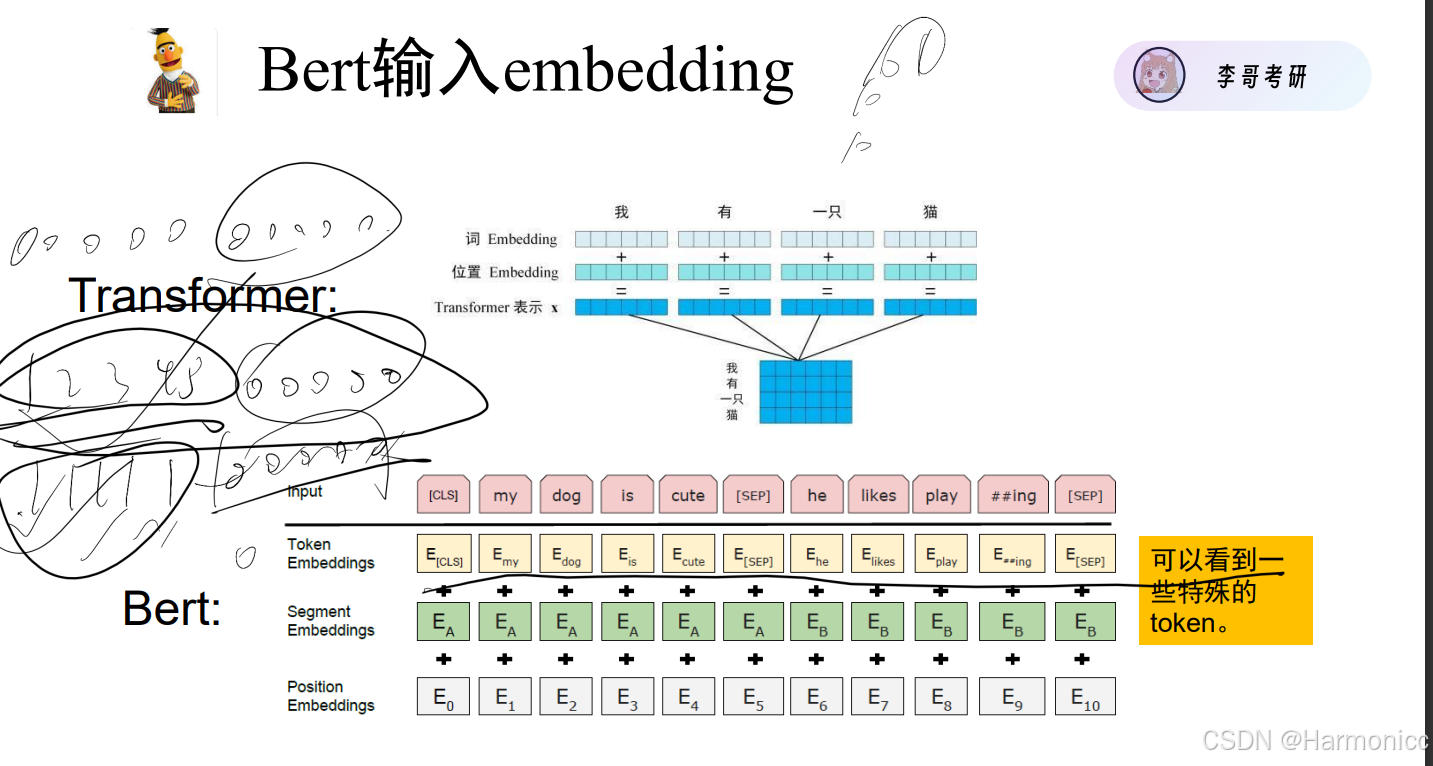
- Token - Embeddings 词编码
- Segment - Embeddings 这个词具体在哪个句子(逗号/句号隔开算一个句子)
- Position - Embeddings 给每个词加上座位号
- [CLS] - > Classification 理解成Java里的类 给每个具体的句子打标识符
- [SEP] - > 逗号/句号
四、其他
4.1 SFT与LoRA
SFT是微调方法,LoRA是其中一种轻量技术
关于SFT

关于LoRA

关于SFT(LORA)

具体理解

总结

本小节结束

















 122
122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









