




 本文详细介绍了数据结构中的线性表、链表、栈与队列、串处理、树与图算法、查找方法、排序算法以及更新至2023年的最新内容,涵盖了《大话数据结构》的核心知识点。
本文详细介绍了数据结构中的线性表、链表、栈与队列、串处理、树与图算法、查找方法、排序算法以及更新至2023年的最新内容,涵盖了《大话数据结构》的核心知识点。
人工智能:能够感知、推理、行动和适应的程序。
机器学习:能够随着数据量的不断增加不断改进性能的算法。
* 机器学习其实就是统计学习方法的演化,掰开来全是统计学上的东西,可解释性比较强,几个经典的算法比如KNN, 决策树,朴素贝叶斯
* KNN:监督(数据带标签),用于分类回归,但KNN和感知机有什么不同点?
* 决策树:原理跟二叉搜索树差不多,用于分类
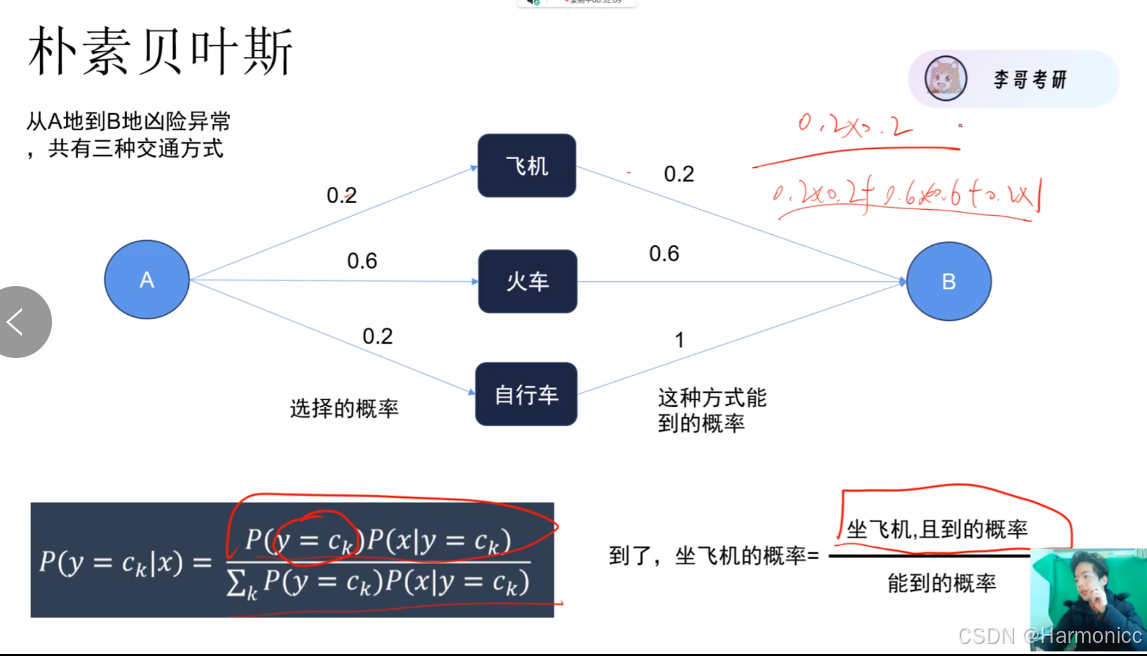
* 朴素贝叶斯:后验估计,这里举例的是坐飞机
*机器学习算法介绍:风中摇曳的小萝卜
深度学习:机器学习的一个子集;利用多层神经网络从大量数据中进行学习。
别纠结深度学习和机器学习区别了,深度学习就机器学习的子集,就神经网络。
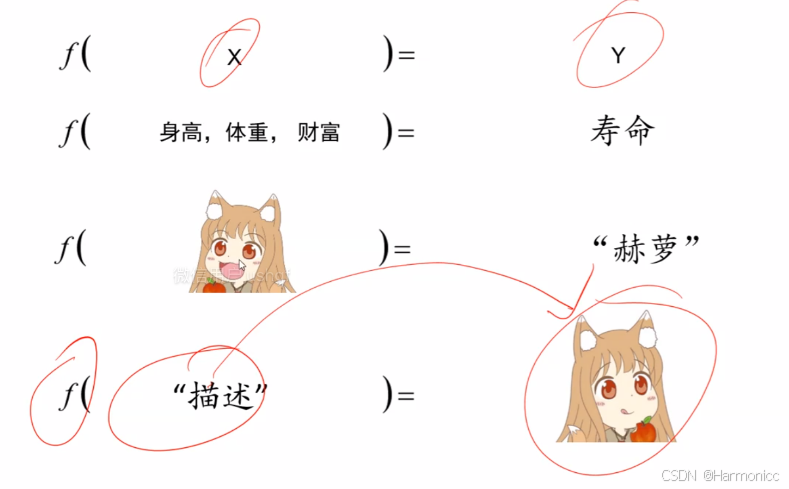
*深度学习:找到目标函数实现自变量
到
的映射,
和
可以是图片也可以是文字。
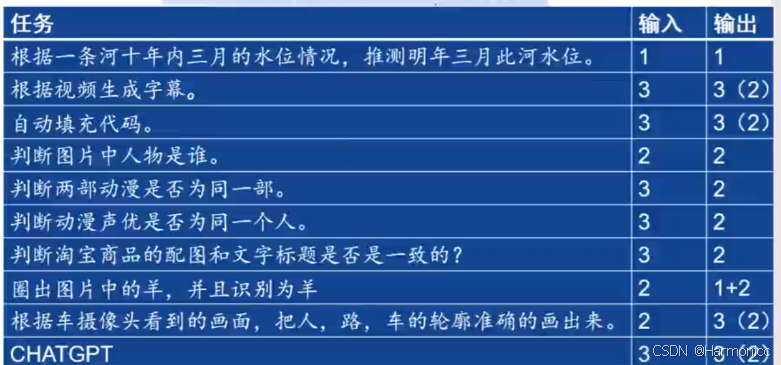
*常见神经网络的三种输入形式

视频也是序列
*常见神经网络的输出
回归,分类,生成(结构化输出)

随堂小测
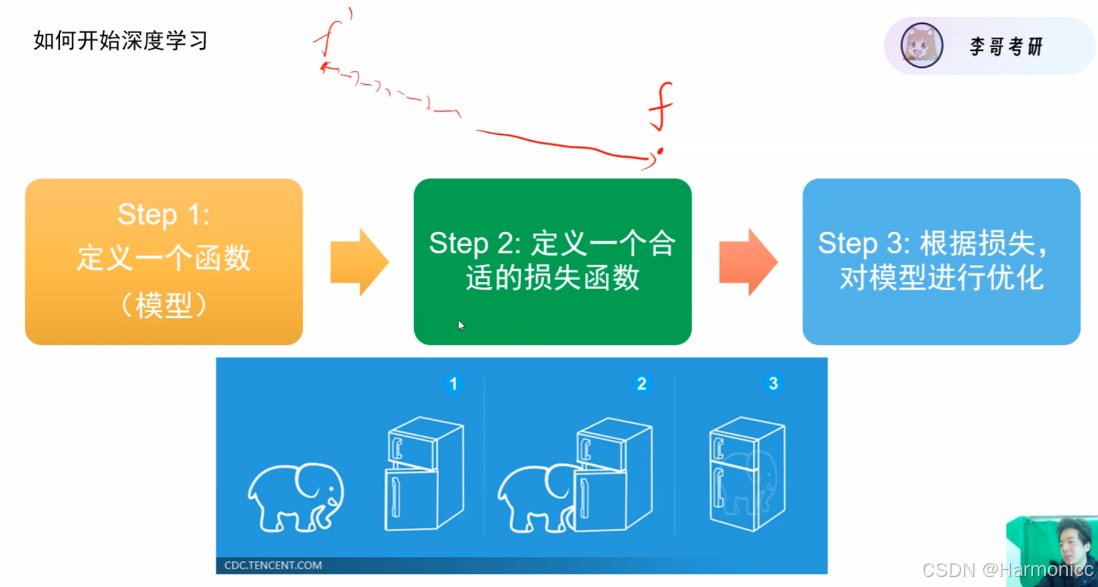
如何开始深度学习?
关于Loss

一个很生动的例子:愤怒的小鸟,在这个例子中,Loss函数中的参数就包括弹出去的力度和角度。

计算Loss

很重要
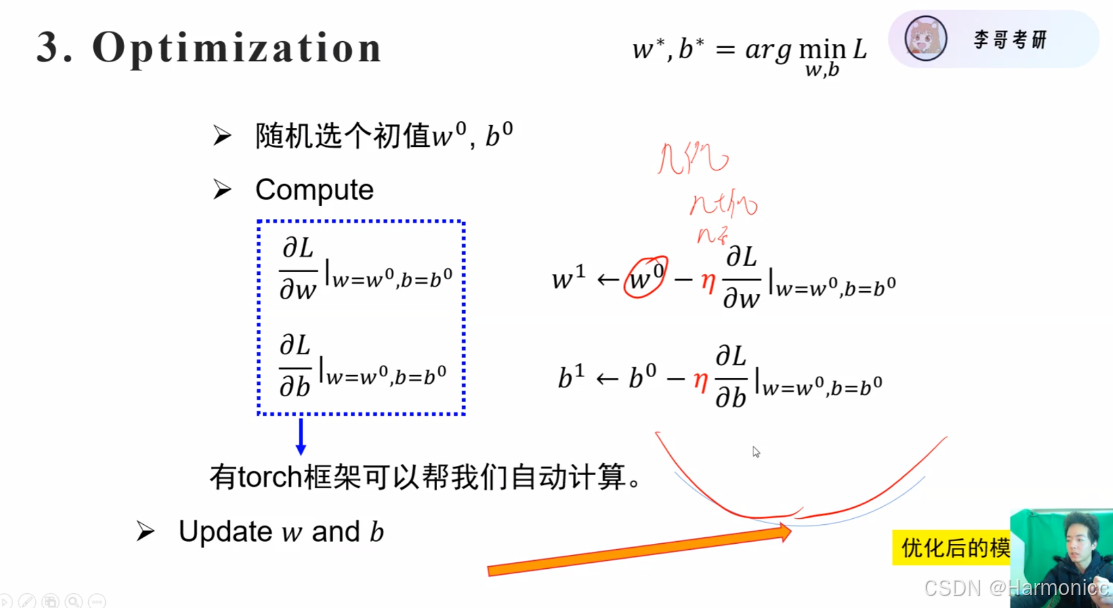
优化Loss
求Loss的最小参数w和b
为什么要用偏导?因为需要把其他的当作常数
这里说一下细节,如果计算出来偏导为正,说明左低右高(说明此时w还不是极值点),即需要往左走。
Q1:怎么实现往左走?即用w本身减去学习率乘它的偏导
Q2:这步走多长?
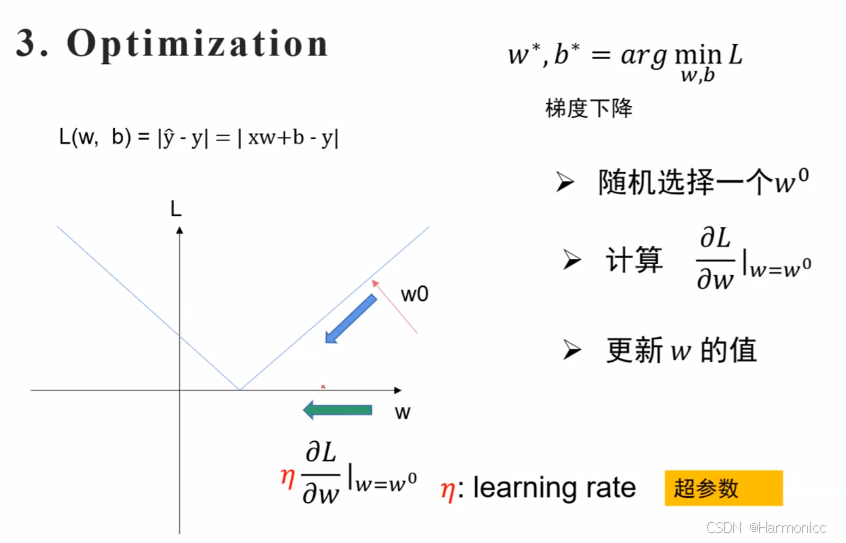
(超参数,模型没有办法学习,调参之一)
一些经典的模型性能评估指标(MAE,MSE)可当作Loss值
MAE(平均绝对误差,Mean Absolute Error)
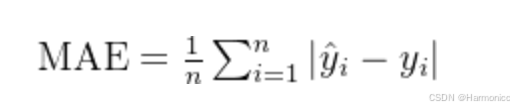
MSE(平均平方误差,Mean Squared Error)
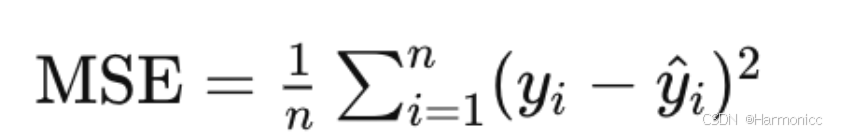
RMSE(均方根误差,Root Mean Squared Error)
![]()
感知机局限--无法实现异或门
优化流程
名词解释&问题示例
1.机器学习和深度学习的区别
2.分类和回归的区别
3.神经网络的输入形式
4.神经网络的输出形式
5.线性回归模型公式,即损失函数(loss),,
,
,
的具体含义
6.超参数
7.最简单的神经网络(感知机)的局限性
8.常用实验结果评价指标及相应计算方法
9.为什么要用Anaconda?
10.为什么要用PyTorch?
本小节结束。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









