




 本文通过两种方法解决了使用Logistic回归进行特征选择时出现的FutureWarning警告,介绍了警告产生的原因及如何避免。
本文通过两种方法解决了使用Logistic回归进行特征选择时出现的FutureWarning警告,介绍了警告产生的原因及如何避免。
from pandas import read_csv
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
#导入数据
filename = 'pima_data.csv'
names = ['preg','plas','pres','skin','test','mass','pedi','age','class']
data = read_csv(filename,names=names)
#将数据分为输入数据和输出结果
array = data.values
X = array[:,0:8]
Y = array[:,8]
#特征选定
model = LogisticRegression(solver='liblinear')
rfe = RFE(model,3)
fit = rfe.fit(X,Y)
print("特征个数:")
print(fit.n_features_)
print("被选定的特征:")
print(fit.support_)
print("特征排名:")
print(fit.ranking_)
运行结果:
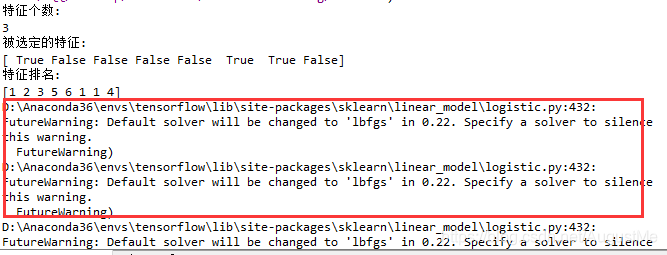
用python中logistic回归算法进行数据建模,遇到下面的警告:
FutureWarning: Default solver will be changed to ‘lbfgs’ in 0.22. Specify a solver to silence this warning.
并不影响程序的运行和结果,但是出现一大串字符,感觉很不爽,于是就查找原因:
FutureWarning是语言或者库中将来可能改变的有关警告。
根据报警信息和参考相关文档,“Default will change from ‘liblinear’ to ‘lbfgs’ in 0.22.” 默认的solver参数在0.22版本中,将会由“liblinear”变为“lbfgs”
LogisticRegerssion算法的solver仅支持以下几个参数’liblinear’, ‘newton-cg’, ‘lbfgs’, ‘sag’, ‘saga’。
解决方法:
方法1:
model=LogisticRegression(solver=’liblinear’)
方法2:
import warnings
warnings.filterwarnings("ignore")
# 这个方法只是解决了表面,没有根治
参考和引用:
https://blog.youkuaiyun.com/linzhjbtx/article/details/85331200
仅用来个人学习和分享,如若侵权,留言立删。
尊重他人知识产权,不做拿来主义者!
喜欢的可以关注我哦QAQ,
你的关注就是我write博文的动力。


















 1235
1235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











