




前面文章我们主要用 llama.cpp 在本地加载并运行了一个模型。但 llama.cpp 主要是针对当下比较火的大模型的。其实,目前最通用的端侧推理引擎是 ONNX Runtime 库。
今天,我们再来看下这个推理引擎的使用。
0. 系列文章
1. 下载资源与目录规划
我们需要两样东西:推理引擎库 (ONNX Runtime) 和 模型文件 (YOLOv8n.onnx)。
1.1 下载 ONNX Runtime (C++ 库)
不要用 brew install!为了让大家理解库的链接原理,我们要手动下载预编译包。
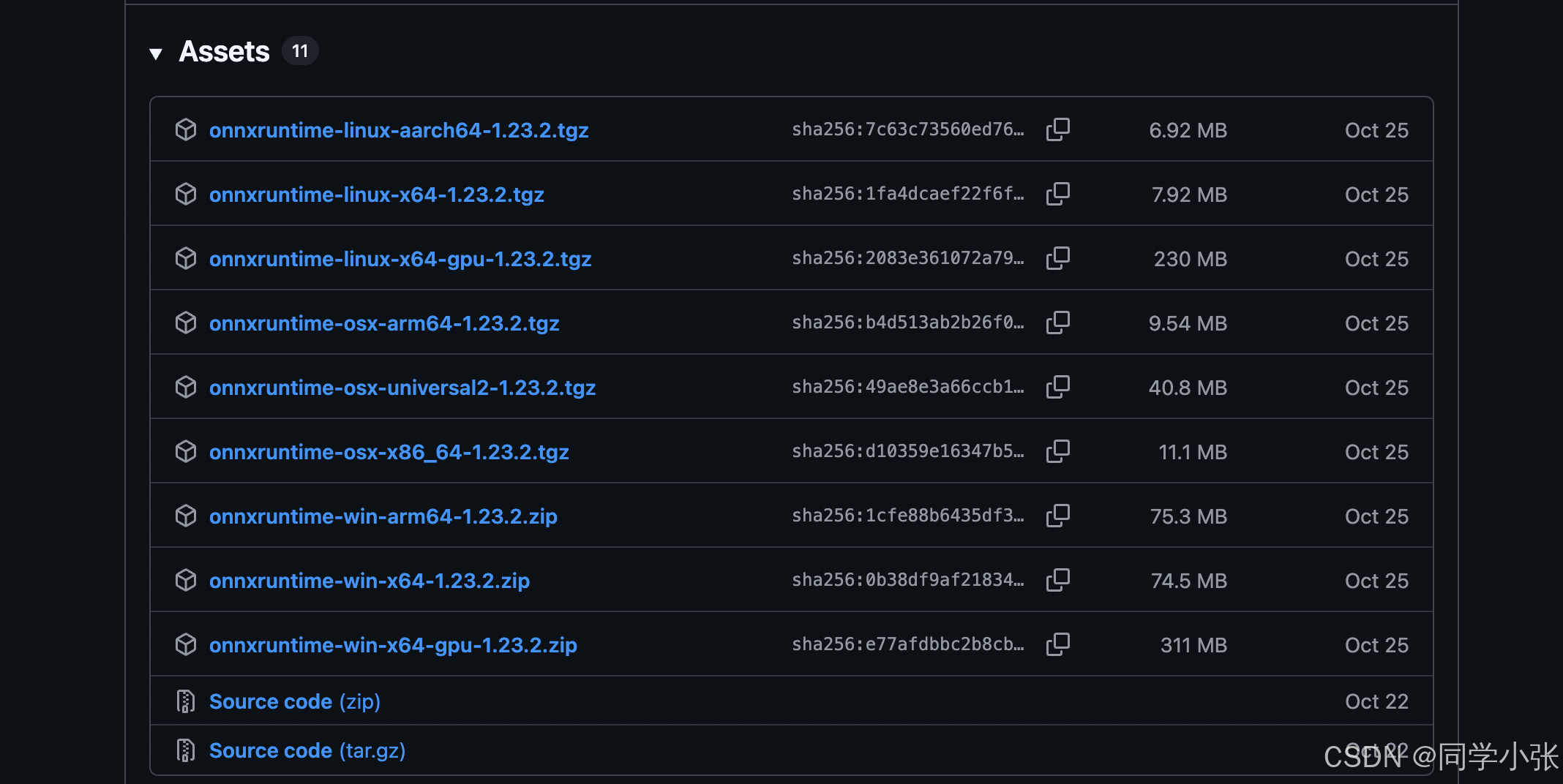
- 下载地址: GitHub ONNX Runtime Releases (https://github.com/microsoft/onnxruntime/releases)
-
版本: 找最新的 (例如 v1.19.2 或 v1.20.0)。
-
文件名: 寻找 onnxruntime-osx-arm64-x.x.x.tgz
(注意:根据你的系统架构选择,我是MacBook Pro M4芯片,所以一定要选 osx-arm64,不能选 universal 或 x86)。
1.2 下载 YOLOv8 模型
可以复制这个链接下载:
https://huggingface.co/cabelo/yolov8/resolve/main/yolov8n.onnx?download=true
1.3 规划项目目录
- 解压下载的 onnxruntime-osx-arm64-xxx.tgz。
- 将解压后的文件夹重命名为 onnxruntime。
- 把它拖进 Week1_Yolo/third_party/ 目录下。
目录结构如下。
Week1_Yolo/
├── CMakeLists.txt # 构建脚本 (稍后创建)
├── main.cpp # 主程序 (稍后创建)
├── model/
│ └── yolov8n.onnx # 刚才下载的模型放这里
└── third_party/
└── onnxruntime/ # 解压刚才下载的 tgz 包,改名放到这里
├── include/ # 里面应该有一堆 .h 文件
└── lib/ # 里面应该有 libonnxruntime.dylib
2. 编写 CMakeLists.txt
cmake_minimum_required(VERSION 3.10)
project(YoloOnnxRunner)
# 设置 C++ 标准为 C++17 (现代 C++ 写法)
set(CMAKE_CXX_STANDARD 17)
# 1. 定义 ONNX Runtime 的路径
# ${CMAKE_SOURCE_DIR} 代表当前项目根目录
set(ORT_HOME ${CMAKE_SOURCE_DIR}/third_party/onnxruntime)
# 2. 告诉编译器去哪里找头文件 (.h)
include_directories(${ORT_HOME}/include)
# 3. 告诉链接器去哪里找库文件 (.dylib)
link_directories(${ORT_HOME}/lib)
# 4. 生成可执行文件 main
add_executable(main main.cpp)
# 5. 链接动态库
# 这里的名字对应 libonnxruntime.1.20.0.dylib (去掉前缀 lib 和后缀 .dylib)
target_link_libraries(main onnxruntime)
3. 编写 C++ 代码 (main.cpp)
#include <iostream>
#include <vector>
// 引入 ONNX Runtime 的 C++ 头文件
#include <onnxruntime_cxx_api.h>
int main() {
std::cout << "🚀 Starting YOLOv8 Check..." << std::endl;
// 1. 初始化环境 (Environment)
// ORT_LOGGING_LEVEL_WARNING: 只打印警告及以上错误,保持清爽
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "YoloTest");
// 2. 配置会话选项 (Session Options)
Ort::SessionOptions session_options;
// 设置为 CPU 执行 (Week 1 先不用 GPU/NPU)
session_options.SetIntraOpNumThreads(1);
// 设置优化级别 (GraphOptimizationLevel::ORT_ENABLE_ALL)
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
// 3. 加载模型 (Session)
// 这里的路径是相对于编译后的可执行文件的,或者使用绝对路径
// 注意:Mac 上运行路径可能在 build 文件夹里,建议写绝对路径测试,或者把模型复制到 build 目录
// 这里为了演示,我们假设模型在 ../model/yolov8n.onnx
const char* model_path = "../model/yolov8n.onnx";
try {
std::cout << "Loading model from: " << model_path << std::endl;
Ort::Session session(env, model_path, session_options);
std::cout << "✅ Model loaded successfully!" << std::endl;
// 4. 获取输入输出信息
// YOLOv8 通常只有一个输入 (images) 和一个输出 (output0)
// 获取输入节点的数量
size_t num_input_nodes = session.GetInputCount();
// 获取输出节点的数量
size_t num_output_nodes = session.GetOutputCount();
std::cout << "Input nodes: " << num_input_nodes << std::endl;
std::cout << "Output nodes: " << num_output_nodes << std::endl;
// 获取输入 Tensor 的名称和维度
// 注意:新版 ORT API 返回的是 AllocatedStringPtr,需要稍微处理一下
Ort::AllocatorWithDefaultOptions allocator;
// 读取第 0 个输入的名字
auto input_name_ptr = session.GetInputNameAllocated(0, allocator);
std::string input_name = input_name_ptr.get();
std::cout << "Input Name: " << input_name << std::endl;
// 读取第 0 个输入的形状 (Shape)
Ort::TypeInfo input_type_info = session.GetInputTypeInfo(0);
auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();
std::vector<int64_t> input_dims = input_tensor_info.GetShape();
std::cout << "Input Shape: [";
for (size_t i = 0; i < input_dims.size(); i++) {
// YOLO 模型导出时 Batch 维度可能是动态的 (-1),我们需要将其固定为 1
if (input_dims[i] == -1) input_dims[i] = 1;
std::cout << input_dims[i] << (i < input_dims.size() - 1 ? ", " : "");
}
std::cout << "]" << std::endl;
// 5. 构造一个假的输入数据 (Fake Input)
// 形状通常是 [1, 3, 640, 640]
// 元素总数 = 1 * 3 * 640 * 640
size_t input_tensor_size = 1 * 3 * 640 * 640;
std::vector<float> input_tensor_values(input_tensor_size);
// 初始化为 0.5 (模拟灰色图片)
for (size_t i = 0; i < input_tensor_size; i++) {
input_tensor_values[i] = 0.5f;
}
// 创建内存信息 (CPU)
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
// 创建输入 Tensor 对象
std::vector<const char*> input_node_names = { input_name.c_str() };
std::vector<Ort::Value> input_tensors;
input_tensors.push_back(Ort::Value::CreateTensor<float>(
memory_info,
input_tensor_values.data(),
input_tensor_size,
input_dims.data(),
input_dims.size()
));
// 6. 运行推理 (Run Inference)
// 获取输出名字
auto output_name_ptr = session.GetOutputNameAllocated(0, allocator);
std::string output_name = output_name_ptr.get();
std::vector<const char*> output_node_names = { output_name.c_str() };
std::cout << "Running inference..." << std::endl;
auto output_tensors = session.Run(
Ort::RunOptions{nullptr},
input_node_names.data(),
input_tensors.data(),
1, // 输入个数
output_node_names.data(),
1 // 输出个数
);
// 7. 解析输出结果
float* floatarr = output_tensors[0].GetTensorMutableData<float>();
auto output_info = output_tensors[0].GetTensorTypeAndShapeInfo();
std::vector<int64_t> output_dims = output_info.GetShape();
std::cout << "✅ Inference finished!" << std::endl;
std::cout << "Output Name: " << output_name << std::endl;
std::cout << "Output Shape: [";
for (size_t i = 0; i < output_dims.size(); i++) {
std::cout << output_dims[i] << (i < output_dims.size() - 1 ? ", " : "");
}
std::cout << "]" << std::endl; // 预期输出: [1, 84, 8400]
} catch (const Ort::Exception& e) {
std::cerr << "❌ ORT Exception: " << e.what() << std::endl;
return -1;
}
return 0;
}
4. 编译与运行
编译命令如下:
mkdir build
cd build
cmake ..
make
./main
运行结果:
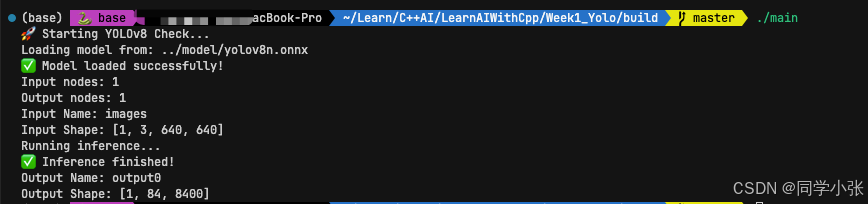
5. 常见报错
Q1: dyld: Library not loaded: @rpath/libonnxruntime.1.x.x.dylib
-
原因: 程序运行起来了,但是找不到动态库文件。
-
解决:
检查 CMakeLists.txt 里 set_target_properties(… BUILD_RPATH …) 那段代码写了没。
临时手动解决:在终端执行 export DYLD_LIBRARY_PATH=/你的路径/Week1_Yolo/third_party/onnxruntime/lib:$DYLD_LIBRARY_PATH,然后再运行 ./main。
Q2: ‘onnxruntime_cxx_api.h’ file not found
-
原因: 编译器找不到头文件。
-
解决: 检查 CMakeLists.txt 里的 include_directories 路径是否正确指向了 third_party/onnxruntime/include。注意文件夹层级是否多了一层。
Q3: Undefined symbols for architecture arm64
-
原因: 链接失败。可能是库文件路径不对,或者你下载成了 x86_64 的库。
-
解决:
确认下载的是 osx-arm64 版本。
确认 target_link_libraries(main onnxruntime) 里的名字正确。
Q4: 模型加载失败 (No such file or directory)
-
原因: C++ 里的相对路径是相对于可执行文件 (./main) 的,而不是相对于源代码 (main.cpp) 的。
-
解决: 确保 yolov8n.onnx 位于 Week1_Yolo/model/,且你是在 Week1_Yolo/build/ 目录下运行 ./main,所以路径应该是 ../model/yolov8n.onnx。
本篇文章我们将 ONNX 引擎跑起来了,加载了 yolo 模型,大家先模仿着跑起来。下篇文章进行详细一点的拆解。



















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











