









写在前面:资料来源于黑马程序员SpringCloud微服务开发与实战,java黑马商城项目微服务实战开发(涵盖MybatisPlus、Docker、MQ、ES、Redis高级等)_哔哩哔哩_bilibili
七、MQ高级
发送者的可靠性
发送者重连
有的时候由于网络波动,可能会出现发送者连接MQ失败的情况。通过配置我们可以开启连接失败后的重连机制:
spring:
rabbitmq:
connection-timeout: 1s # 设置MQ的连接超时时间
template:
retry:
enabled: true # 开启超时重试机制
initial-interval: 1000ms # 失败后的初始等待时间
multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长 = initial-interval * multiplier
max-attempts: 3 # 最大重试次数当网络不稳定的时候,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是阻塞式的重试,也就是说多次重试等待的过程中,当前线程是被阻塞的,会影响业务性能。
如果对于业务性能有要求,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
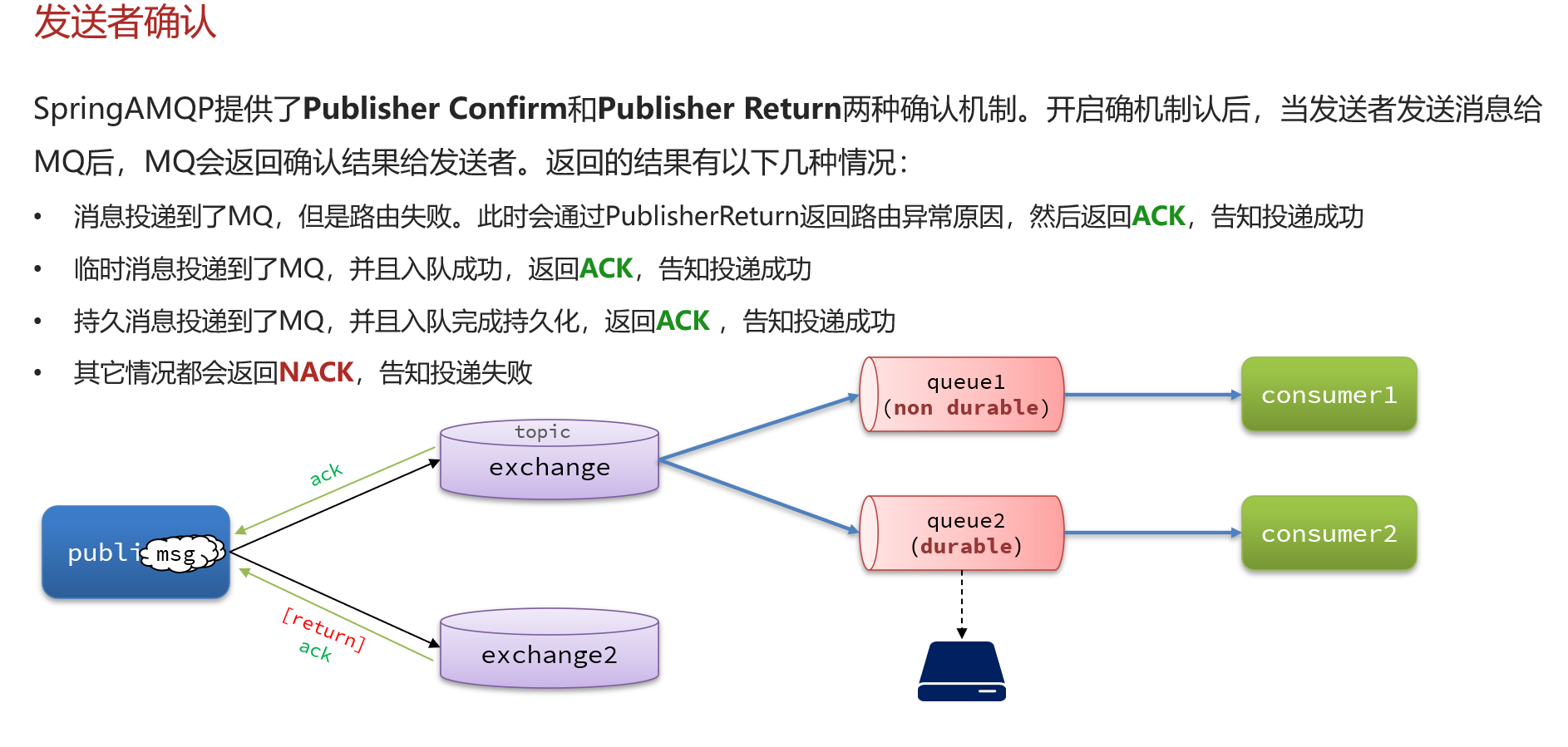
发送者确认
实际操作案例:
1.开启生产者确认,添加以下配置
spring:
rabbitmq:
publisher-confirm-type: correlated # 开启publisher confirm机制,并设置confirm类型
publisher-returns: true # 开启publisher return机制这里publisher-confirm-type有三种模式可选:
2.配置一个ReturnCallback(仅模拟)
@Slf4j
@AllArgsConstructor
@Configuration
public class MqConfig {
private final RabbitTemplate rabbitTemplate;
@PostConstruct
public void init(){
rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {
@Override
public void returnedMessage(ReturnedMessage returned) {
log.error("触发return callback,");
log.debug("exchange: {}", returned.getExchange());
log.debug("routingKey: {}", returned.getRoutingKey());
log.debug("message: {}", returned.getMessage());
log.debug("replyCode: {}", returned.getReplyCode());
log.debug("replyText: {}", returned.getReplyText());
}
});
}
}@PostConstruct:用来标记一个方法应该在依赖注入完成后立即被执行。它通常用于执行初始化操作。
rabbitTemplate.setReturnsCallback(...):这里为rabbitTemplate对象设置了返回回调。当消息无法被路由到任何队列时(即,既没有匹配的交换器也没有匹配的路由键),RabbitMQ会将该消息返回给发送者。通过设置这个回调,可以定义在这种情况下要执行的操作。
3.发送消息,指定消息ID、消息ConfirmCallback (仅模拟)
@Test
void testPublisherConfirm() throws InterruptedException {
// 1.创建CorrelationData
CorrelationData cd = new CorrelationData();
// 2.给Future添加ConfirmCallback
cd.getFuture().addCallback(new ListenableFutureCallback<CorrelationData.Confirm>() {
@Override
public void onFailure(Throwable ex) {
// 2.1.Future发生异常时的处理逻辑,基本不会触发
log.error("send message fail", ex);
}
@Override
public void onSuccess(CorrelationData.Confirm result) {
// 2.2.Future接收到回执的处理逻辑,参数中的result就是回执内容
if(result.isAck()){ // result.isAck(),boolean类型,true代表ack回执,false 代表 nack回执
log.debug("发送消息成功,收到 ack!");
}else{ // result.getReason(),String类型,返回nack时的异常描述
log.error("发送消息失败,收到 nack, reason : {}", result.getReason());
}
}
});
// 3.发送消息
rabbitTemplate.convertAndSend("hmall.direct", "blue", "helloooo", cd);
Thread.sleep(2000);
}cd.getFuture().addCallback(new ListenableFutureCallback<CorrelationData.Confirm>() { ... });
为CorrelationData对象的ListenableFuture添加回调,以便在消息发送成功或失败时得到通知。
在回调中实现了两个方法:
onFailure(Throwable ex):当消息发送过程中发生错误时被调用,这里记录了错误日志。
onSuccess(CorrelationData.Confirm result):当收到消息确认时被调用。根据result.isAck()判断是收到了确认(ack)还是未确认(nack),并作出相应的日志记录。
总结
1.SpringAMQP中发送者消息确认的几种返回值情况:
•消息投递到了MQ,但是路由失败。会return路由异常原因,返回ACK
•临时消息投递到了MQ,并且入队成功,返回ACK
•持久消息投递到了MQ,并且入队完成持久化,返回ACK
•其它情况都会返回NACK,告知投递失败
2.如何处理发送者的确认消息?
•发送者确认需要额外的网络和系统资源开销,尽量不要使用
•对于nack消息可以有限次数重试,依然失败则记录异常消息
MQ的可靠性
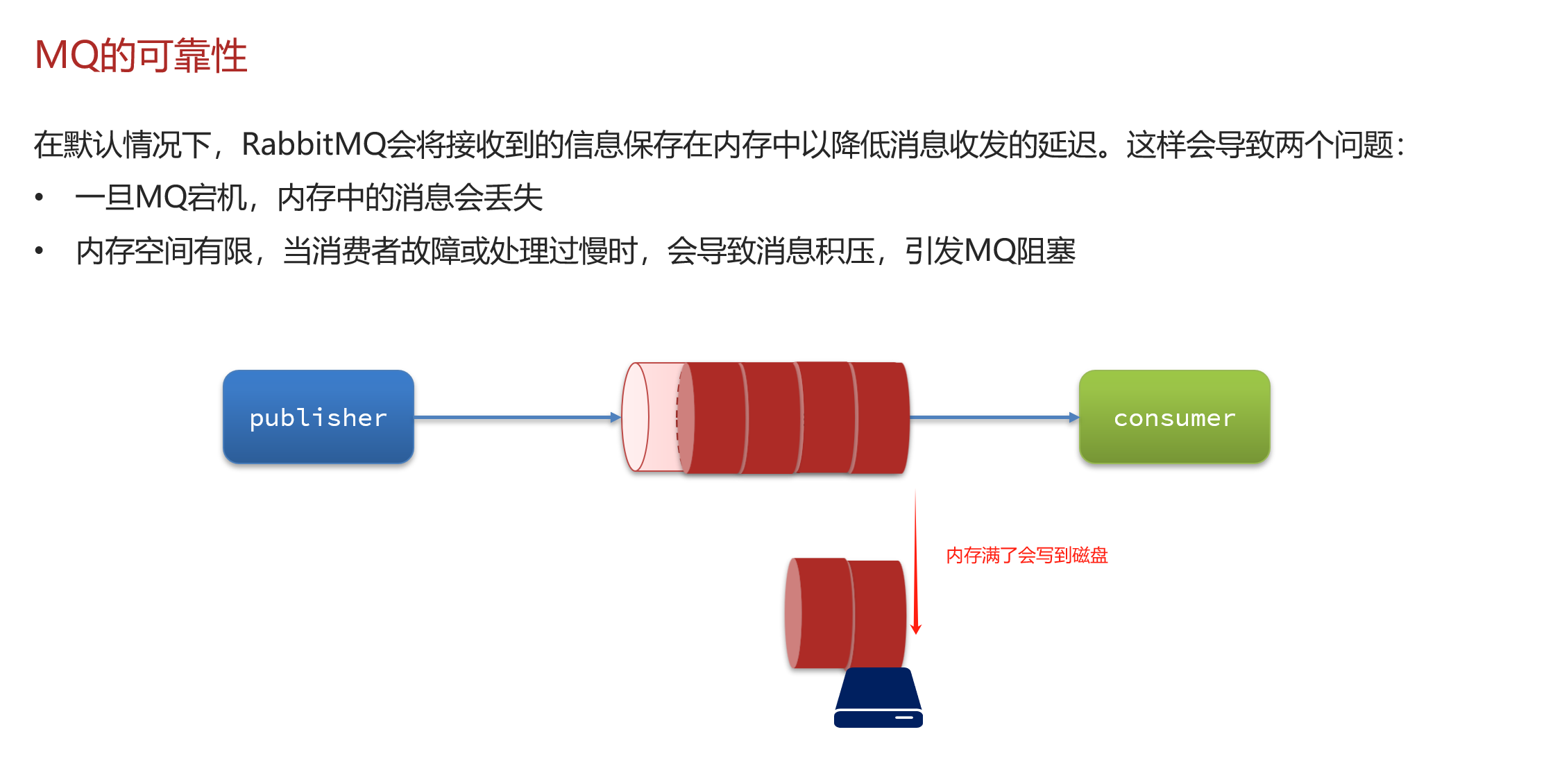
数据持久化
RabbitMQ实现数据持久化包括3个方面:
1.交换机持久化(默认开启)
2.队列持久化(默认开启)
3.消息持久化 (默认关闭)
当开启了消息持久化选项时,消息在到达MQ服务器后会立即尝试写入磁盘。这确保了即便服务器发生故障或重启,这些消息也不会丢失。 同时性能来说也会极大提升,不会说消息塞满了MQ后进行阻塞把一部分数据写入磁盘,然后再继续接收信息这个样子,导致接受信息能力波动比较大,进行持久化选项能很好的保证接受信息能力平稳且性能提升。
Lazy Queue
从RabbitMQ的3.6.0版本开始,就增加了Lazy Queue的概念,也就是惰性队列。
惰性队列的特征如下:
在3.12版本后,所有队列都是Lazy Queue模式,无法更改。
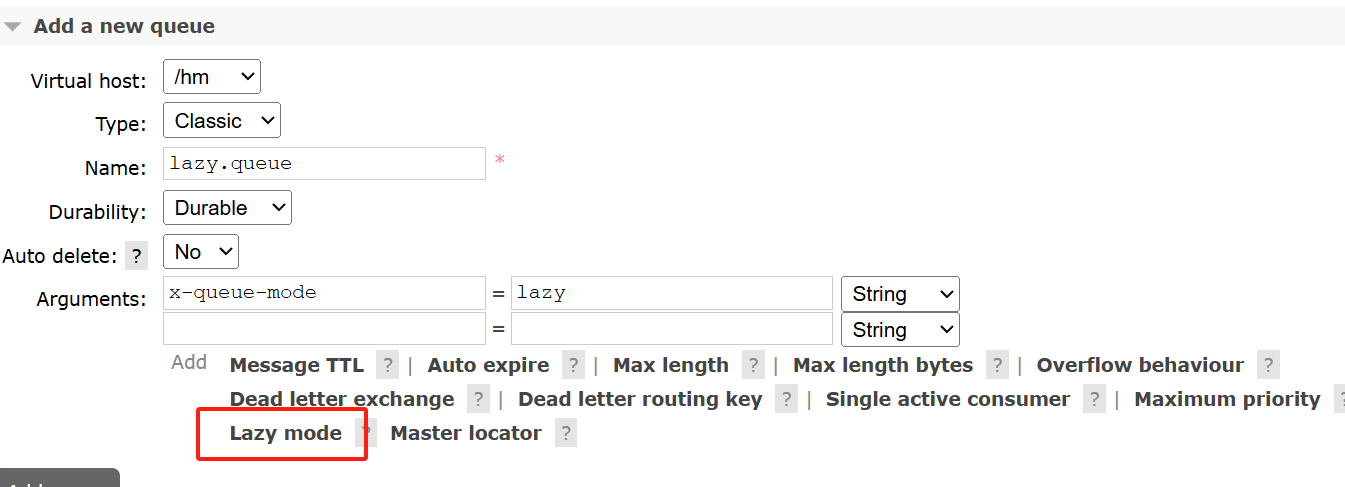
1.控制台配置Lazy模式
2.代码配置Lazy模式
@Bean
public Queue lazyQueue(){
return QueueBuilder
.durable("lazy.queue")
.lazy() // 开启Lazy模式
.build();
}下面这种方式就是加上 一个 arguments参数
@RabbitListener(queuesToDeclare = @Queue(
name = "lazy.queue",
durable = "true",
arguments = @Argument(name = "x-queue-mode", value = "lazy")
))
public void listenLazyQueue(String msg){
log.info("接收到 lazy.queue的消息:{}", msg);
}开启持久化和发送者确认时, RabbitMQ只有在消息持久化完成后才会给发送者返回ACK回执
消费者的可靠性
消费者确认机制
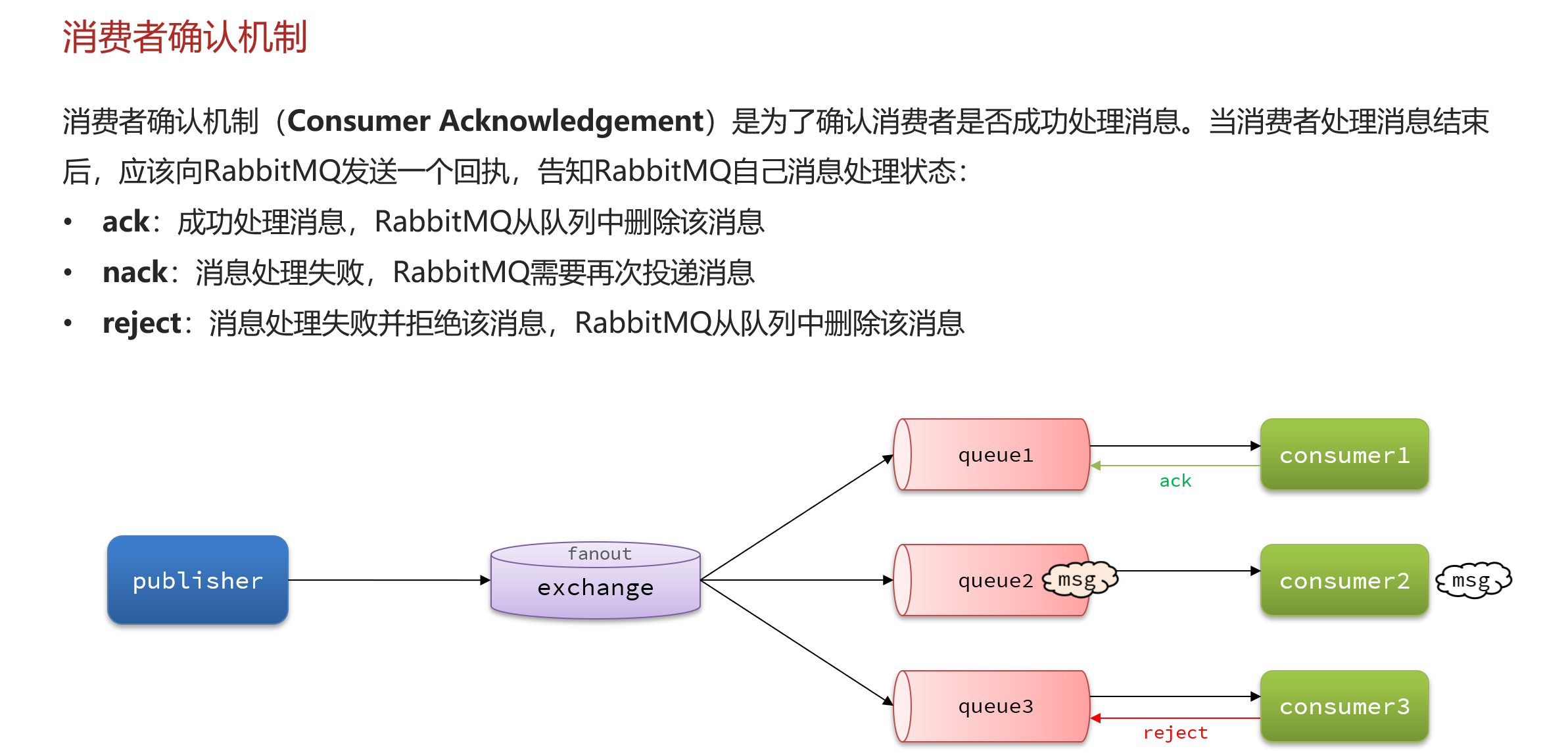
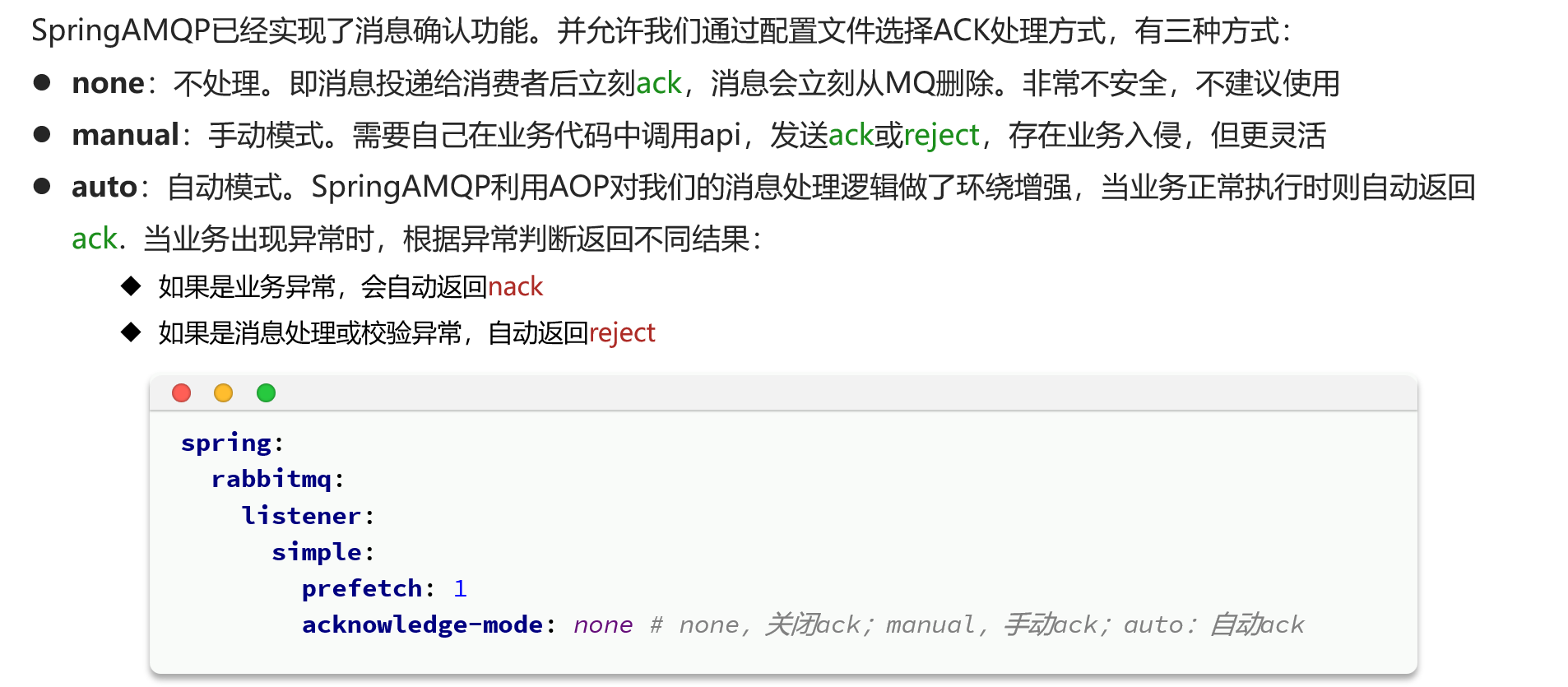
失败重试机制
在配置文件里面加入以下配置就可以了,失败到一定次数,就会自动抛弃信息
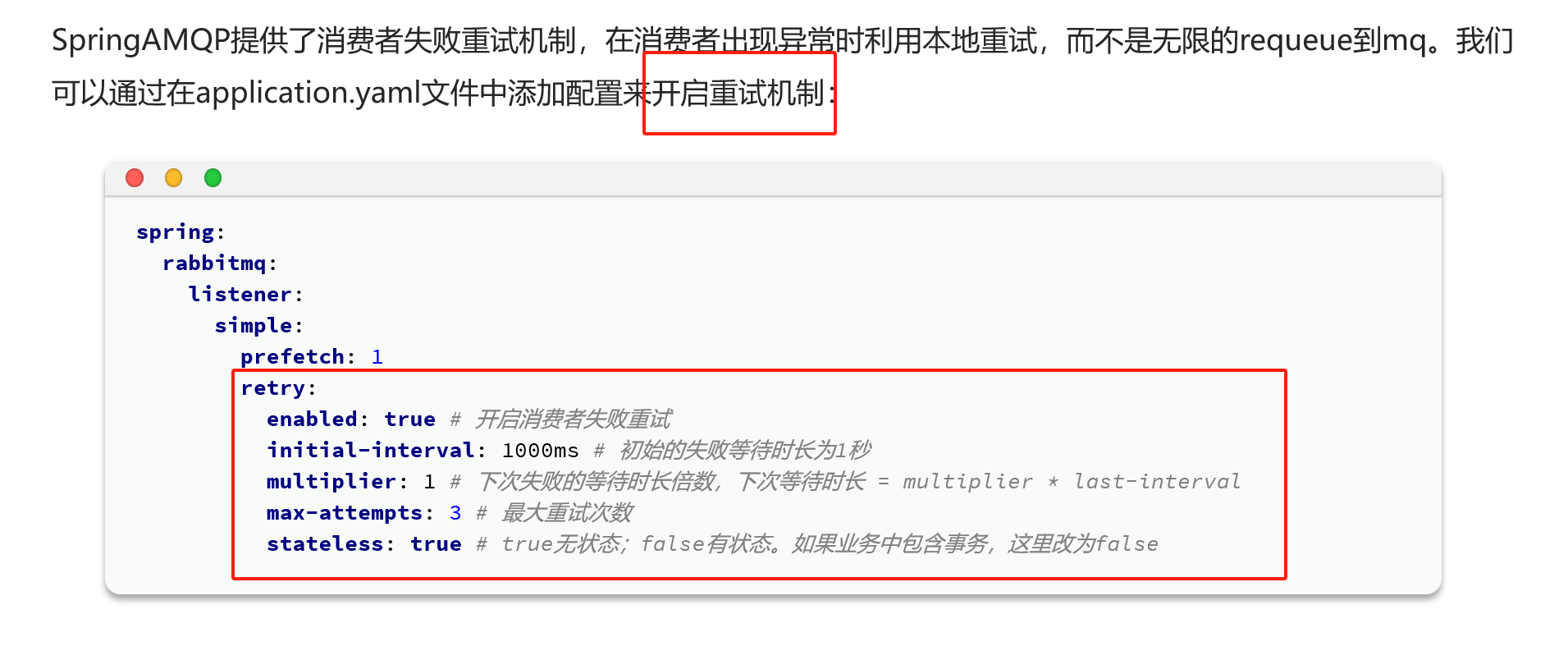
但是要是这样的话,可靠性又不太好了,尝试几次就丢弃,不太好,这种就是默认的第一种策略
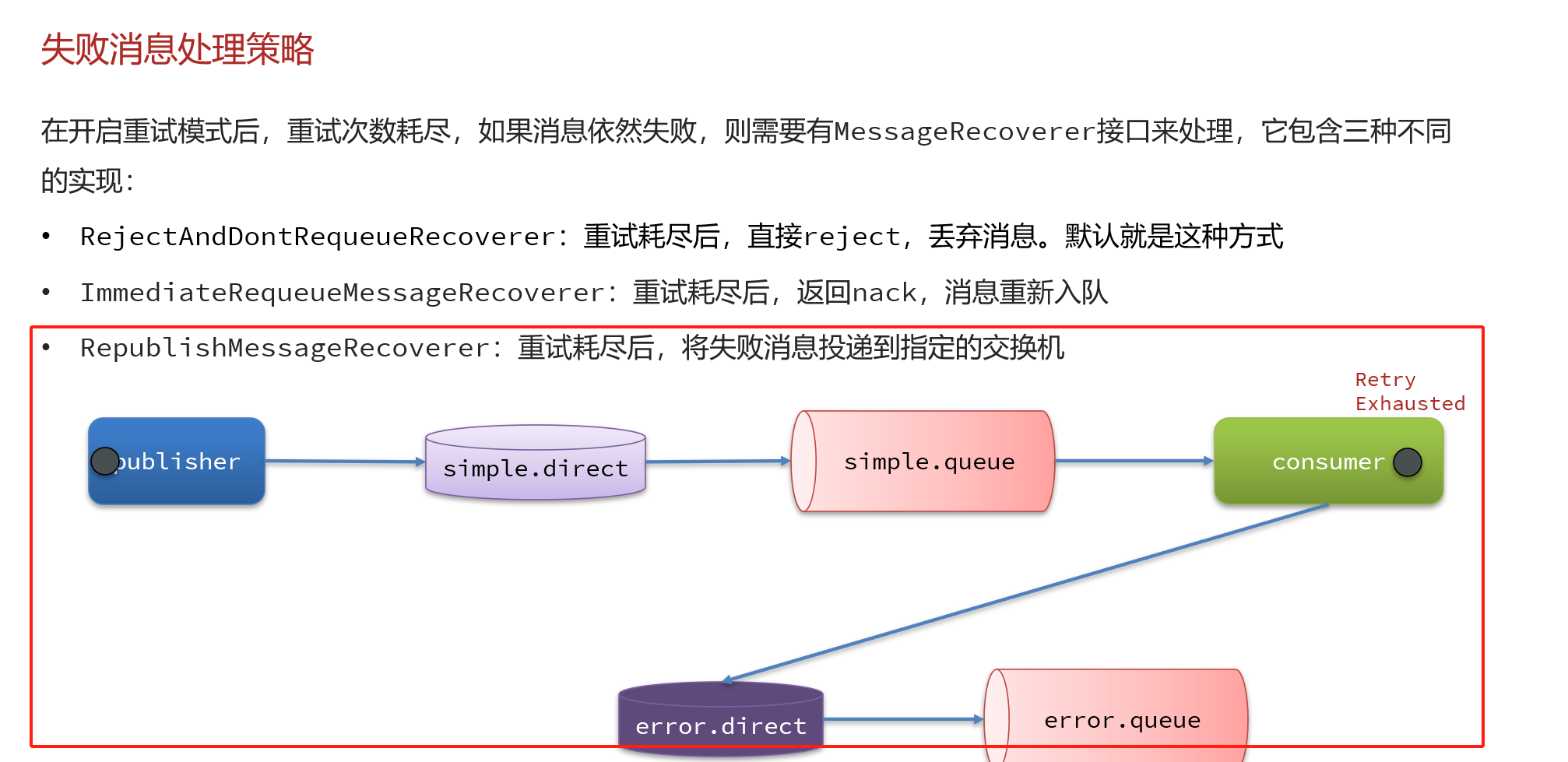
第二种策略就是重新入队列,再重试,相比起来,重试的频率没有第一种的大
第三种就是直接给他换了一个交换机,投到指定地方让人处理

操作代码
@Configuration
public class ErrorMessageConfiguration {
@Bean
public DirectExchange errorMessageExchange(){
return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue(){
return new Queue("error.queue", true);
}
@Bean
public Binding errorBinding(Queue errorQueue, DirectExchange errorMessageExchange){
return BindingBuilder.bind(errorQueue).to(errorMessageExchange).with("error");
}
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){
return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
}前面三个就是创建路由和交换器然后让他们绑定,最后一段的解释如下
- 定义了一个
MessageRecoverer类型的Bean,具体实现为RepublishMessageRecoverer。 RepublishMessageRecoverer的作用是在消费者处理消息发生异常时,捕获这些异常并将未能成功处理的消息重新发布到另一个指定的交换器上。- 在这里,使用了之前定义的
rabbitTemplate来执行消息的重新发布操作,并指定了目标交换器为"error.direct"和路由键为"error"。
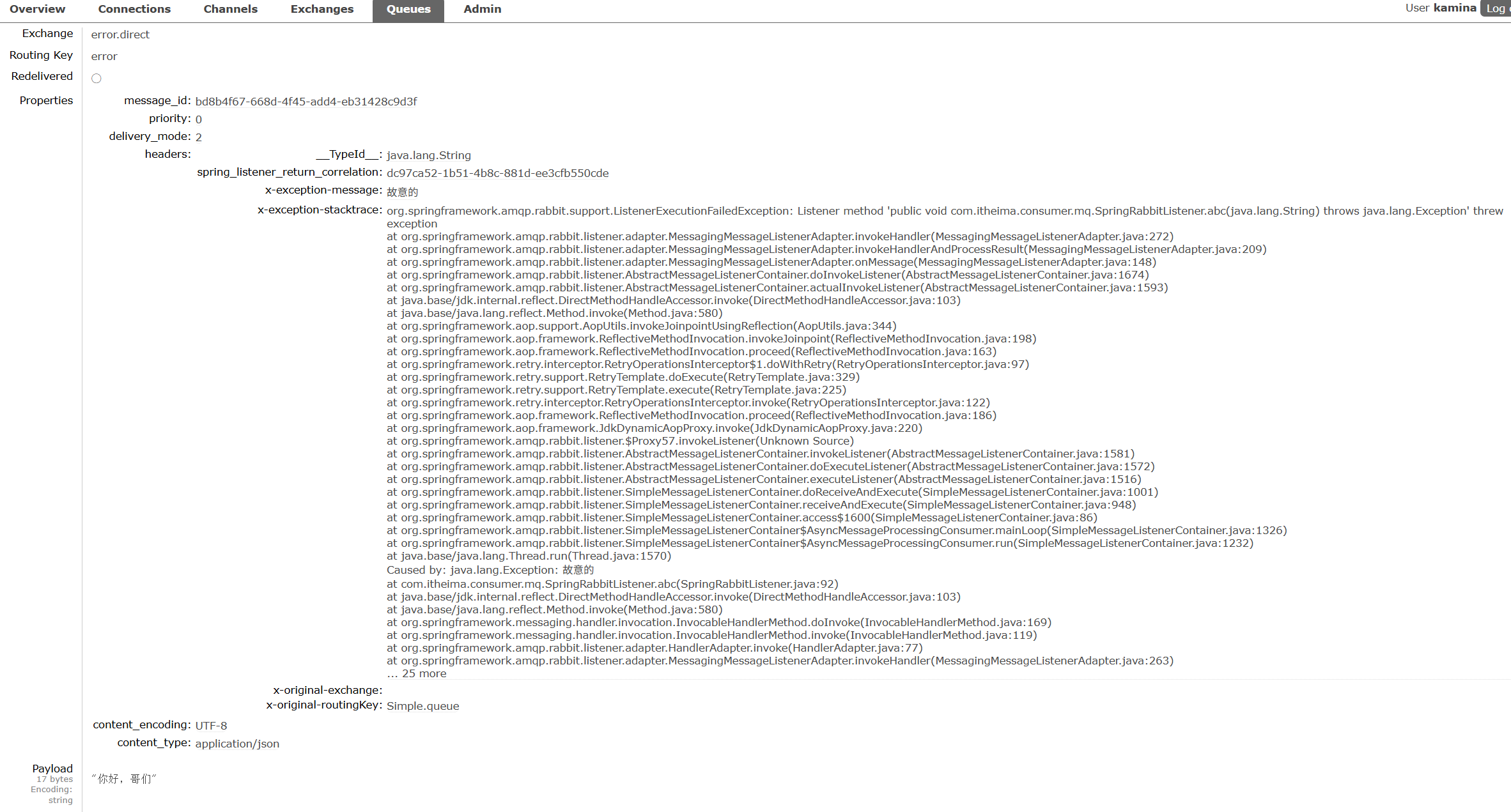
结果如下,转发最高限定次数,转发到其他路由器

再看看MQ,异常信息都直接给你了
业务幂等性
幂等是一个数学概念,用函数表达式来描述是这样的:f(x) = f(f(x)) 。在程序开发中,则是指同一个业务,执行一次或多次对业务状态的影响是一致的。
但是对于扣减库存扣减余额的话,这种业务就不存在幂等性,MQ因为网络波动时,那就有可能扣多次钱或者余额,那么要怎么解决这样的问题?
1.唯一消息id(但有业务侵入性可能,还要查数据库什么的,效率就不太好了)
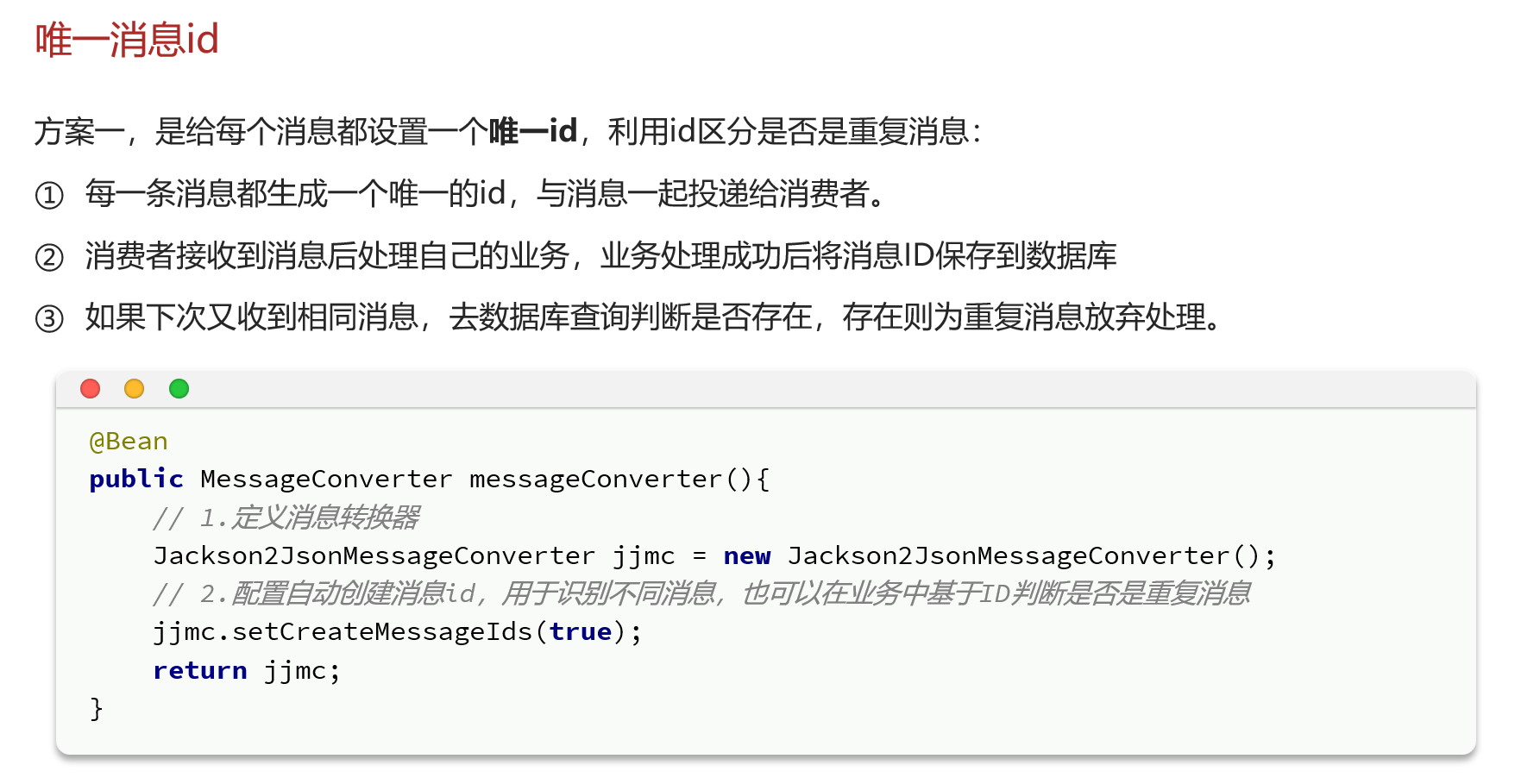
就是红框里面的那段文字
怎么拿?(但是没什么用)
@RabbitListener(queues = "Simple.queue")
public void abc(Message message) throws Exception {
log.info("监听到object.queue消息:{}", message);
}接收的时候改成 Message就好了,什么都有。。。。。。

2.业务判断
是结合业务逻辑,基于业务本身做判断。
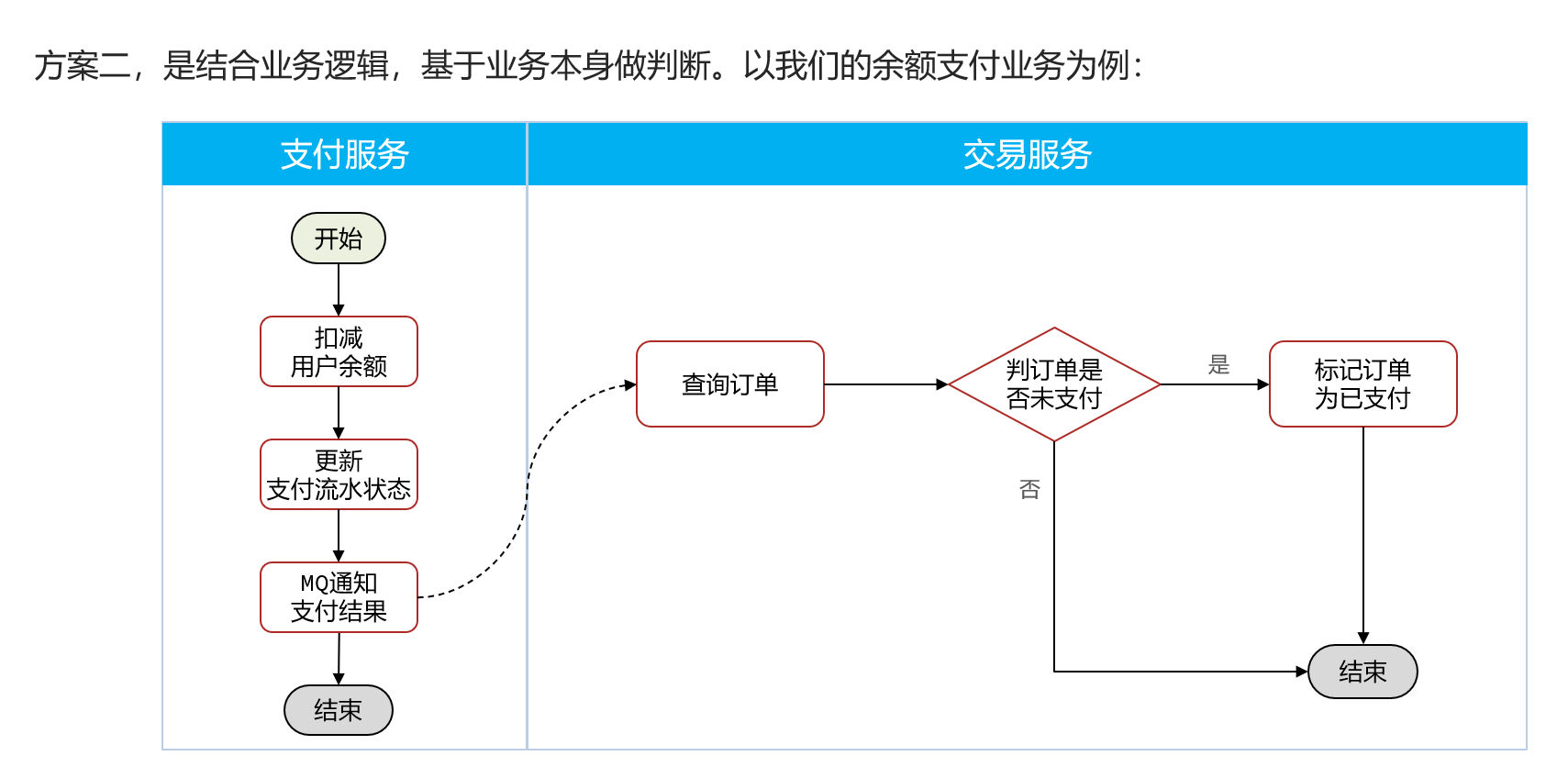
代码实现
public void listenPaySuccess(Long orderId){
//1.查询订单
Order order =orderService.getById(orderId);
//2.判断订单状态是否为待支付
if (order==null || order.getStatus()!=1){
return;
}
//3.标记订单状态为已支付
orderService.markOrderPaySuccess(orderId);
}如何保证支付服务与交易服务之间的订单状态一致性?
如果交易服务消息处理失败,有没有什么兜底方案?
答:我们可以在交易服务设置定时任务,定期查询订单支付状态。这样即便MQ通知失败,还可以利用定时任务作为兜底方案,确保订单支付状态的最终一致性。
延迟消息

死信交换机
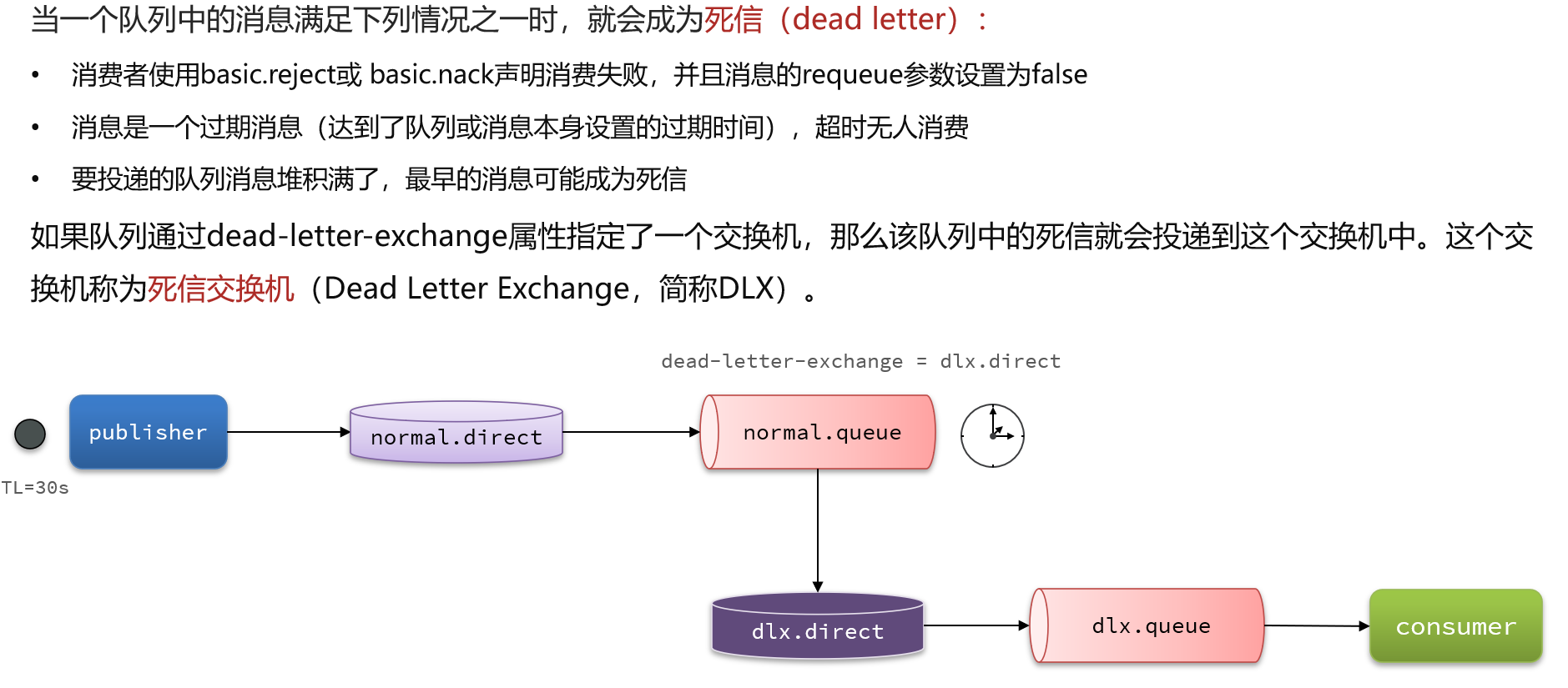
死信交换机有什么作用呢?
-
收集那些因处理失败而被拒绝的消息
-
收集那些因队列满了而被拒绝的消息
-
收集因TTL(有效期)到期的消息
实际操作
1.定义dlx以及其他信息
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "dix.queue",durable = "true"),
exchange = @Exchange(name = "dix.direct", type = ExchangeTypes.DIRECT),
key = {"hi"}
))
public void listenDlx(Message message){
log.info("监听到dix.queue消息:{}", message);
}2.定义normal以及其他信息
@Configuration
public class NormalConfiguration {
@Bean
public DirectExchange normalExchange(){
return new DirectExchange("normal.direct");
}
@Bean
public Queue normalQueue(){
return QueueBuilder.durable("normal.queue").deadLetterExchange("dix.direct").build();
}
@Bean
public Binding normalBinding(Queue normalQueue, DirectExchange normalExchange){
return BindingBuilder.bind(normalQueue).to(normalExchange).with("hi");
}
}其中的第二段QueueBuilder.durable("normal.queue").deadLetterExchange("dix.direct").build()就是拿来绑定死信交换机的,就跟图上一样。
3.发送消息(定义一个五秒钟过期的信息,五秒后就会自动进入死信交换机中被消费)(模拟延迟发送)
@Test
void testSendDelayMessage(){
rabbitTemplate.convertAndSend("normal.direct","hi","hello",message -> {
message.getMessageProperties().setExpiration("5000");
return message;
});
}4.结果(可以看出确实相隔五秒)


延迟消息插件
这个插件可以将普通交换机改造为支持延迟消息功能的交换机,当消息投递到交换机后可以暂存一定时间,到期后再投递到队列。
可以用两种方法来创建延迟交换机和队列
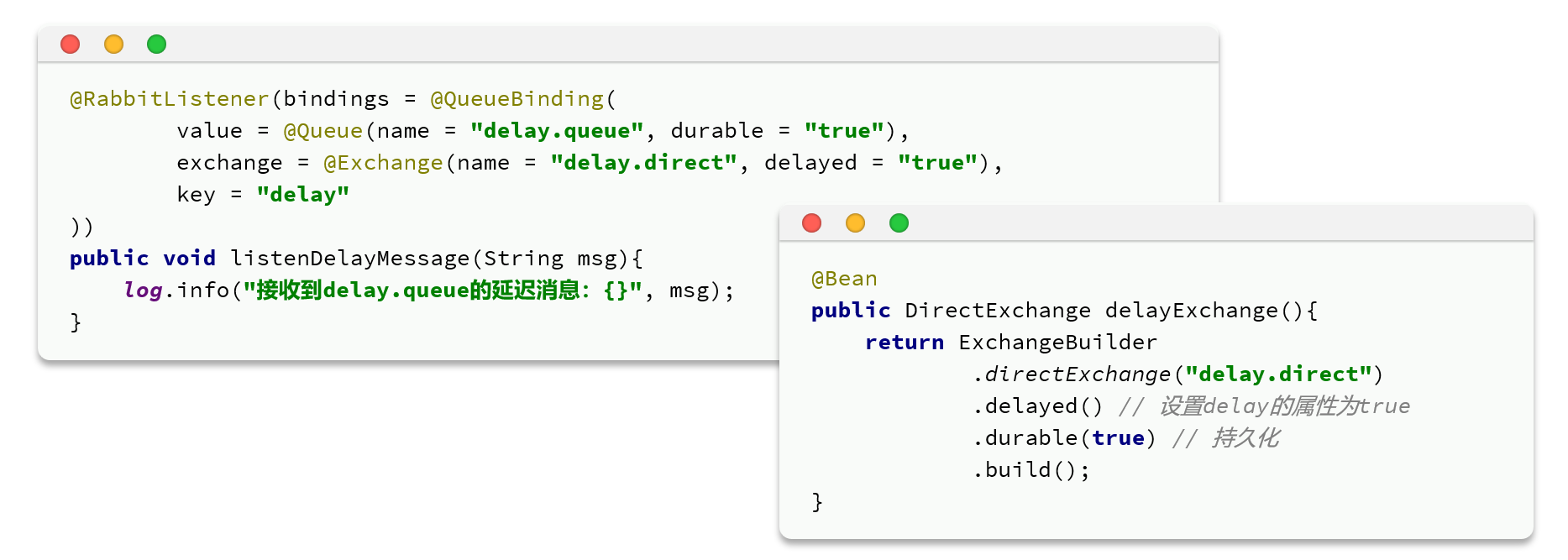
发送消息
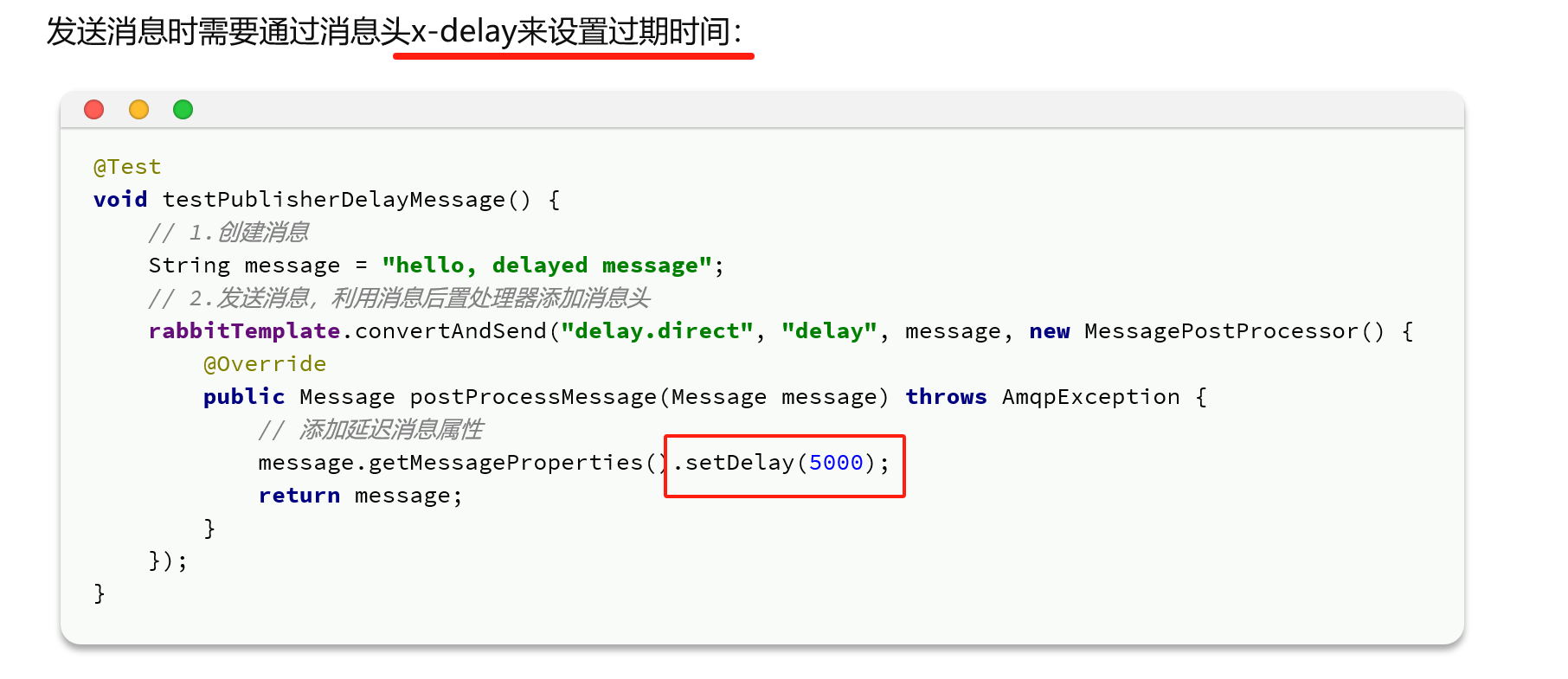
实际操作:
1.定义一个延迟交换机并绑定其队列
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "delay.queue",durable = "true"),
exchange = @Exchange(name = "delay.direct", delayed = "true"),
key = {"hi"}
))
public void listenDelay(Message message){
log.info("监听到delay.queue消息:{}", message);
}2.发送信息体要求使用 setDelay来设置过期时间
@Test
void testSendDelayMessage2(){
rabbitTemplate.convertAndSend("delay.direct","hi","hello00000",message -> {
message.getMessageProperties().setDelay(10000);
return message;
});
}3.结果示意(对比上下两图,确实发送信息和收到信息相隔了约定的10秒)


八、Elasticsearch(高性能分布式搜索引擎)(上半)

前置知识
倒排索引
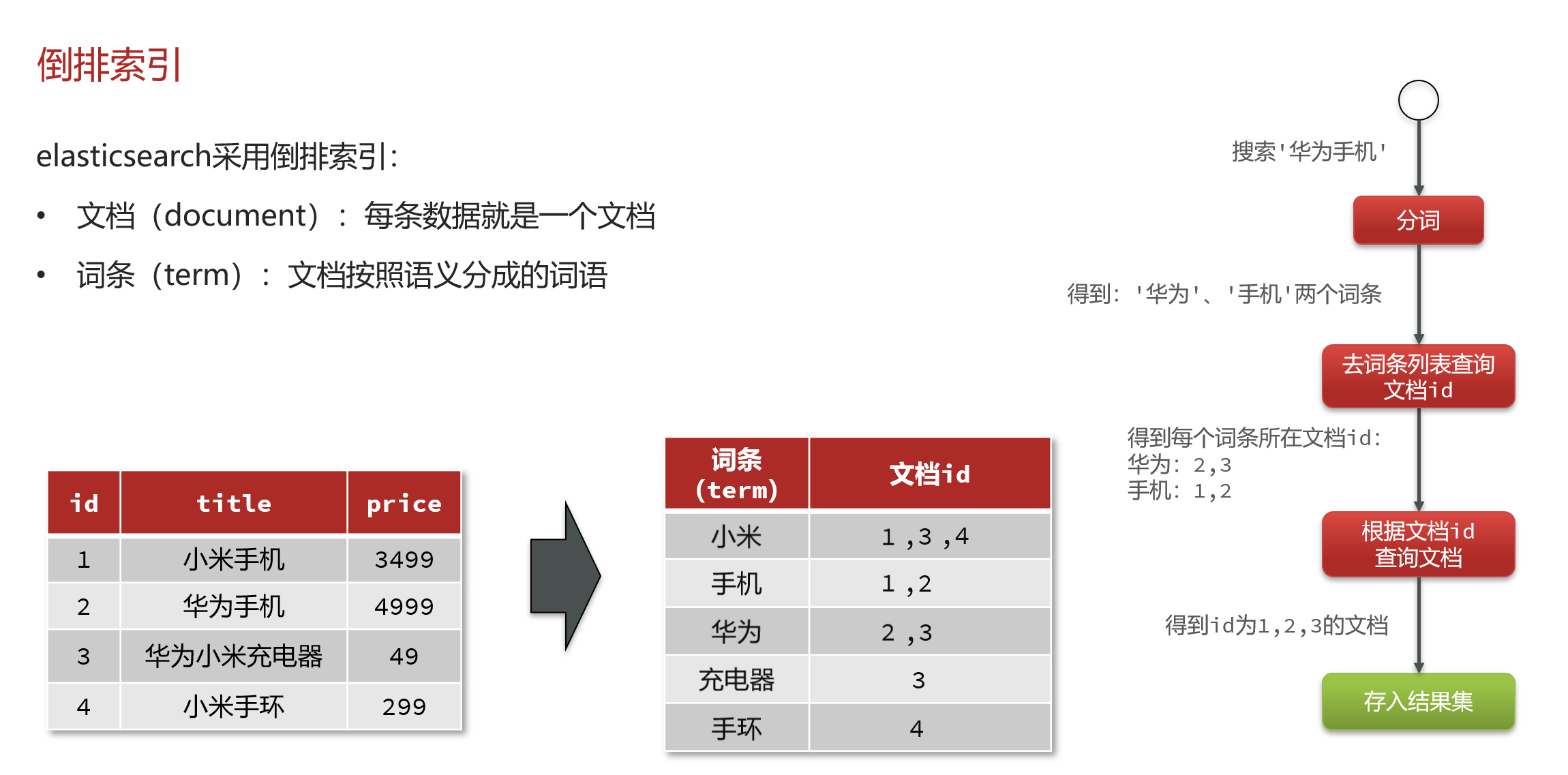
1.什么是文档和词条?
• 每一条数据就是一个文档
• 对文档中的内容分词,得到的词语就是词条
2.什么是正向索引?
• 基于文档id创建索引。根据id查询快,但是查询词条时必须先找到文档,而后判断是否包含词条
3.什么是倒排索引?
• 对文档内容分词,对词条创建索引,并记录词条所在文档的id。查询时先根据词条查询到文档id,而后根据文档id查询文档
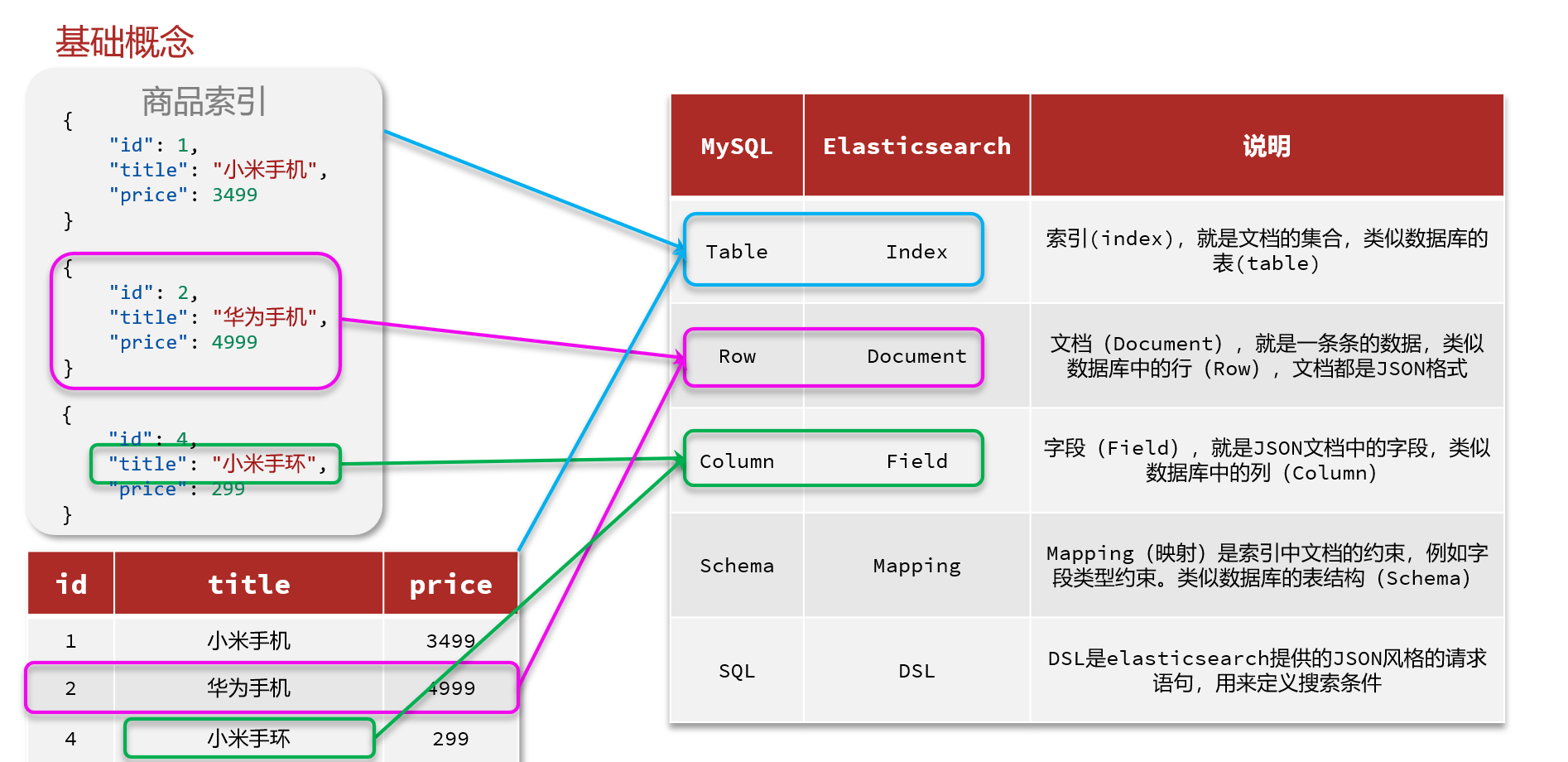
基础概念
elasticsearch中的文档数据会被序列化为json格式后存储在elasticsearch中。就像下图一样


索引库操作
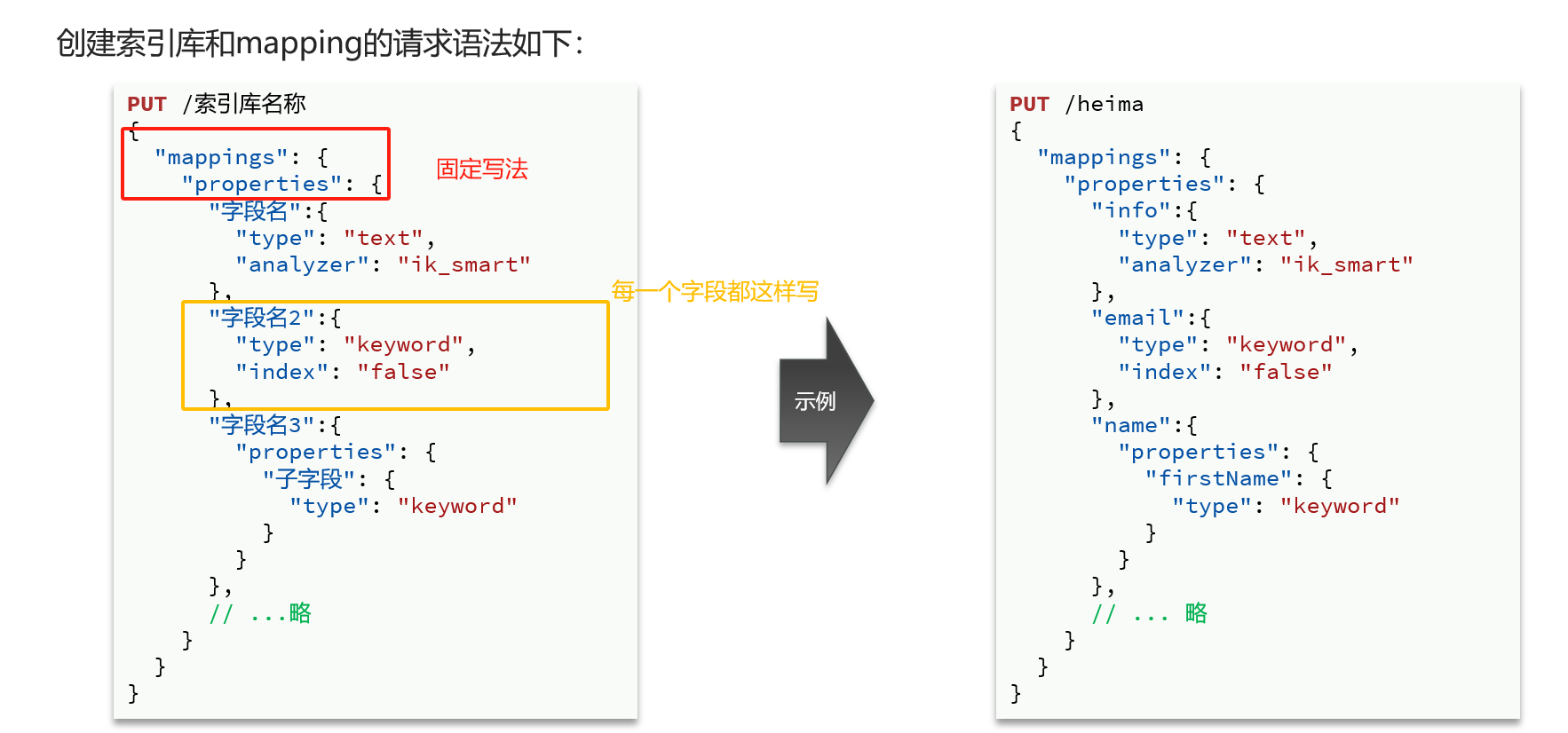
Mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
•type:字段数据类型,常见的简单类型有:
•字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
•数值:long、integer、short、byte、double、float、
•布尔:boolean
•日期:date
•对象:object
•index:是否创建索引,默认为true
•analyzer:使用哪种分词器
•properties:该字段的子字段
索引库操作
增(创建索引库):PUT /
删(删除索引库):DELETE /
查(查询索引库):GET /
添加字段 :PUT /{名字}/_mapping

不支持对已有的索引库进行修 改
文档操作
文档CRUD(其实就相当于操作数据库里面的数据)
新增(相当于数据库的插入数据)
 查看(相当于select) 删除(相当于Delete)
查看(相当于select) 删除(相当于Delete)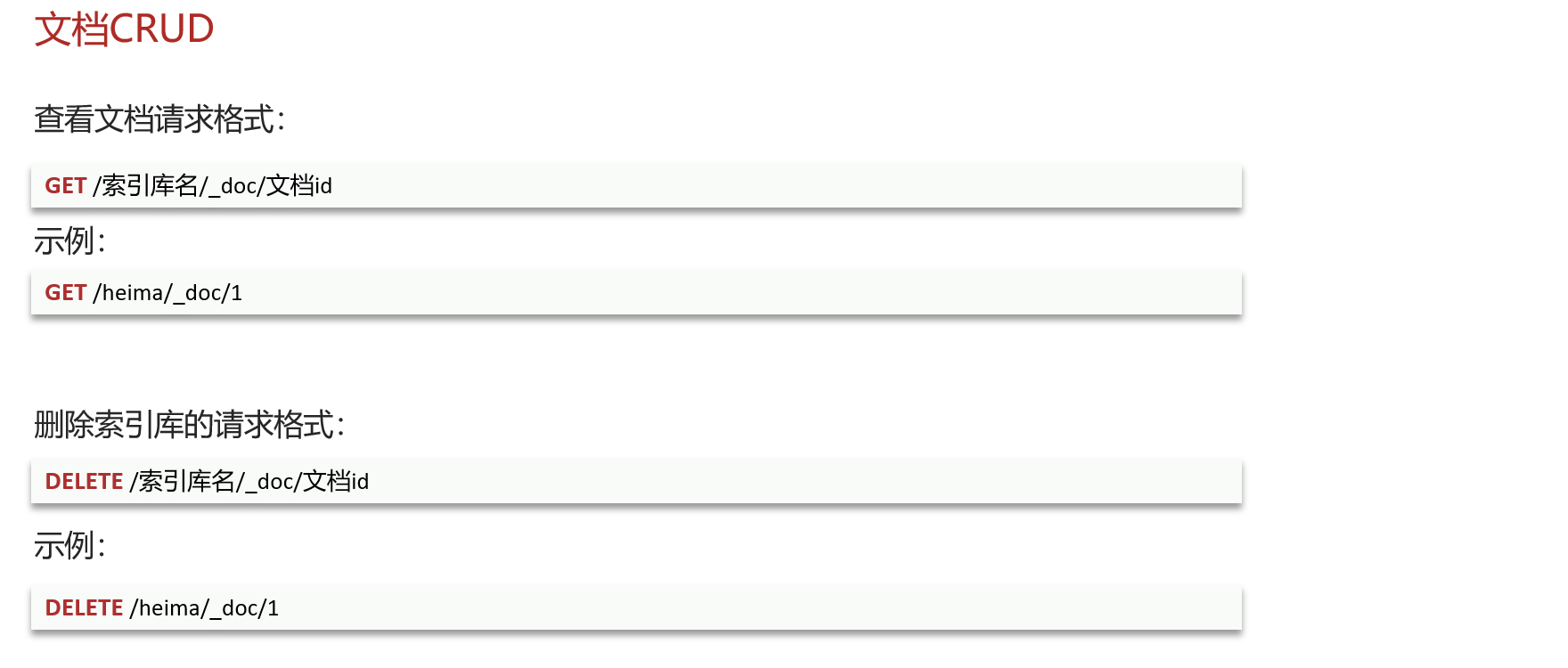
关于修改有两种方式(全量修改和增量修改,具体例子看图片)(相当于Update)

小知识点:PUT也不一定是用于修改,也可以用来新增, 所以直接记住PUT就好了
总结
•创建文档:POST /索引库名/_doc/文档id { json文档 }
•查询文档:GET /索引库名/_doc/文档id
•删除文档:DELETE /索引库名/_doc/文档id
•修改文档:
•全量修改:PUT /索引库名/_doc/文档id { json文档 }
•增量修改:POST /索引库名/_update/文档id { "doc": {字段}}
批量处理

JavaRestClient (Java客户端操作)
客户端初始化
1.引依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>2.覆盖版本(主要是和我现在的版本匹配,可选)
<elasticsearch.version>7.12.1</elasticsearch.version>3.初始化(样例)
public class ElasticTest {
private RestHighLevelClient restHighLevelClient;
@Test
void test(){
System.out.println(restHighLevelClient);
}
@BeforeEach
void setUp(){
restHighLevelClient = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.9.50:9200")
));
}
@AfterEach
void tearDown(){
if (restHighLevelClient != null) {
try {
restHighLevelClient.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
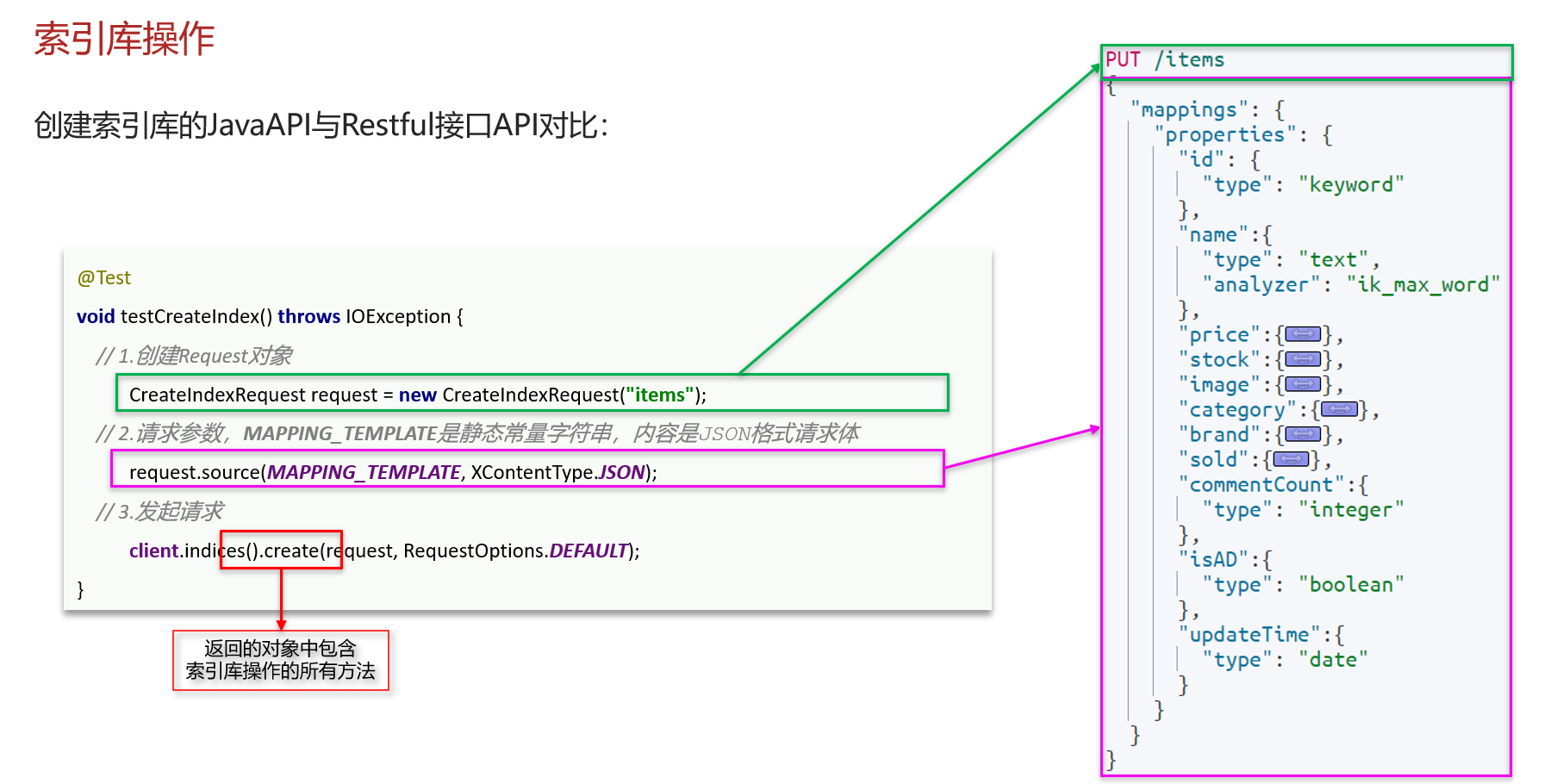
}索引库操作

实际操作
private RestHighLevelClient restHighLevelClient;
@Test//增
void testCreateIndex() throws IOException {
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("items");
// 2.准备请求参数
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// 3.发送请求
restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
}
@Test//删
void testDeleteIndex() throws IOException {
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("items");
// 2.发送请求
restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
}
@Test//查
void testGetIndex() throws IOException {
// 1.创建Request对象
GetIndexRequest request = new GetIndexRequest("items");
// 2.发送请求(这里是判断下数据库存不存在,用exists,当然也可以get)
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("ex == "+exists);
}文档操作

实际操作
@Test
void testCreateIndex() throws IOException {
//1.准备Request
IndexRequest request = new IndexRequest("items").id("1");
//2.准备参数
request.source("{}", XContentType.JSON);
//3.发送请求
restHighLevelClient.index(request, RequestOptions.DEFAULT);
}文档的CRUD



实际操作
@Test//查询
void testGetDoc() throws IOException {
//1.准备Request
GetRequest request = new GetRequest("items", "2252804");
//2.发送请求
GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
ItemDoc doc = JSONUtil.toBean(json, ItemDoc.class);
System.out.println("Doc == "+doc);
}
@Test//删除
void testDeleteDoc() throws IOException {
//1.准备Request
DeleteRequest request = new DeleteRequest("items", "2252804");
//2.发送请求
restHighLevelClient.delete(request, RequestOptions.DEFAULT);
}
@Test//更新(局部)
void testUpdateDoc() throws IOException {
//1.准备Request
UpdateRequest request = new UpdateRequest("items", "2252804");
//2.准备参数
request.doc(
"price", 2566
);
//2.发送请求
restHighLevelClient.update(request, RequestOptions.DEFAULT);
}批量处理
批处理代码流程与之前类似,只不过构建请求会用到一个名为BulkRequest来封装普通的CRUD请求
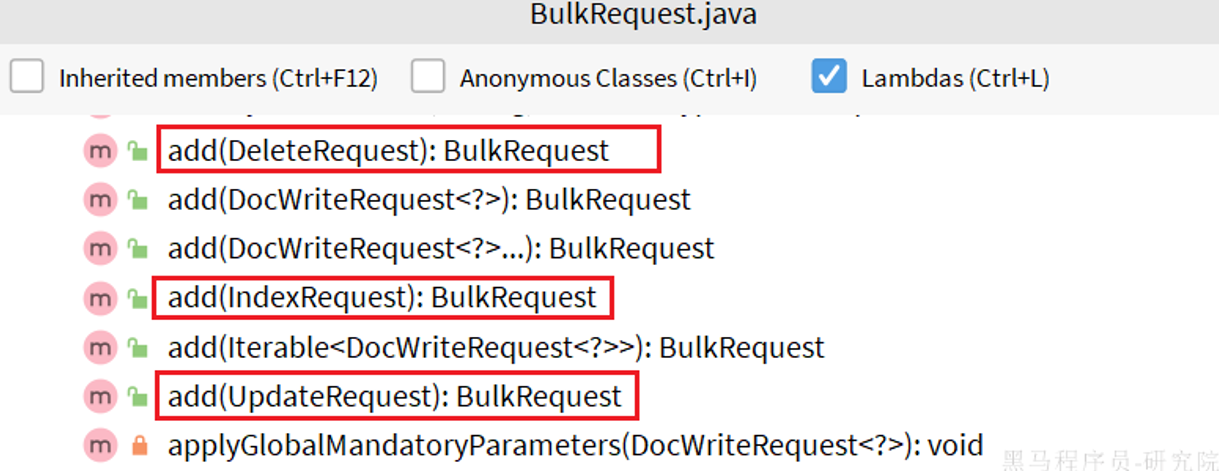
直接用实际案例了....
@Test//批量
void testBulkDoc () throws IOException {
int pageNo = 1;
int pageSize = 500;
while(true){
Page<Item> page = itemService.lambdaQuery()
.eq(Item::getStatus, 1)
.page(Page.of(pageNo, pageSize));
List<Item> records = page.getRecords();
if (records == null || records.isEmpty()) {
return;
}
//1.准备Request
BulkRequest request = new BulkRequest();
//2.添加请求参数
for(Item item : records){
request.add(new IndexRequest("items")
.id(item.getId().toString())
.source(JSONUtil.toJsonStr(JSONUtil.toJsonStr(BeanUtil.copyProperties(item, ItemDoc.class))), XContentType.JSON));
}
/*request.add(new DeleteRequest("items", "2252804"));
request.add(new UpdateRequest("items", "2252804").doc("price", 2566));*/
//批量删除和批量修改的样子在上面
//3.发送请求
restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
pageNo++;
}
}九、Elasticsearch(下半)
DSL查询
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)语句以JSON格式来定义查询条件。
DSL查询可以分为两大类:
在查询以后,还可以对查询的结果做处理,包括:

叶子查询
叶子查询还可以进一步细分,常见的有:
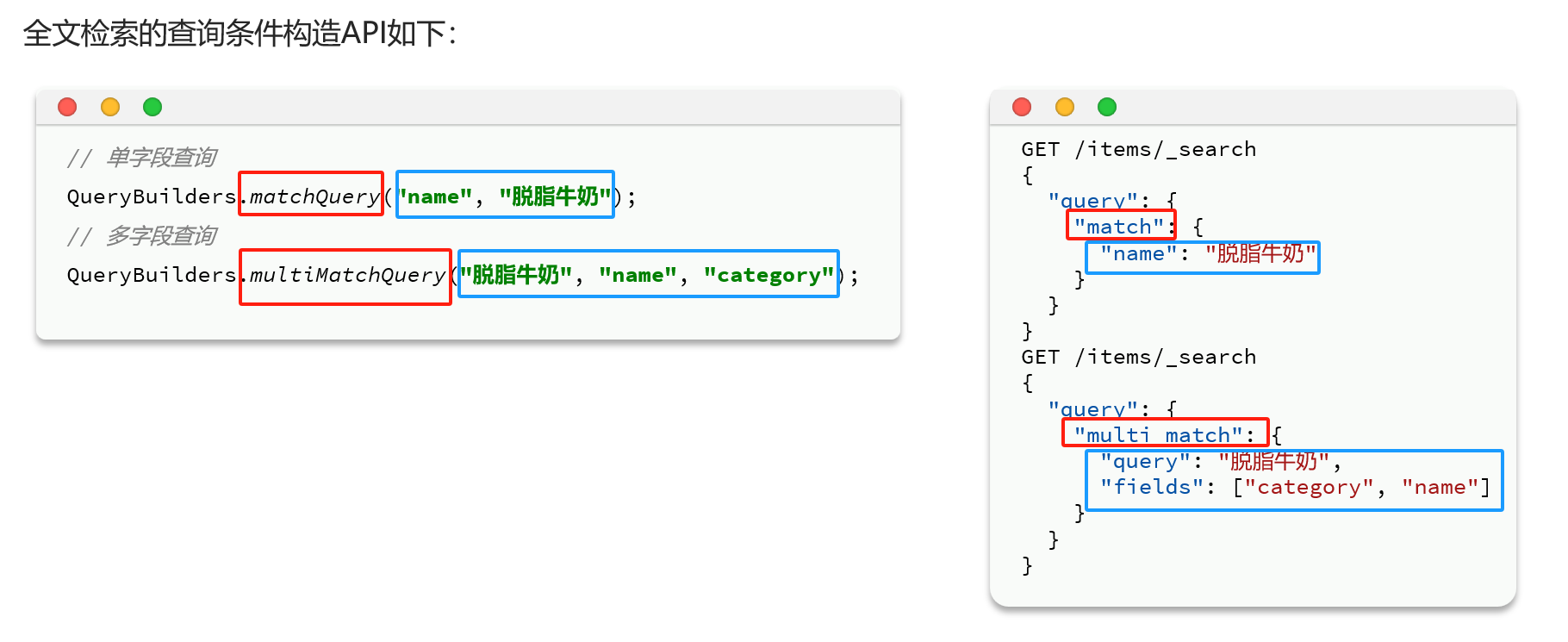
全文检索

案例
GET /items/_search
{
"query": {
"match": {
"name": "牛奶"
}
}
}
GET /items/_search
{
"query": {
"multi_match": {
"query": "牛奶",
"fields": ["name","category"]
}
}
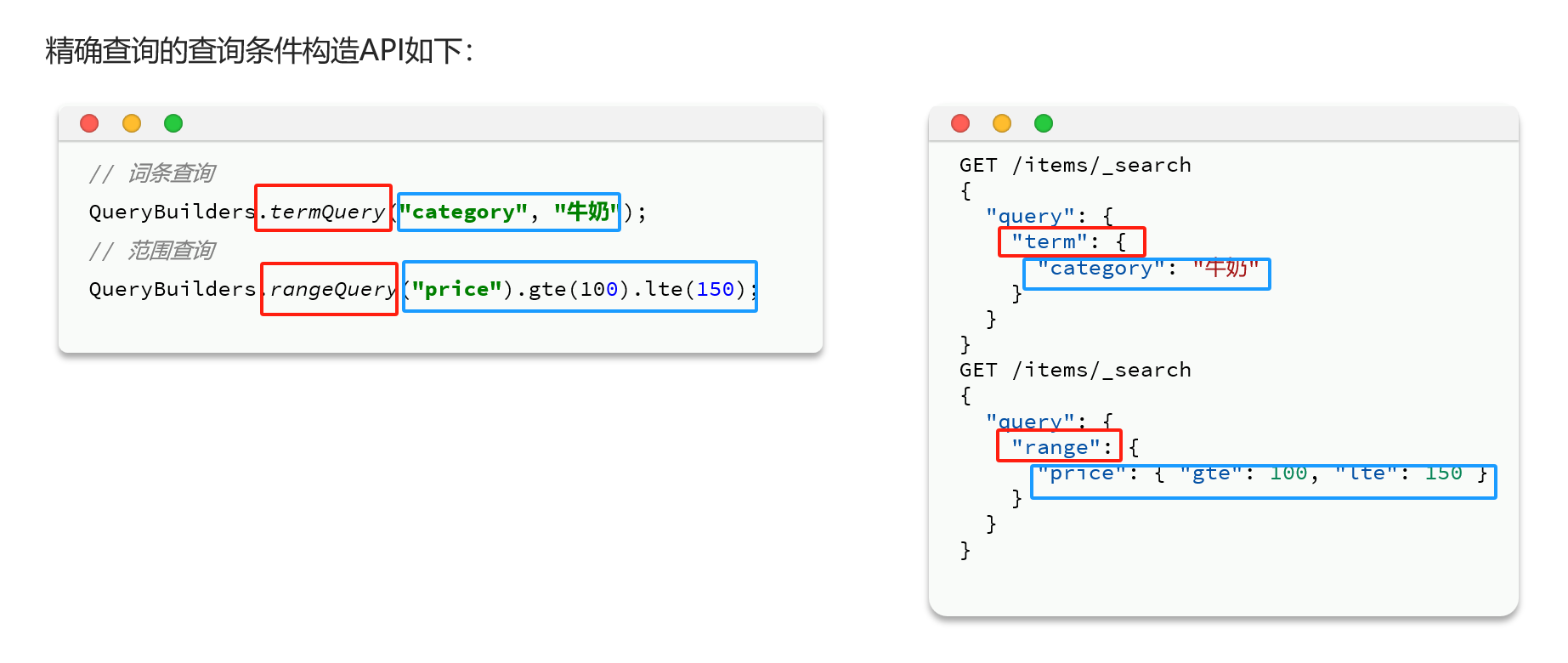
}精确查询
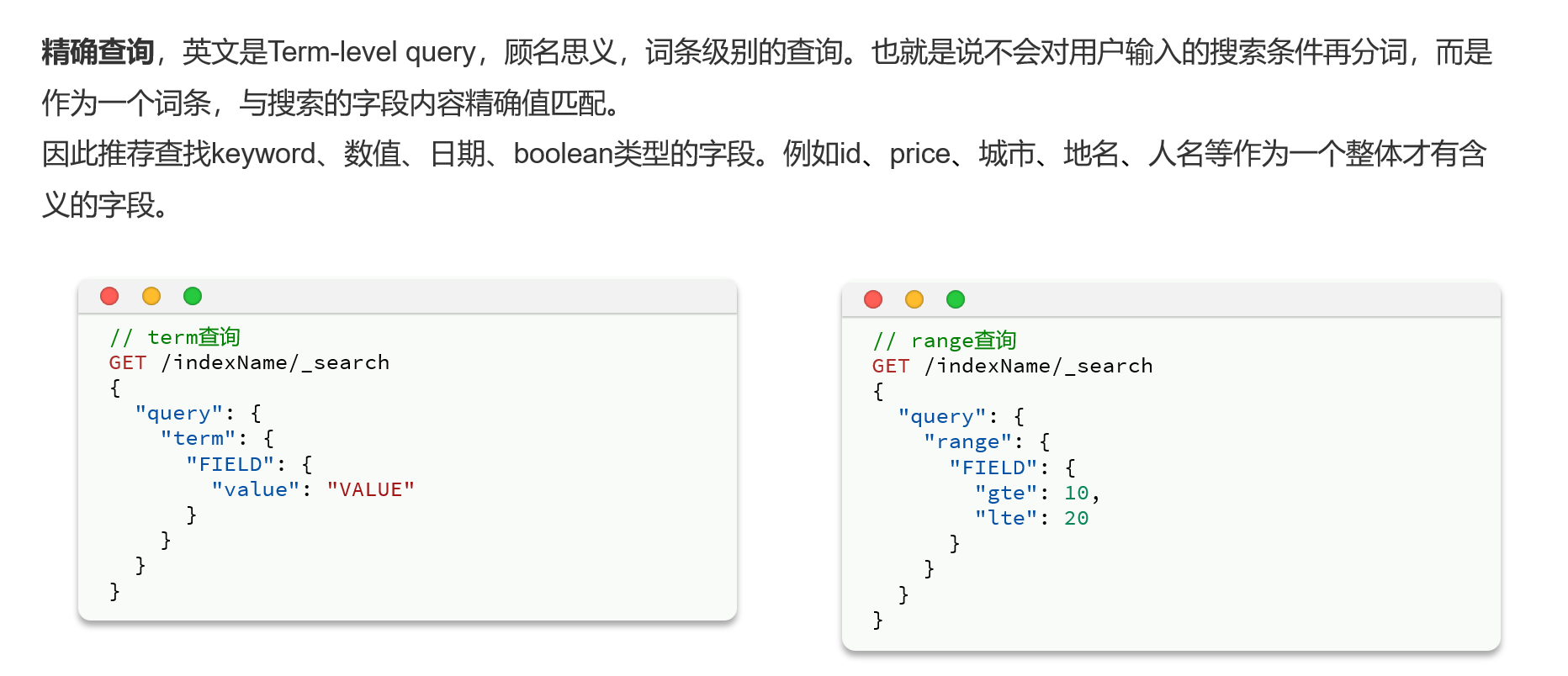
案例
GET /items/_search
{
"query": {
"term": {
"category": {
"value":"牛奶"
}
}
}
}
GET /items/_search
{
"query": {
"range": {
"price": {
"gte": 500000
, "lte": 1000000
}
}
}
}
GET /items/_search
{
"query": {
"ids": {
"values": ["1861099","1861100"]
}
}
}复合查询
复合查询大致可以分为两类:
1.第一类:基于逻辑运算组合叶子查询,实现组合条件,例如:bool
2.第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:function_score dis_max
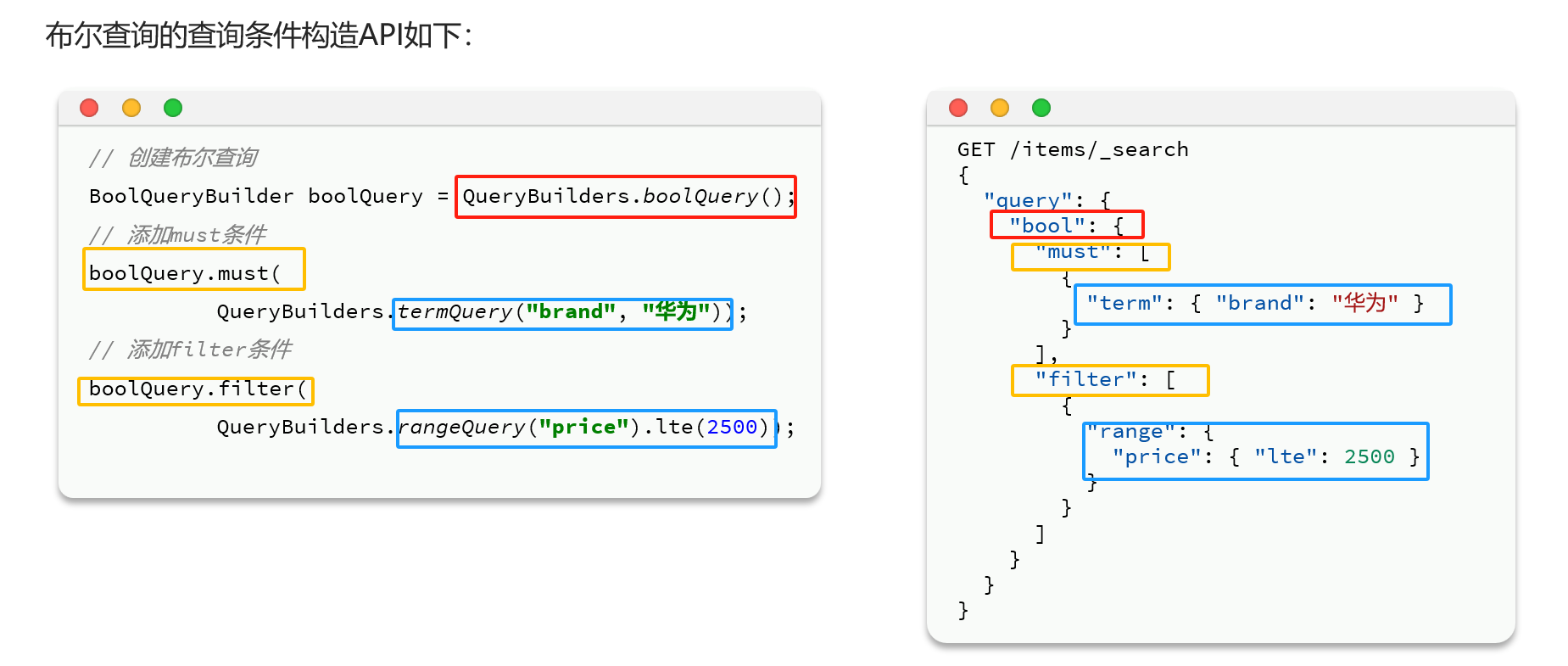
布尔查询
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
需求:我们要搜索"智能手机",但品牌必须是华为,价格必须是900~1599
实际案例
GET /items/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "智能手机"
}
}
],"filter": [
{
"term": {
"brand": "华为"
}
},
{
"range": {
"price": {
"gte": 90000,
"lte": 159900
}
}
}
]
}
}
}排序与分页
排序
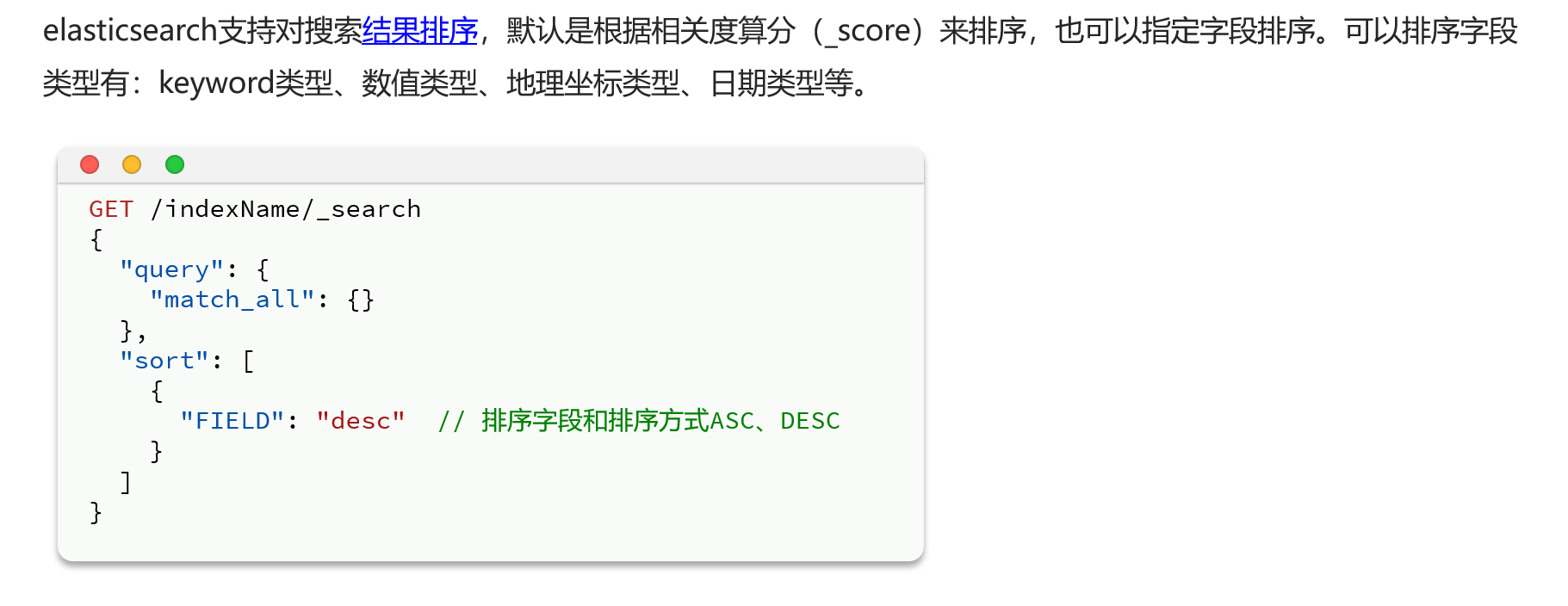
实际案例
需求:搜索商品,按照销量排序,销量一样则按照价格升序
GET /items/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"sold": "desc"
},
{
"price": "asc"
}
]
}分页
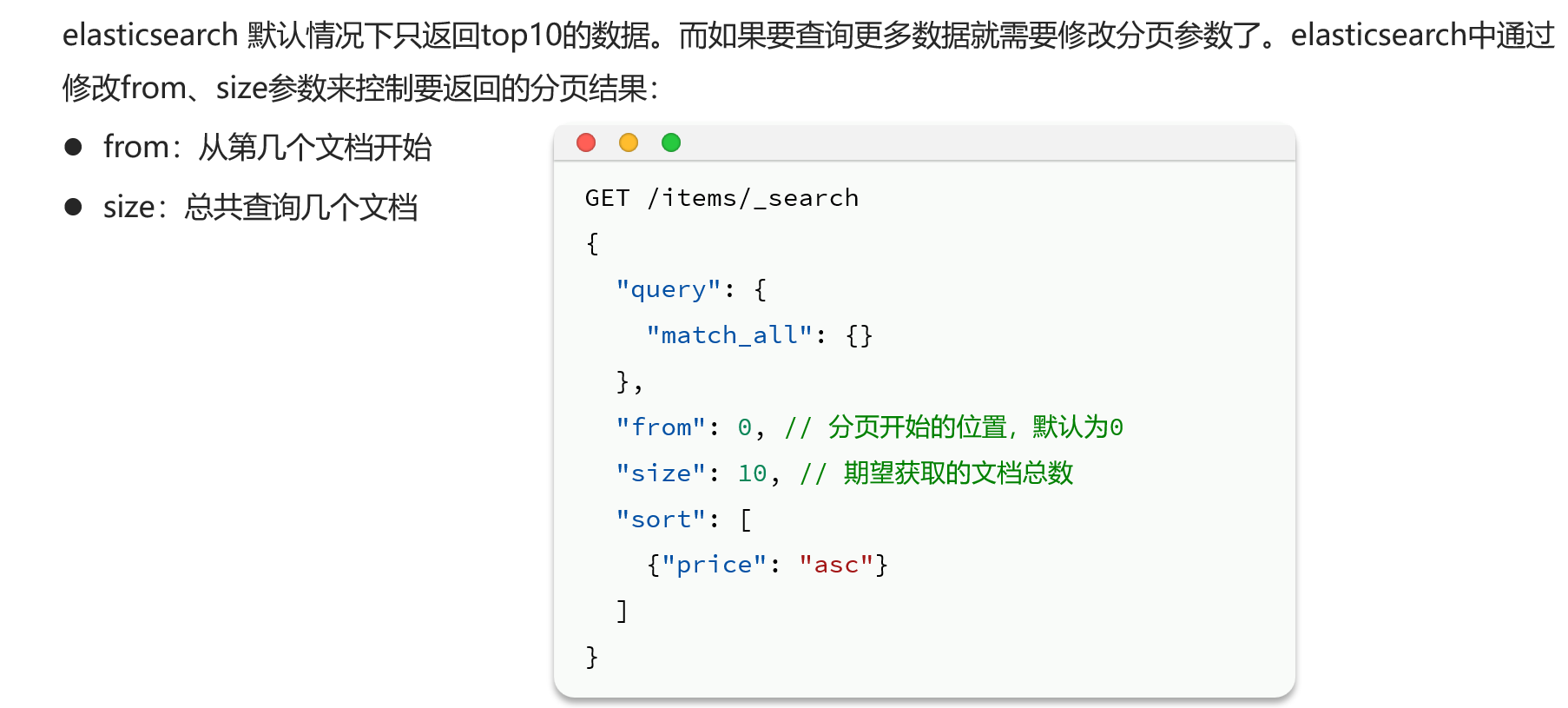
实际案例
需求:搜索商品,查询出销量排名前3的商品,销量一样时按照价格升序
那就在上面的代码下加入两个参数即可
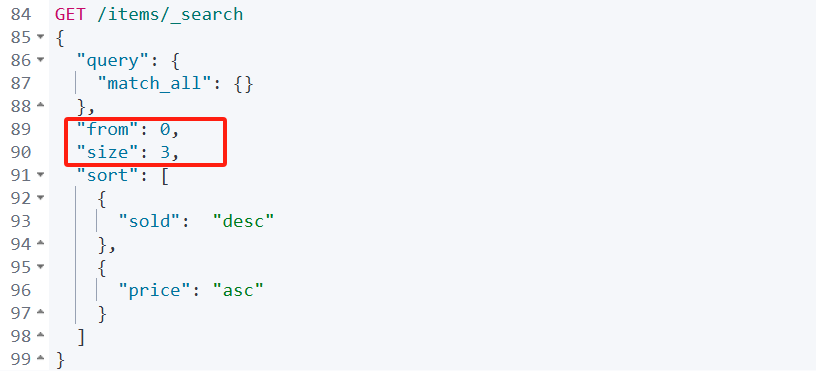
深度分页问题
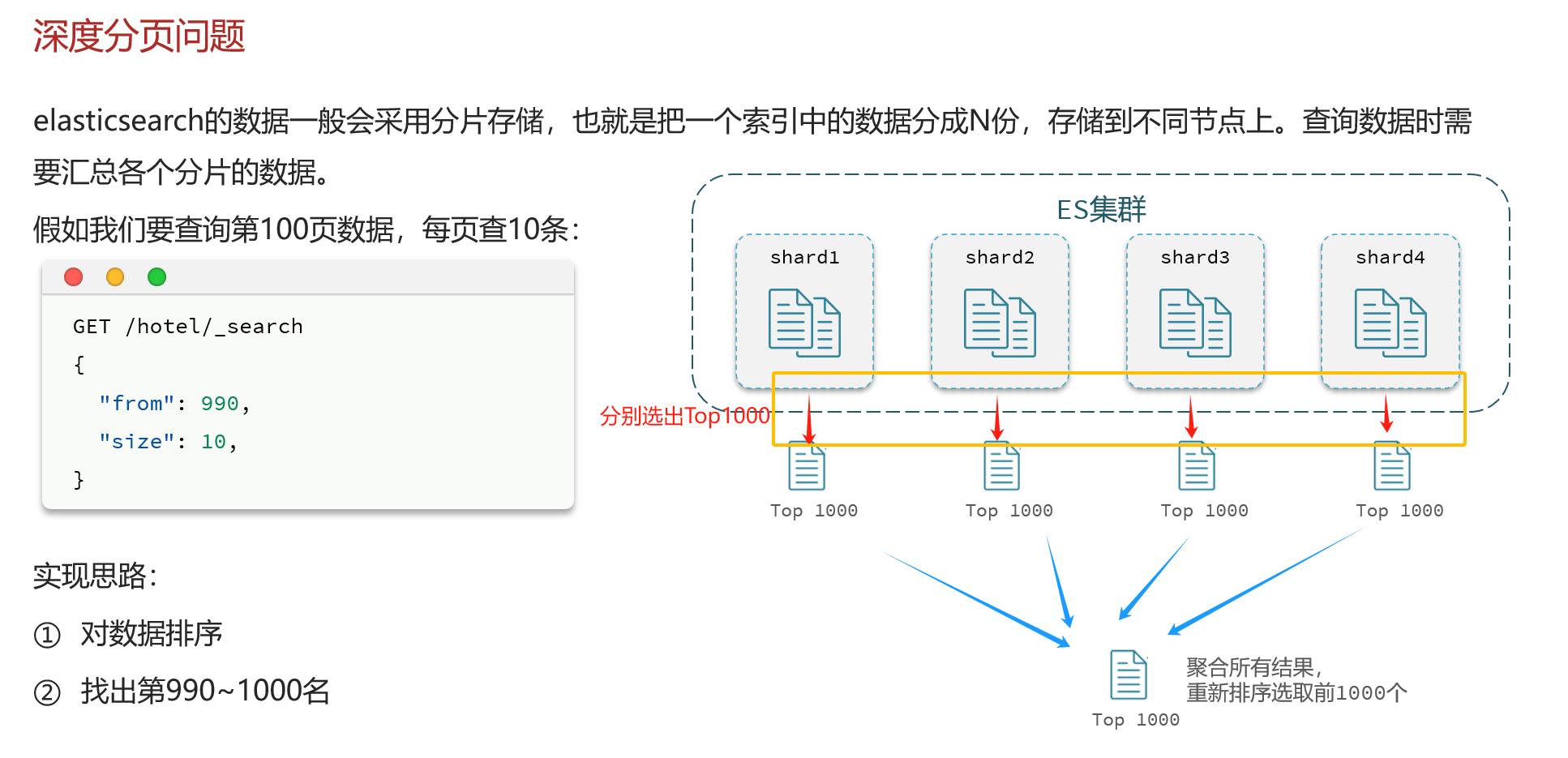
但是,如果后面要查99990~100000名的数据甚至更深呢,同样的方法会给服务器带来巨大的压力,性能就因此下降。
于是乎,就有以下方法(search-after方法)

search-after
官方解释
search_after 是一种分页技术,适用于深度分页场景。它通过利用前一个查询结果集中的最后一个排序值作为下一个查询的起点,来实现连续翻页效果。
主要特点:
1.基于唯一排序字段:为了保证每次查询的结果是唯一的,通常需要基于一个或多个唯一字段进行排序。比如可以使用时间戳加上文档ID(如 _id)来确保排序的唯一性。
2.不支持随机访问:search_after 只能逐页顺序访问,无法直接跳转到任意指定页面。
3.性能优势:相比传统的 from 和 size 参数,search_after 在处理大数据量时具有更好的性能,因为它不需要跳过之前的结果集,从而减少了内存消耗和处理时间。
简单易懂的解释
想象一下你正在组织一场马拉松比赛,并且想要按照选手到达终点的时间顺序列出所有选手的成绩。由于参赛者众多,你不能一次性把所有的成绩都列出来,而是希望一页页地查看成绩列表。
在这种情况下,search-after就像是你在查看完第一页的成绩后,记住最后一名选手的成绩(比如他的到达时间),然后告诉系统:“下一次请从这个成绩之后的选手开始给我展示。”这样,你就能够一页页地查看全部选手的成绩,而不会漏掉任何一个人。
高亮显示
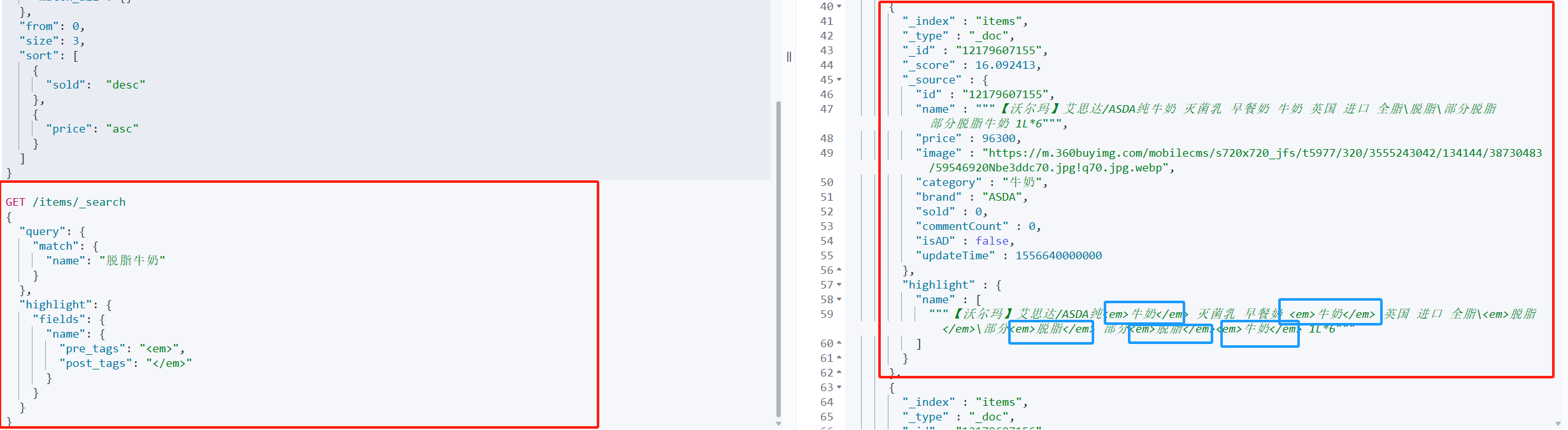
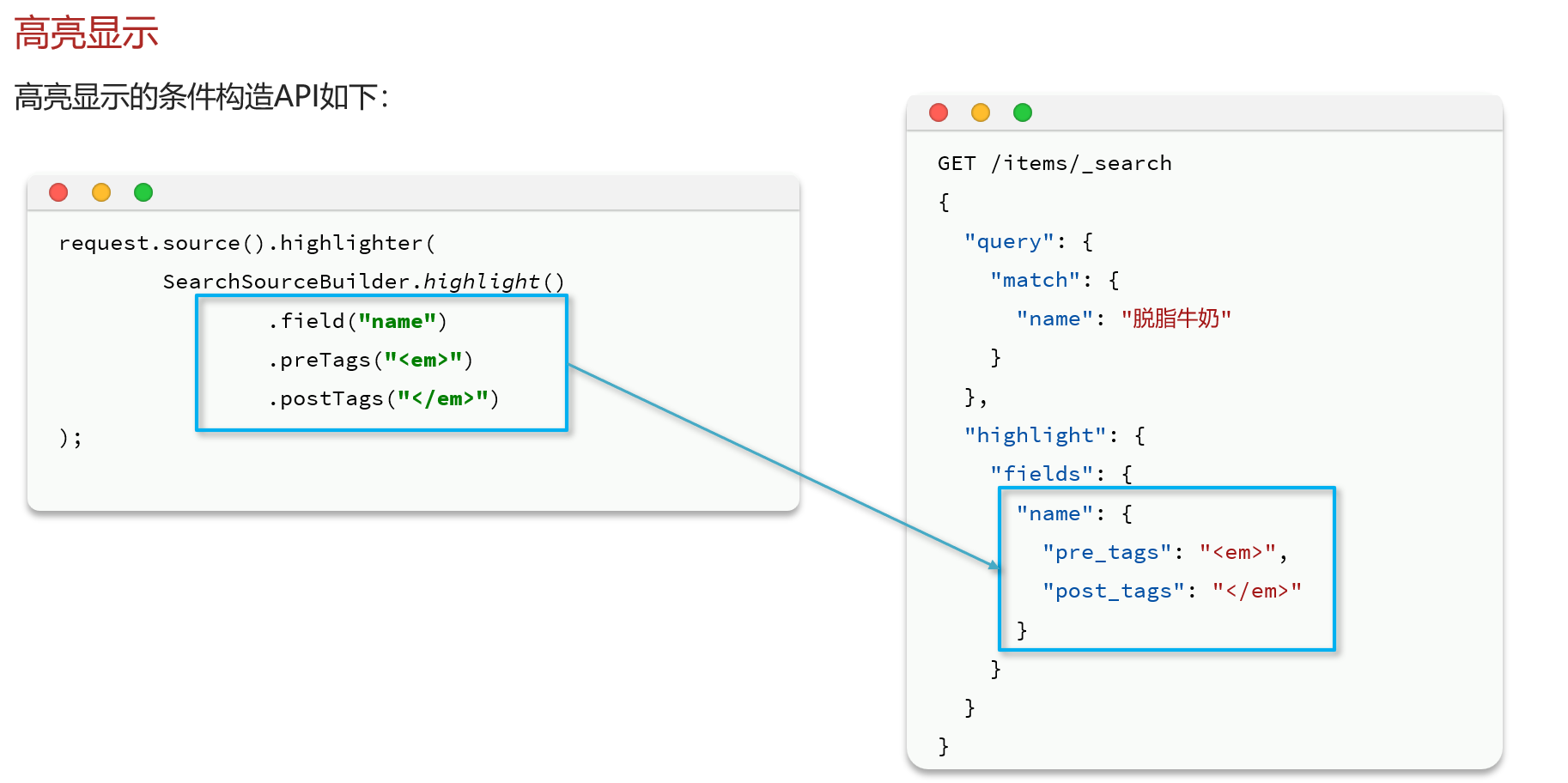
高亮显示:就是在搜索结果中把搜索关键字突出显示。
语法格式
GET /items/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 高亮的前置标签
"post_tags": "</em>" // 高亮的后置标签
}
}
}
}案例展示(给脱脂牛奶加标签)
JavaRestClient(Java客户端查询)
快速入门
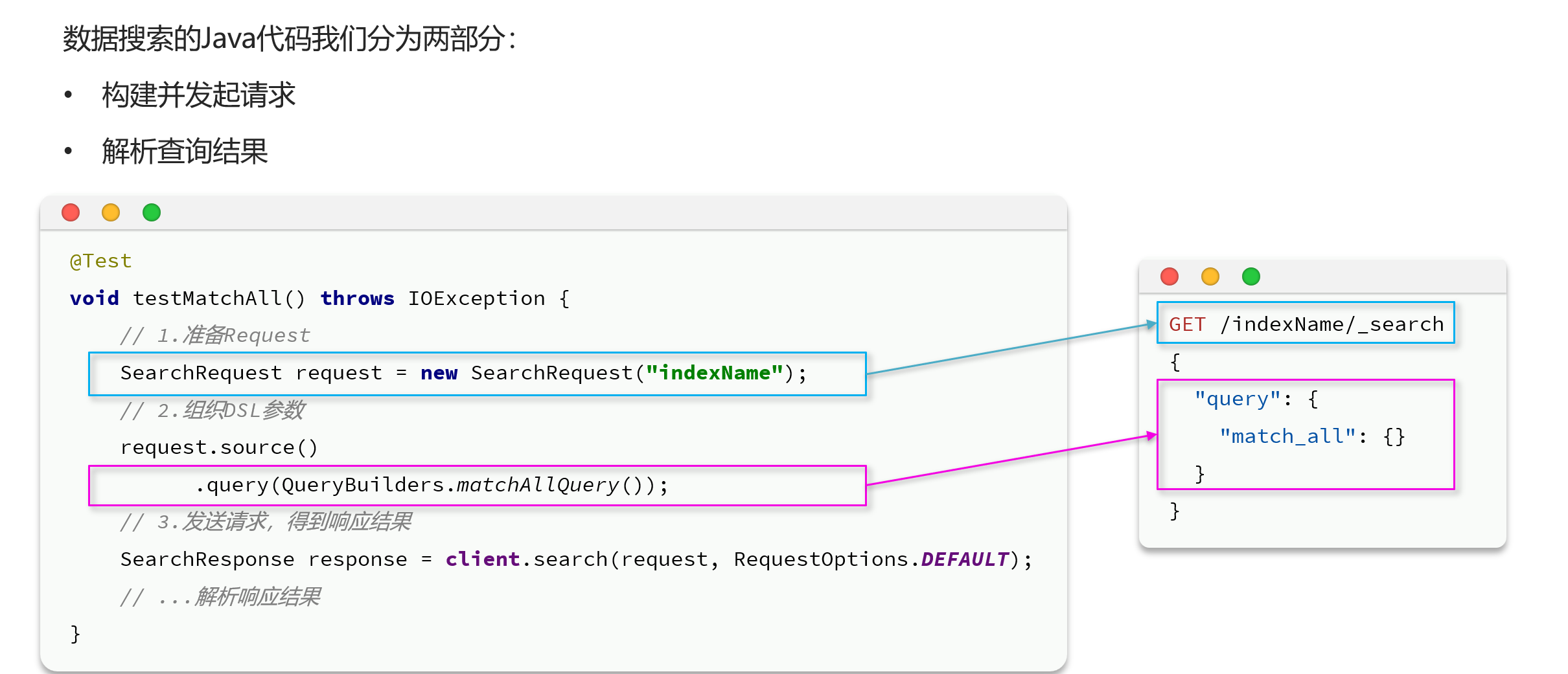
实际案例:查询全部的信息(实际默认返回十条)
查询:主要语句searchRequest.source() .query(QueryBuilders.XXXX);
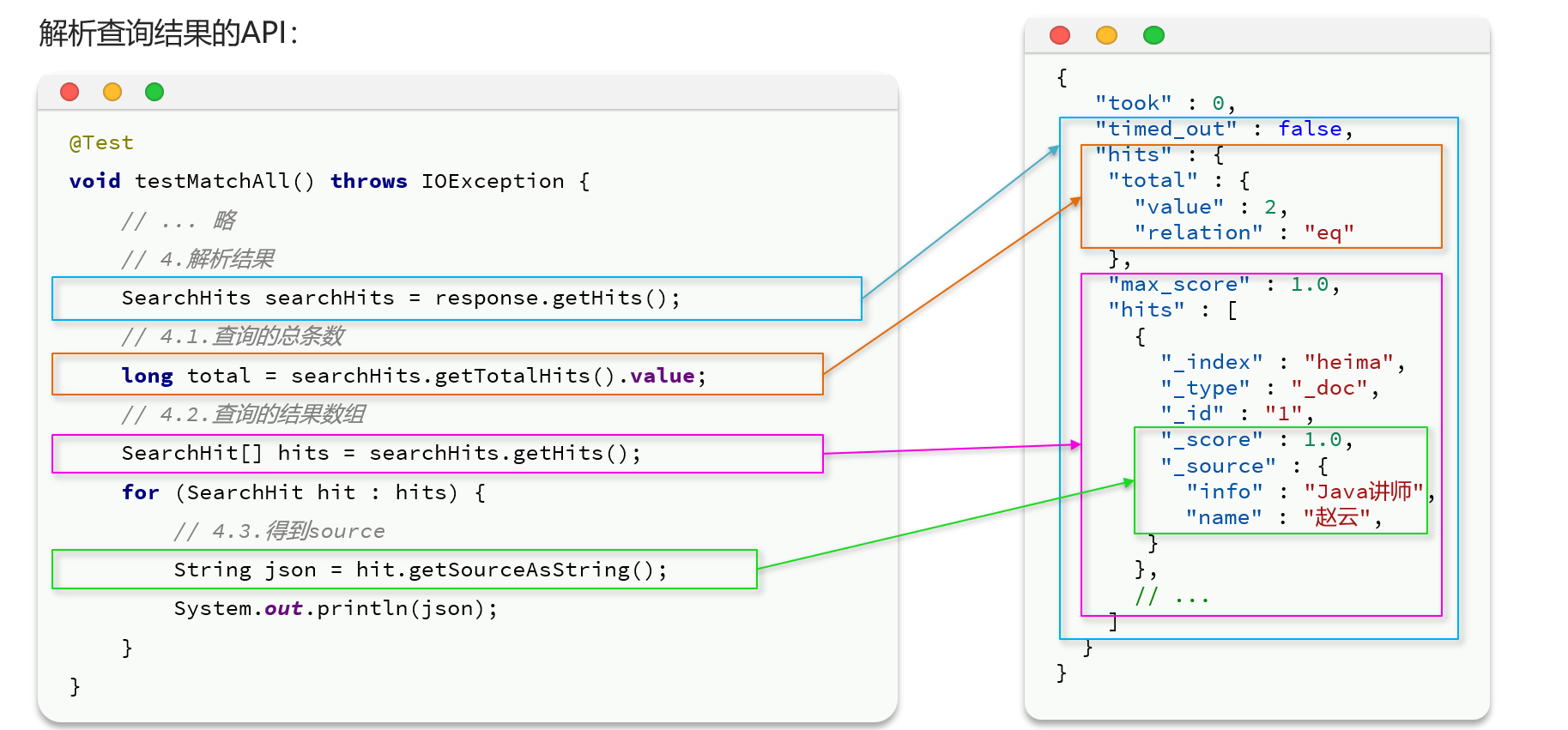
解析:主要语句1.SearchHits hits = response.getHits();
2.SearchHit[] searchHits = hits.getHits();
//处理结果部分代码
private static void parseRwsponseResult(SearchResponse response) {
//4.处理结果
SearchHits hits = response.getHits();
//查询条数
long total = hits.getTotalHits().value;
System.out.println("查询条数:" + total);
//查询结果数组
SearchHit[] searchHits = hits.getHits();
//遍历
for (SearchHit hit : searchHits) {
//我们要得到的是json字符串,所以用getSourceAsString
String sourceAsString = hit.getSourceAsString();
ItemDoc itemDoc = JSONUtil.toBean(sourceAsString, ItemDoc.class);
System.out.println(itemDoc);
}
}
@Test
void searchAll() throws IOException {
//1.创建request对象
SearchRequest searchRequest = new SearchRequest("items");
//2.配置request参数
searchRequest.source()
.query(QueryBuilders.matchAllQuery());
//3.发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
parseRwsponseResult(response);//处理结果代码
}构建查询条件
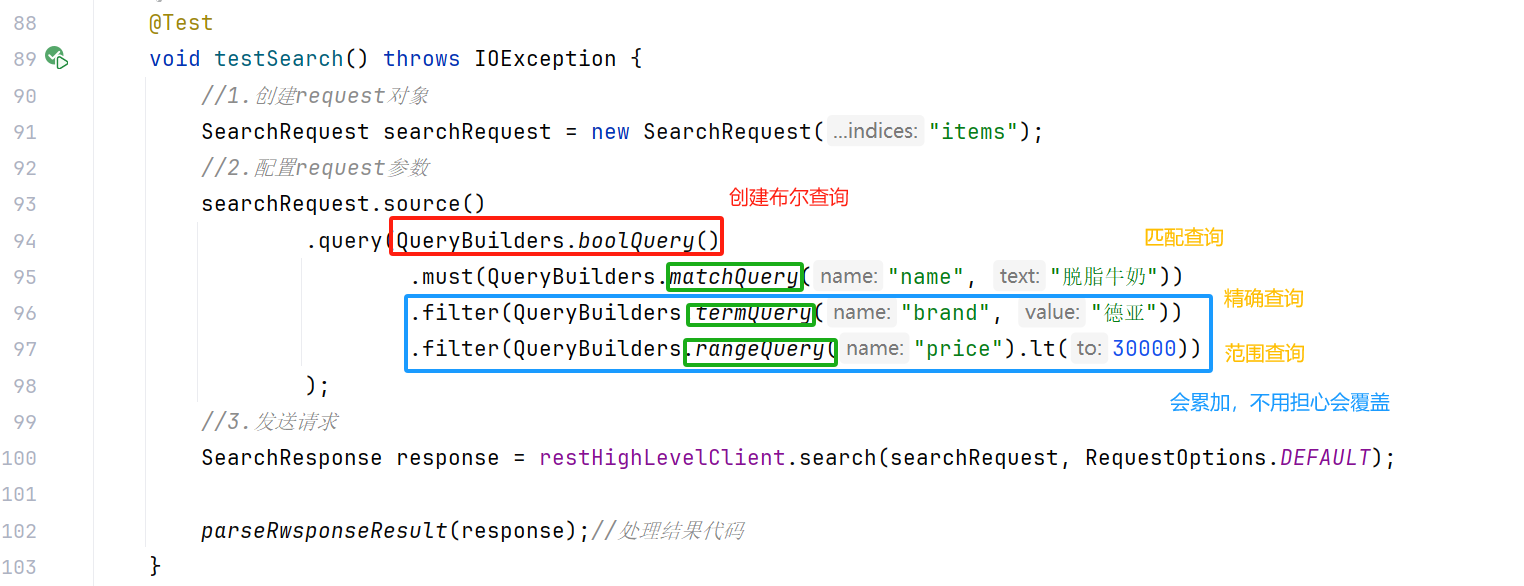
案例:利用JavaRestClient实现搜索功能,条件如下:
代码如下:
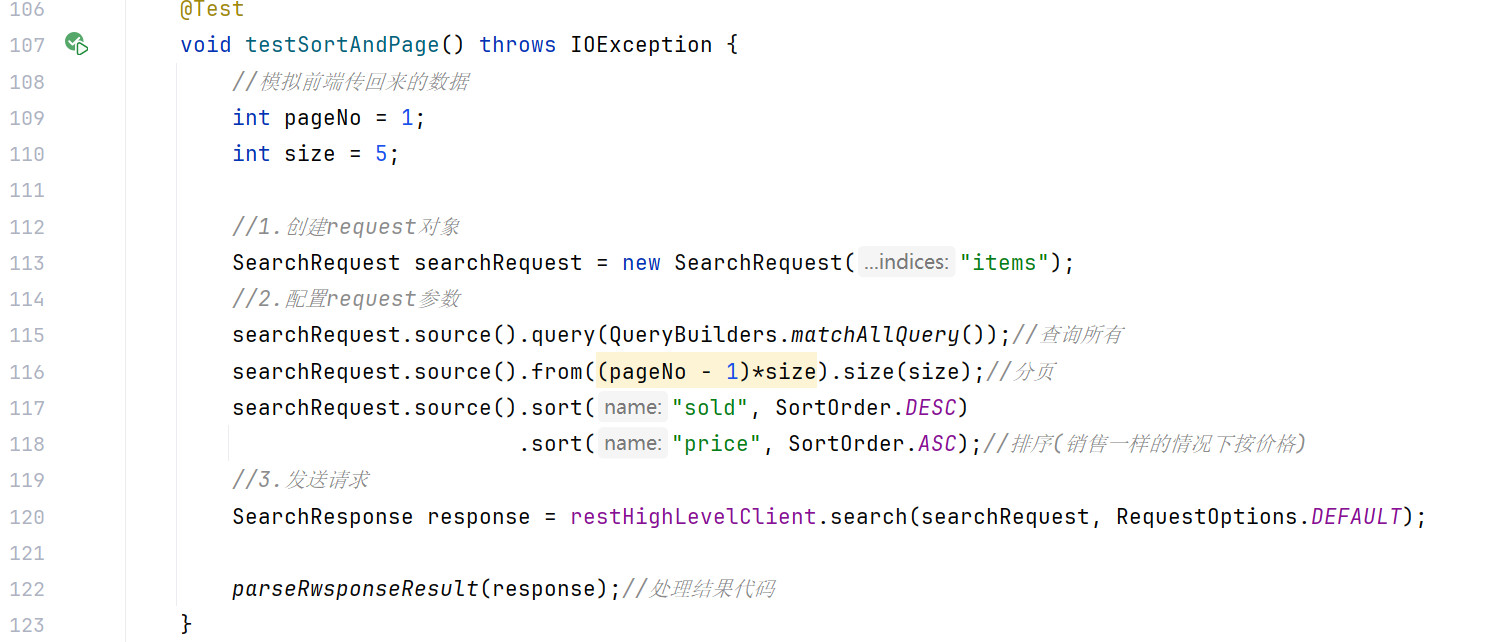
排序和分页

实际操作(分页和排序)
高亮显示
特殊之处:要先调用highlighter才能调用highlight
实际操作(关于preTag和postTag:默认不写这俩字段默认高亮是加上<em> </em>标签)
发送请求:
@Test
void testHighlight() throws IOException {
//1.创建request对象
SearchRequest searchRequest = new SearchRequest("items");
//2.配置request参数
searchRequest.source().query(QueryBuilders.matchQuery("name", "脱脂牛奶"));//查询所有
searchRequest.source().highlighter(SearchSourceBuilder.highlight().field("name"));
//3.发送请求
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
parseRwsponseResult(response);//处理结果代码
}处理请求:
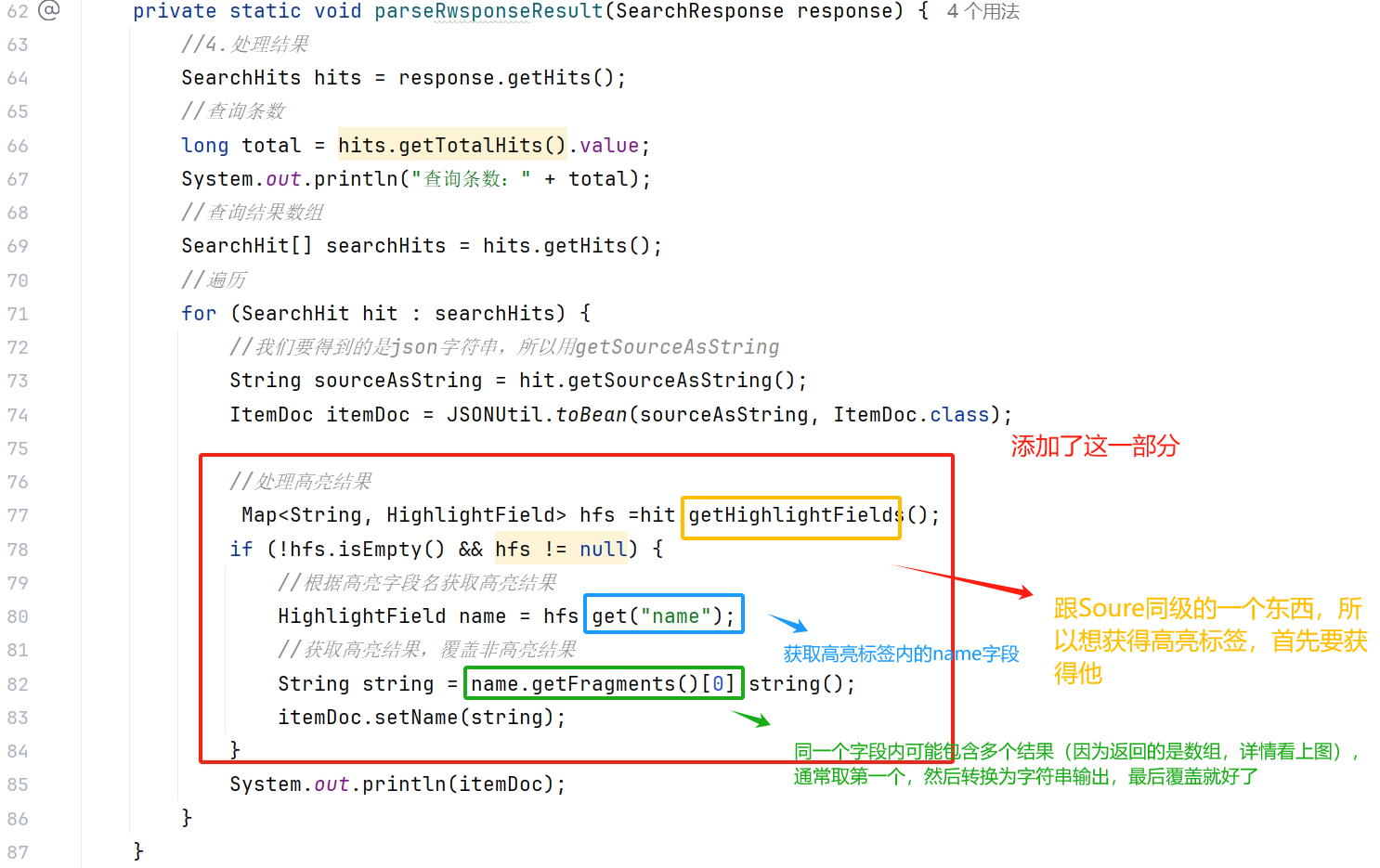
效果

聚合
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
1.桶(Bucket)聚合:用来对文档做分组
• TermAggregation(标签:terms):按照文档字段值分组
• Date Histogram(标签:date_histogram):按照日期阶梯分组,例如一周为一组,或者一月为一组
2.度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
•Avg(标签:avg):求平均值
•Max(标签:max):求最大值
•Min(标签:min):求最小值
•Stats(标签:stats):同时求max、min、avg、sum等
3.管道(pipeline)聚合:其它聚合的结果为基础做聚合
注意:参与聚合的字段必须是Keyword、数值、日期、布尔的类型的字段
DSL聚合
Bucket聚合 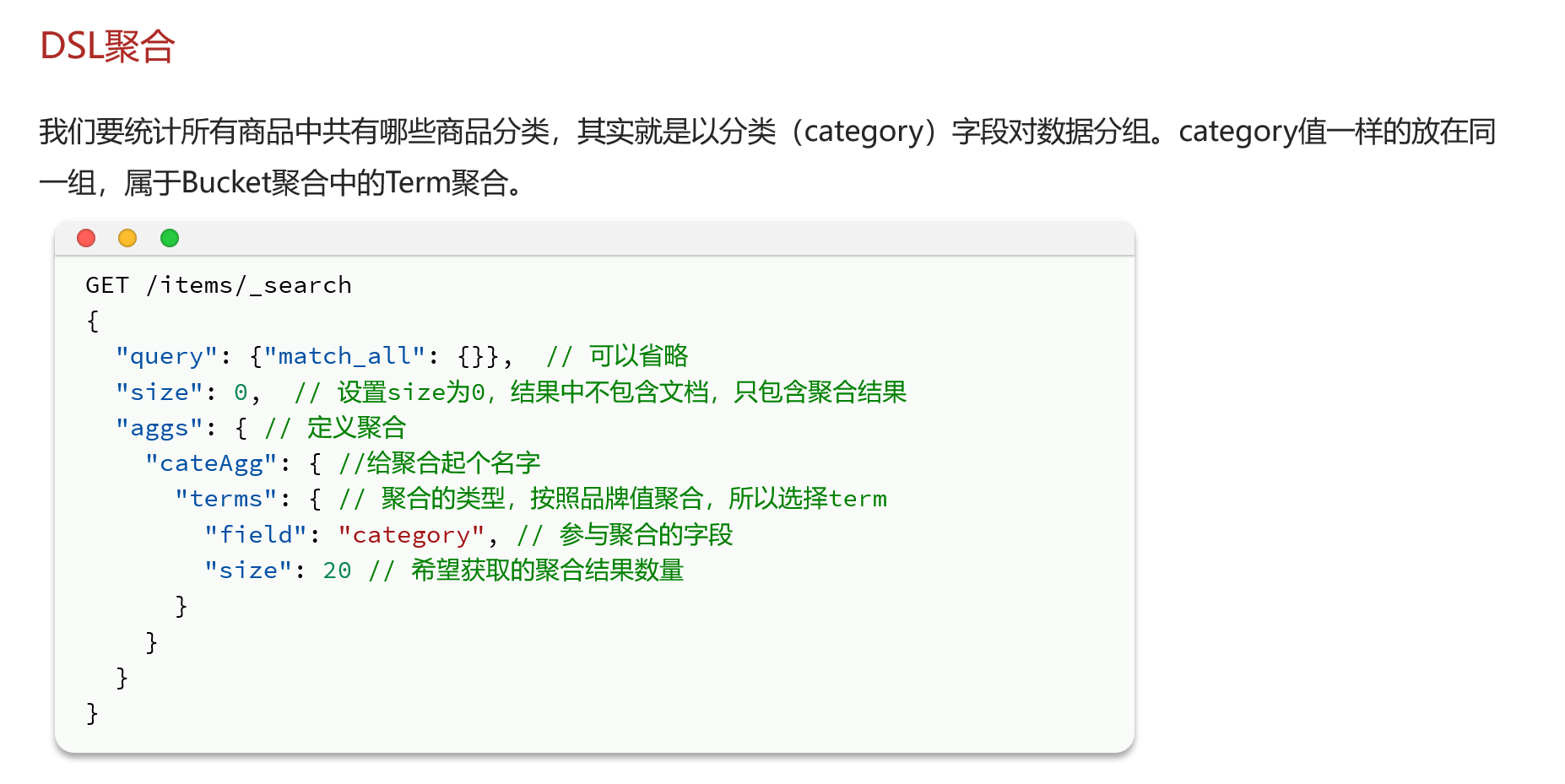
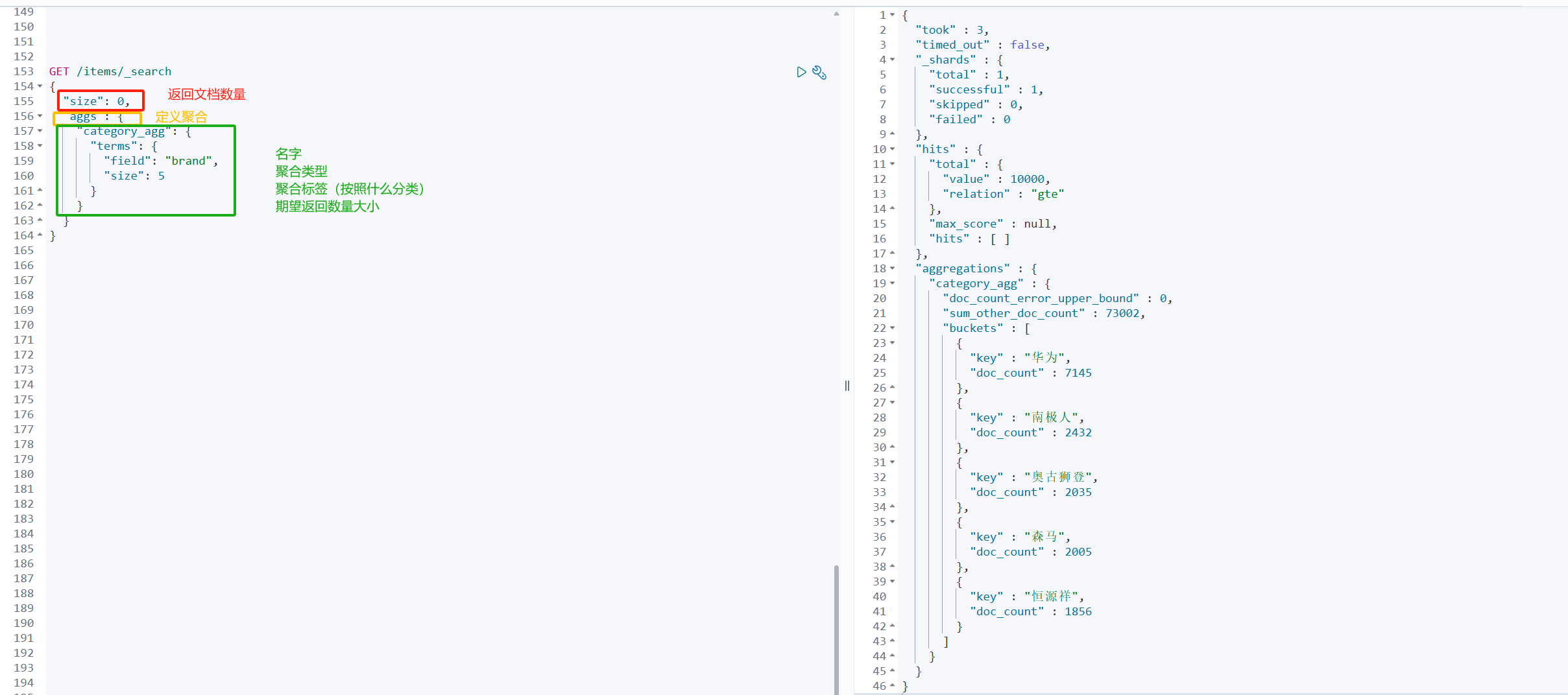
带条件的聚合(1.手机,2.低于3000元)
GET /items/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"category": "手机"
}
},
{
"range": {
"price": {
"gte": 300000
}
}
}
]
}
},
"size": 0,
"aggs": {
"brand_agg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}Metric聚合

例子
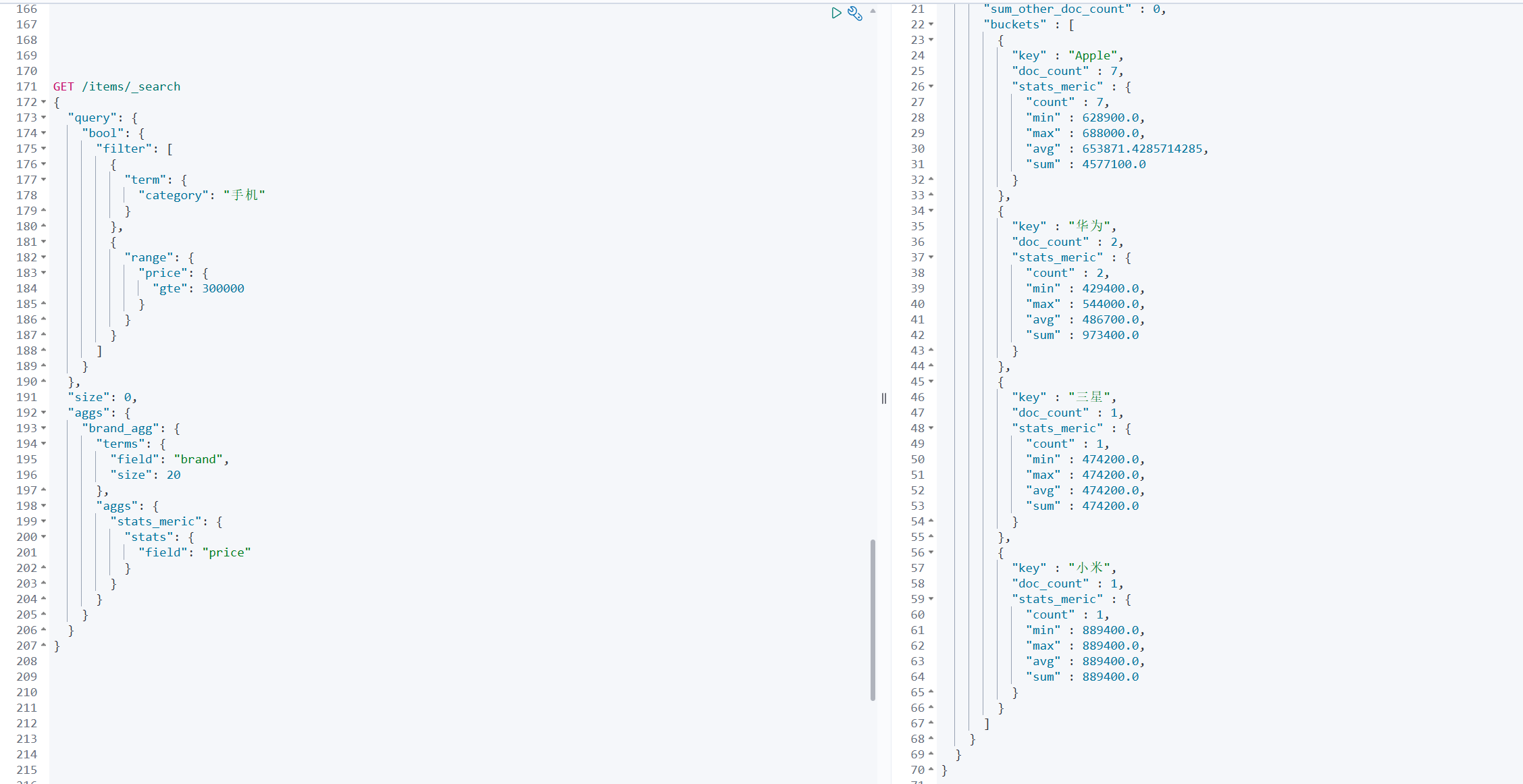
聚合必须的三要素:
聚合可配置属性有:
RestClient聚合
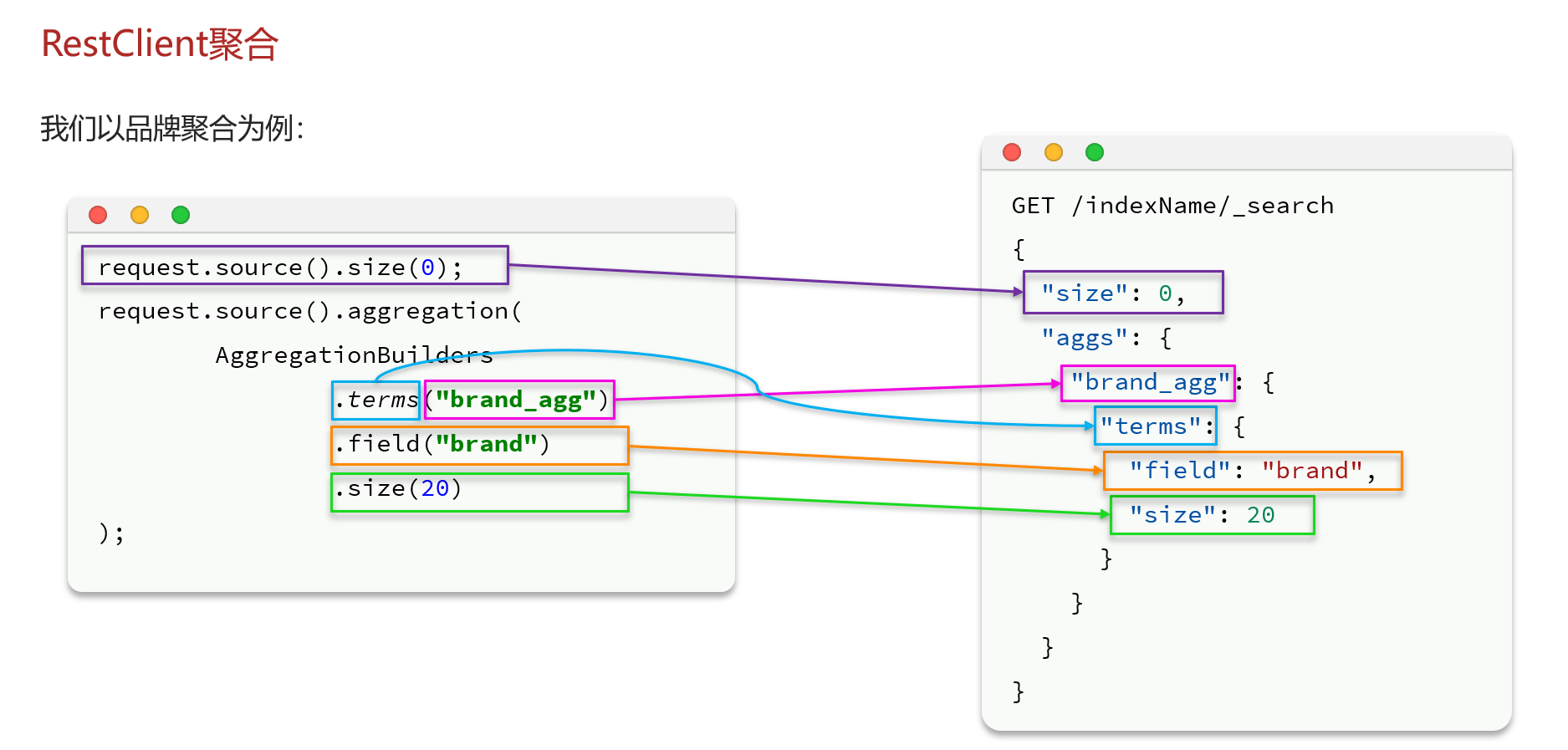
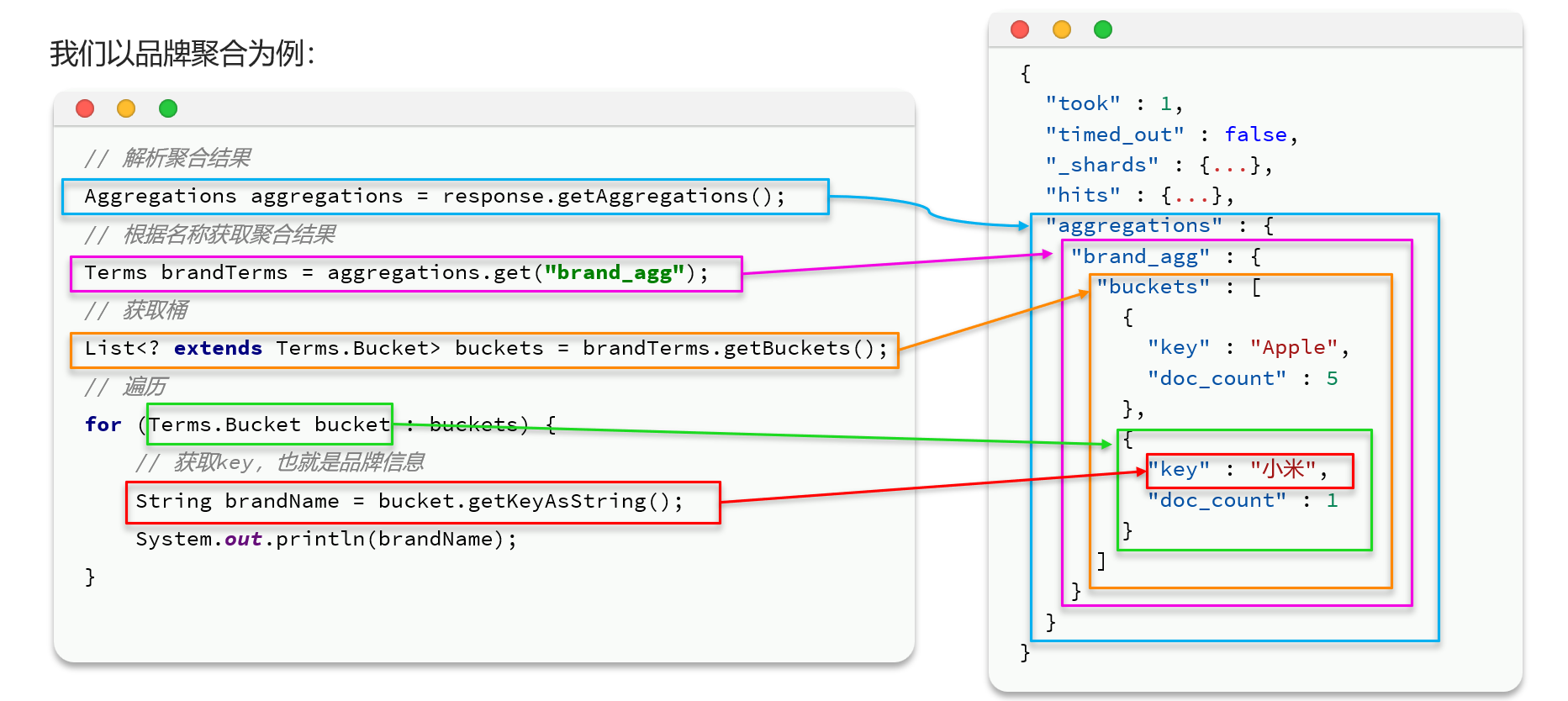
实际案例 (跟着上图抽丝剥茧就好了)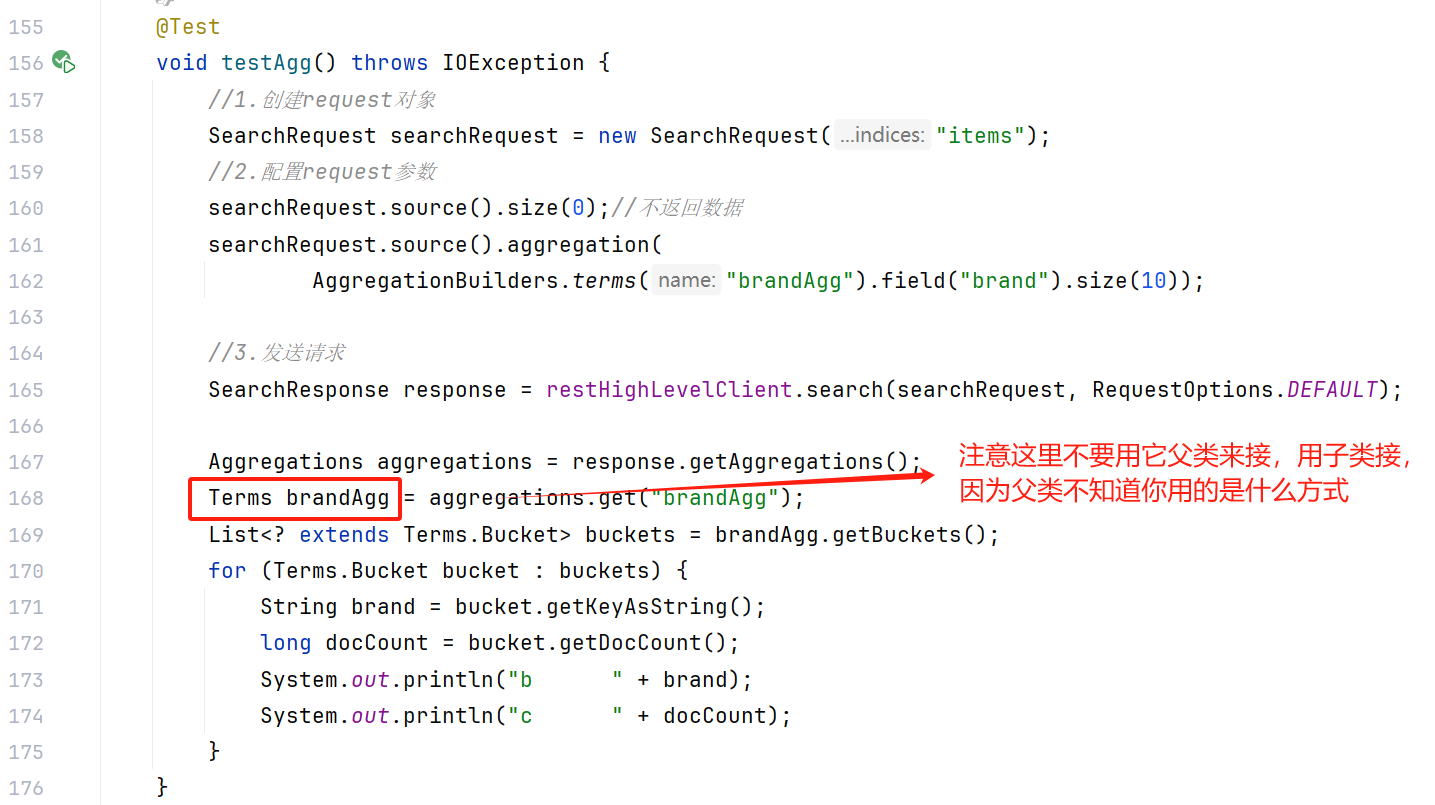
2025.4.18 完结撒花 !


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









