





1.什么是网络爬虫
Python爬虫是使用Python编程语言编写的程序,它能自动从互联网上抓取数据。这类程序一般利用网络请求来访问网站,解析网站的HTML或其他格式的内容,提取出有用的数据,有时还会进行后续的数据处理或存储。
Python爬虫的用途包括:
-
数据收集:对于数据分析师和研究人员来说,爬虫可以帮助从各种网站上自动化收集数据,如社交媒体数据、金融市场数据、商品信息等。
-
监控网站:爬虫可以用来监控网站的变化,比如价格变动、新闻更新、股票市场动态等,对于商业智能和市场分析尤其有用。
-
搜索引擎:搜索引擎如Google和Bing使用爬虫技术来索引互联网上的网页,以便用户可以通过搜索引擎找到这些网页。
-
自动化测试:开发者可以使用爬虫来监测网站功能是否正常,比如检查链接是否有效,确保页面内容显示正确等。
-
内容聚合:爬虫可用于从多个源收集信息,并将其集成在一起,提供内容聚合服务。例如新闻聚合、博客聚合等。
Python在爬虫领域的流行原因:
-
强大的库支持:Python拥有强大的库来支持爬虫的制作,如
requests用于网络请求,BeautifulSoup和lxml用于HTML解析,Scrapy和Selenium用于更复杂的爬虫项目。 -
简单易学:Python语法简单,易于学习和编写,使得编写爬虫变得更加容易。
-
广泛的社区支持:由于Python在数据科学和网络爬虫领域的广泛应用,可以很容易地找到问题的解决方案和优化的建议。
尽管Python爬虫有很多合法的应用,但是在使用爬虫时也必须遵守相关法律法规和网站的robots.txt文件,尊重网站的版权和服务条款,合法合规地使用网络爬虫技术。
2.使用爬虫爬取图书250数据
①一般方式(针对未设置反爬虫程序的网站)
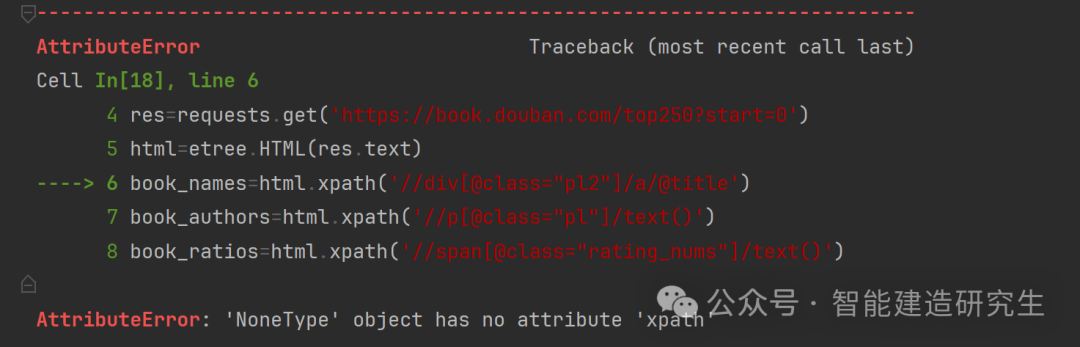
由于目标网站存在反爬虫程序,因此运行下面这段代码会显示错误。
代码示例:
import requests # 发起网络请求
from lxml import etree # 解析HTML文档
res=requests.get('https://book.douban.com/top250?start=0')
html=etree.HTML(res.text)
book_names=html.xpath('//div[@class="pl2"]/a/@title')
book_authors=html.xpath('//p[@class="pl"]/text()')
book_ratios=html.xpath('//span[@class="rating_nums"]/text()')
book_quotes=html.xpath('//span[@class="inq"]/text()')
# print(book_authors)
# print(book_ratios)
# print(len(book_ratios))
# print(book_quotes)
for i in zip(book_names,book_quotes,book_ratios):
a,b,c=i
# print(a,b,c)
authors=[]
for i in book_authors:
#print(i.split('/')[0])
authors.append(i.split('/')[0])
# print(authors)
for i in zip(book_names,authors,book_quotes,book_ratios):
a,b,c,d=i
# print(i)
print(a,b,c,d)
由于存在反爬虫程序,因此上面的程序无法获取到网页上的数据。html 对象是 None,这通常是因为 etree.HTML(res.text) 无法解析 res.text 中的内容作为HTML,或者请求得到的内容为空导致。
运行结果:
②对于存在反爬虫的网站
需要添加一些代码防止被网站判定为爬虫程序,但最终的输出数据只有24条,并没有250条
import requests # 发起网络请求
from lxml import etree # 解析HTML文档
import time # 用于控制时间(如等待),以避免请求过于频繁
# 创建会话以维持cookie
session = requests.Session() # 创建一个会话对象,这可以使得在多次请求中保持某些参数,如Cookies
# 设置User-Agent为一个常见浏览器的标识,这有助于防止被网站以为是爬虫而拒绝服务
session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
})
# 使用会话对象请求网页,设置超时为10秒
url = 'https://book.douban.com/top250?start=0'
try:
res = session.get(url, timeout=10)
res.raise_for_status() # 如果响应状态码不是 200,将抛出 HTTPError 异常
html = etree.HTML(res.text) # 使用lxml的HTML函数解析获取到的网页源码
if html is not None:
# book_names:提取书名
# book_authors:提取包含作者和出版信息的文本
# book_ratios:提取书籍评分
# book_quotes:提取书籍的引语
book_names=html.xpath('//div[@class="pl2"]/a/@title')
book_authors=html.xpath('//p[@class="pl"]/text()')
book_ratios=html.xpath('//span[@class="rating_nums"]/text()')
book_quotes=html.xpath('//span[@class="inq"]/text()')
# print(book_authors)
# print(book_ratios)
# print(len(book_ratios))
# print(book_quotes)
for i in zip(book_names,book_quotes,book_ratios): # 使用zip函数将提取的书名、引语和评分组合在一起,并在循环中处理每一项
a,b,c=i
# print(a,b,c)
authors=[]
for i in book_authors:
#print(i.split('/')[0])
authors.append(i.split('/')[0])
# print(authors)
for i in zip(book_names,authors,book_quotes,book_ratios):
a,b,c,d=i
# print(i)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









