 解决SparkThriftServer找不到Hive表问题
解决SparkThriftServer找不到Hive表问题




当我们希望创建的表中查找我们的数据,但是往往在运行的时候却遇到我们所需要查询的表没有被创建的问题。如下述报错
pyhive.exc.OperationalError: TExecuteStatementResp(status=TStatus(statusCode=3, infoMessages=["*org.apache.hive.service.cli.HiveSQLException:Error running query: org.apache.spark.sql.AnalysisException: Table or view not found: noveldata; line 1 pos 14;\n'Project [*]\n+- 'UnresolvedRelation [noveldata], [], false\n:36:35", 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:org$apache$spark$sql$hive$thriftserver$SparkExecuteStatementOperation$$execute:SparkExecuteStatementOperation.scala:361', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:runInternal:SparkExecuteStatementOperation.scala:249', 'org.apache.hive.service.cli.operation.Operation:run:Operation.java:278', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:org$apache$spark$sql$hive$thriftserver$SparkOperation$$super$run:SparkExecuteStatementOperation.scala:43', 'org.apache.spark.sql.hive.thriftserver.SparkOperation:$anonfun$run$1:SparkOperation.scala:44', 'scala.runtime.java8.JFunction0$mcV$sp:apply:JFunction0$mcV$sp.java:23', 'org.apache.spark.sql.hive.thriftserver.SparkOperation:withLocalProperties:SparkOperation.scala:78', 'org.apache.spark.sql.hive.thriftserver.SparkOperation:withLocalProperties$:SparkOperation.scala:62', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:withLocalProperties:SparkExecuteStatementOperation.scala:43', 'org.apache.spark.sql.hive.thriftserver.SparkOperation:run:SparkOperation.scala:44', 'org.apache.spark.sql.hive.thriftserver.SparkOperation:run$:SparkOperation.scala:42', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:run:SparkExecuteStatementOperation.scala:43', 'org.apache.hive.service.cli.session.HiveSessionImpl:executeStatementInternal:HiveSessionImpl.java:484', 'org.apache.hive.service.cli.session.HiveSessionImpl:executeStatement:HiveSessionImpl.java:460', 'sun.reflect.GeneratedMethodAccessor82:invoke::-1', 'sun.reflect.DelegatingMethodAccessorImpl:invoke:DelegatingMethodAccessorImpl.java:43', 'java.lang.reflect.Method:invoke:Method.java:498', 'org.apache.hive.service.cli.session.HiveSessionProxy:invoke:HiveSessionProxy.java:78', 'org.apache.hive.service.cli.session.HiveSessionProxy:access$000:HiveSessionProxy.java:36', 'org.apache.hive.service.cli.session.HiveSessionProxy$1:run:HiveSessionProxy.java:63', 'java.security.AccessController:doPrivileged:AccessController.java:-2', 'javax.security.auth.Subject:doAs:Subject.java:422', 'org.apache.hadoop.security.UserGroupInformation:doAs:UserGroupInformation.java:1730', 'org.apache.hive.service.cli.session.HiveSessionProxy:invoke:HiveSessionProxy.java:59', 'com.sun.proxy.$Proxy36:executeStatement::-1', 'org.apache.hive.service.cli.CLIService:executeStatement:CLIService.java:281', 'org.apache.hive.service.cli.thrift.ThriftCLIService:ExecuteStatement:ThriftCLIService.java:457', 'org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement:getResult:TCLIService.java:1557', 'org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement:getResult:TCLIService.java:1542', 'org.apache.thrift.ProcessFunction:process:ProcessFunction.java:38', 'org.apache.thrift.TBaseProcessor:process:TBaseProcessor.java:39', 'org.apache.hive.service.auth.TSetIpAddressProcessor:process:TSetIpAddressProcessor.java:53', 'org.apache.thrift.server.TThreadPoolServer$WorkerProcess:run:TThreadPoolServer.java:310', 'java.util.concurrent.ThreadPoolExecutor:runWorker:ThreadPoolExecutor.java:1149', 'java.util.concurrent.ThreadPoolExecutor$Worker:run:ThreadPoolExecutor.java:624', 'java.lang.Thread:run:Thread.java:748', "*org.apache.spark.sql.AnalysisException:Table or view not found: noveldata; line 1 pos 14;\n'Project [*]\n+- 'UnresolvedRelation [noveldata], [], false\n:65:29", 'org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt:failAnalysis:package.scala:42', 'org.apache.spark.sql.catalyst.analysis.CheckAnalysis:$anonfun$checkAnalysis$1:CheckAnalysis.scala:113', 'org.apache.spark.sql.catalyst.analysis.CheckAnalysis:$anonfun$checkAnalysis$1$adapted:CheckAnalysis.scala:93', 'org.apache.spark.sql.catalyst.trees.TreeNode:foreachUp:TreeNode.scala:183', 'org.apache.spark.sql.catalyst.trees.TreeNode:$anonfun$foreachUp$1:TreeNode.scala:182', 'org.apache.spark.sql.catalyst.trees.TreeNode:$anonfun$foreachUp$1$adapted:TreeNode.scala:182', 'scala.collection.immutable.List:foreach:List.scala:392', 'org.apache.spark.sql.catalyst.trees.TreeNode:foreachUp:TreeNode.scala:182', 'org.apache.spark.sql.catalyst.analysis.CheckAnalysis:checkAnalysis:CheckAnalysis.scala:93', 'org.apache.spark.sql.catalyst.analysis.CheckAnalysis:checkAnalysis$:CheckAnalysis.scala:90', 'org.apache.spark.sql.catalyst.analysis.Analyzer:checkAnalysis:Analyzer.scala:155', 'org.apache.spark.sql.catalyst.analysis.Analyzer:$anonfun$executeAndCheck$1:Analyzer.scala:176', 'org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$:markInAnalyzer:AnalysisHelper.scala:228', 'org.apache.spark.sql.catalyst.analysis.Analyzer:executeAndCheck:Analyzer.scala:173', 'org.apache.spark.sql.execution.QueryExecution:$anonfun$analyzed$1:QueryExecution.scala:73', 'org.apache.spark.sql.catalyst.QueryPlanningTracker:measurePhase:QueryPlanningTracker.scala:111', 'org.apache.spark.sql.execution.QueryExecution:$anonfun$executePhase$1:QueryExecution.scala:143', 'org.apache.spark.sql.SparkSession:withActive:SparkSession.scala:772', 'org.apache.spark.sql.execution.QueryExecution:executePhase:QueryExecution.scala:143', 'org.apache.spark.sql.execution.QueryExecution:analyzed$lzycompute:QueryExecution.scala:73', 'org.apache.spark.sql.execution.QueryExecution:analyzed:QueryExecution.scala:71', 'org.apache.spark.sql.execution.QueryExecution:assertAnalyzed:QueryExecution.scala:63', 'org.apache.spark.sql.Dataset$:$anonfun$ofRows$2:Dataset.scala:98', 'org.apache.spark.sql.SparkSession:withActive:SparkSession.scala:772', 'org.apache.spark.sql.Dataset$:ofRows:Dataset.scala:96', 'org.apache.spark.sql.SparkSession:$anonfun$sql$1:SparkSession.scala:615', 'org.apache.spark.sql.SparkSession:withActive:SparkSession.scala:772', 'org.apache.spark.sql.SparkSession:sql:SparkSession.scala:610', 'org.apache.spark.sql.SQLContext:sql:SQLContext.scala:650', 'org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation:org$apache$spark$sql$hive$thriftserver$SparkExecuteStatementOperation$$execute:SparkExecuteStatementOperation.scala:325'], sqlState=None, errorCode=0, errorMessage="Error running query: org.apache.spark.sql.AnalysisException: Table or view not found: noveldata; line 1 pos 14;\n'Project [*]\n+- 'UnresolvedRelation [noveldata], [], false\n"), operationHandle=None)
当我们继续在hive中查找,验证我们所需要的表是否被创建,
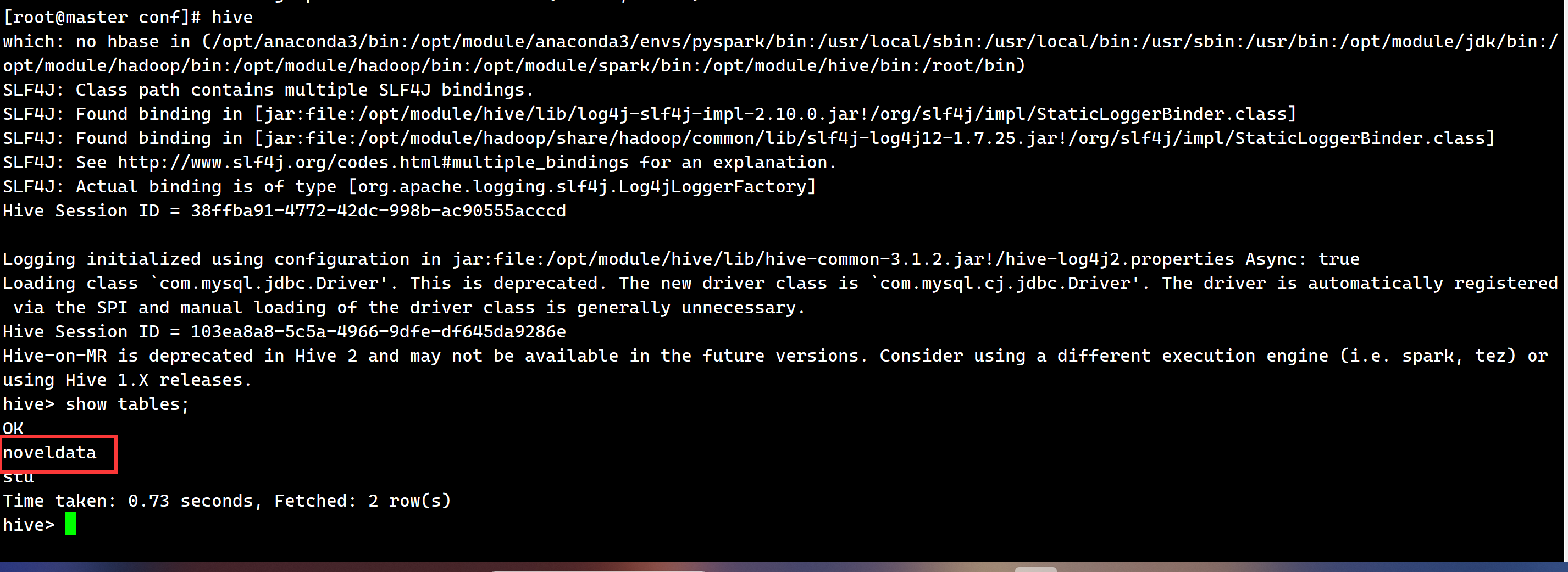
当我启动hive时发现我所需要的hive表是存在的,并且也没有其他问题,再慢慢思考,
结果就发现hive CLI 能查到,是因为 Hive CLI 走的是 Hive 原生的 metastore 客户端;
PyHive 走的是 HiveServer2 的 Spark SQL 引擎(SparkThriftServer),两者元数据可以不一致。
所以就需要查看一下Spark SQL引擎上是否有noveldata的表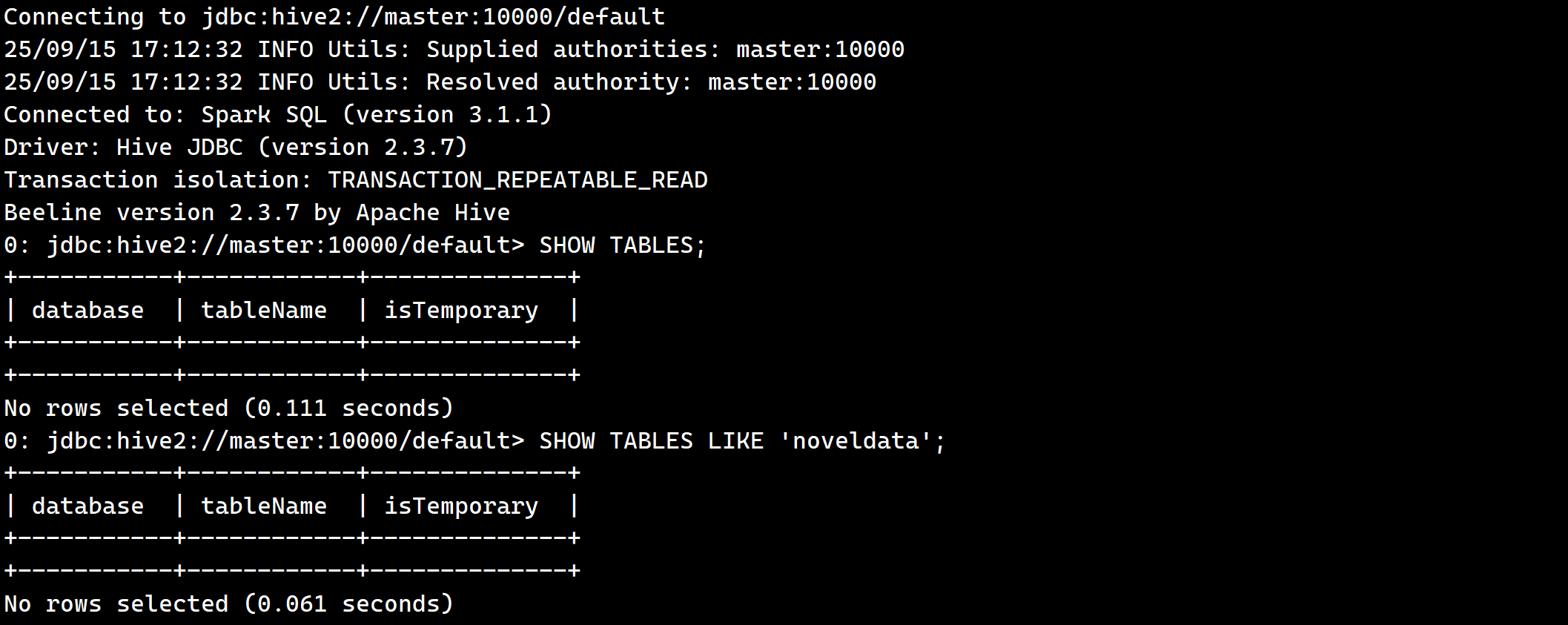
查询到并没有这时候就需要我们解决一下Spark SQL引擎上没有我们预期的表。
找到问题原因我们就可以解决问题了------让SparkThriftServer和 Hive 共用同一份 MySQL metastore
1.找到hive的core-site.xml中的配置文件,将$HIVE_HOME/conf/core-site.xml中的内容复制到$SPARK_HOME/conf/core-site.xml
cp $HIVE_HOME/conf/core-site.xml $SPARK_HOME/conf/core-site.xml
配置文件复制完成之后
2.需要将我们的mysql JDBC的驱动放在我们spark的jar包驱动下
cp /opt/software/mysql-connector-java-8.0.16.jar /opt/module/spark/jars/
3.之后我们需要重新启动spark引擎(SparkThriftServer)
$SPARK_HOME/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000 \
--hiveconf hive.server2.thrift.bind.host=master

4.最后我们验证一下是否成功
通过 JDBC 连接到 SparkThriftServer(端口 10000),走的路径跟 PyHive 完全一样
beeline -u jdbc:hive2://master:10000/default -n root
0: jdbc:hive2://master:10000/default> SHOW TABLES;
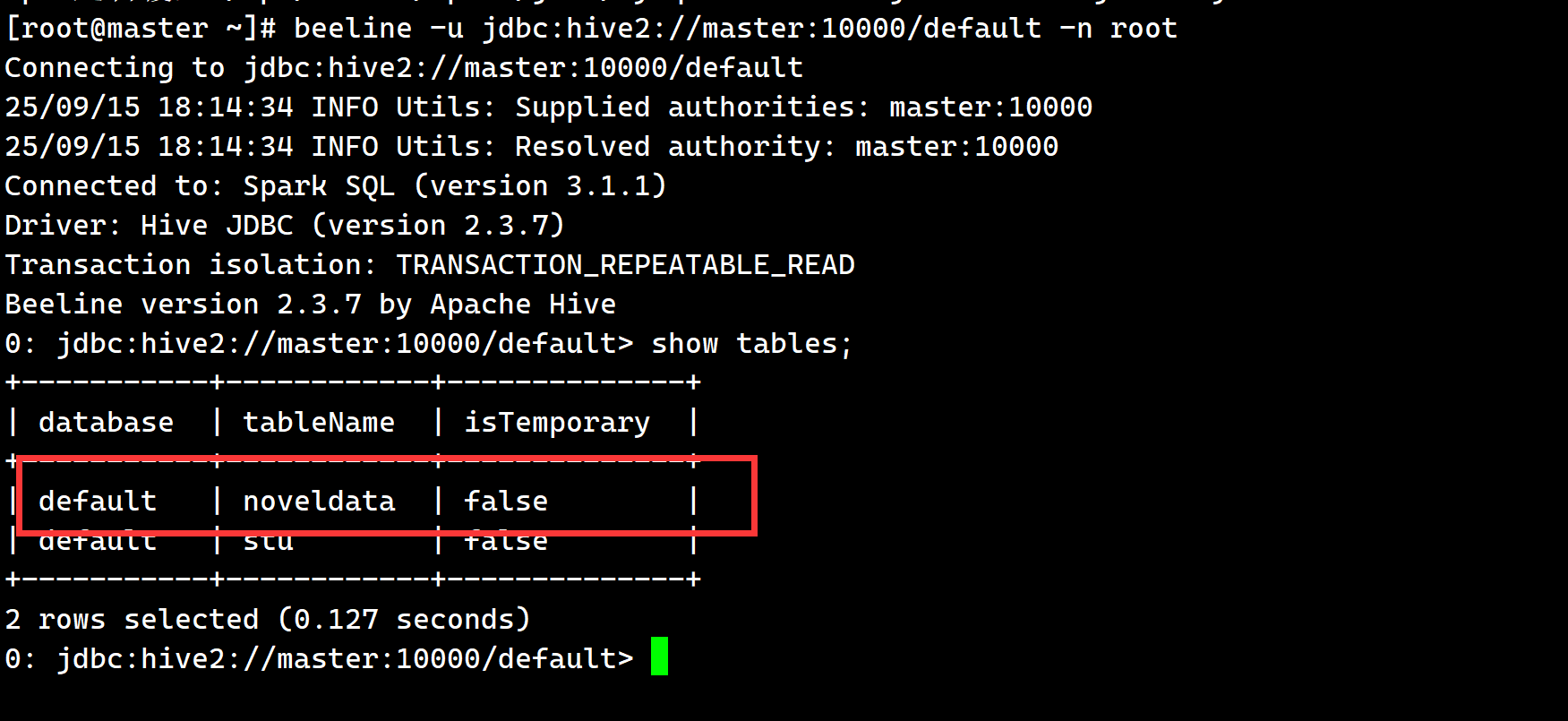
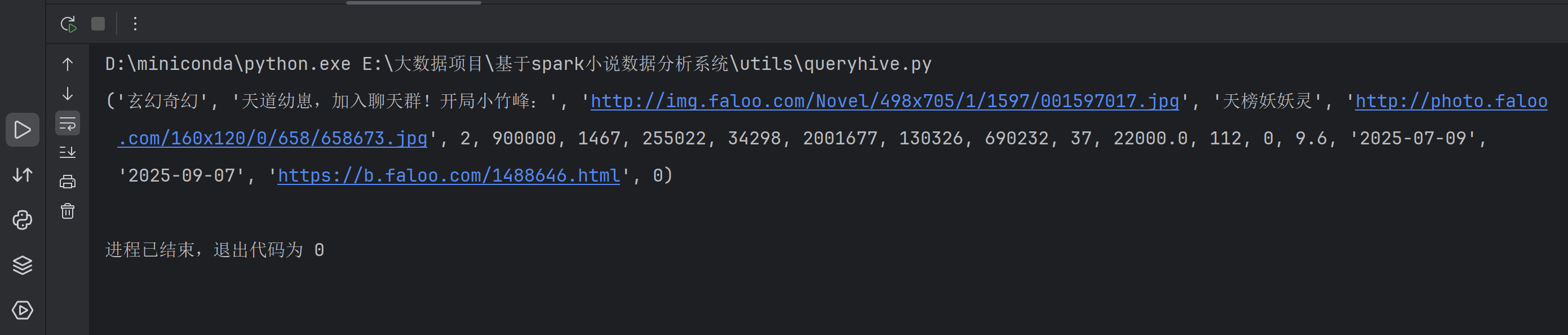
可以看到已经能在SparkThriftServer中查到表了,最终返回我们的pycharm再次运行,可以看到我已经能够成功查询到了数据

















 3019
3019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









