 Kubernetes监控:配置Prometheus获取kubelet和cadvisor数据
Kubernetes监控:配置Prometheus获取kubelet和cadvisor数据





 本文详细介绍了如何在k8s集群内或外部署Prometheus以从kubelet获取监控数据,包括不同部署方式下的配置步骤,以及使用Grafana进行资源监控的注意事项。
本文详细介绍了如何在k8s集群内或外部署Prometheus以从kubelet获取监控数据,包括不同部署方式下的配置步骤,以及使用Grafana进行资源监控的注意事项。
一、前言
k8s集群的kubelet服务内部有自带的cadvisor服务用于收集k8s集群的监控数据,所以可以通过调用kubelet的接口就能获取pod的资源监控数据,在新版本的k8s中,kubelet的监控数据获取端口为10250端口,老版本的是10255端口
二、配置prometheus获取监控数据
以下分为两种情况,一种是在k8s集群内部署的prometheus,一种是在k8s集群外部署的prometheus
以下是k8s集群外部署的prometheus配置
编辑Prometheus配置文件
vi /opt/prometheus/prometheus/prometheus.yml
scrape_configs: #在该配置项下写入以下内容
- job_name: k8s-cadvisor
honor_timestamps: true
metrics_path: /metrics/cadvisor
scheme: https
kubernetes_sd_configs: # kubernetes 自动发现
- api_server: https://10.1.60.119:6443 # apiserver 地址
role: node # node 类型的自动发现
bearer_token_file: ./k8s.token
tls_config:
ca_file: ./ca.crt
insecure_skip_verify: true
bearer_token_file: ./k8s.token
tls_config:
ca_file: ./ca.crt
insecure_skip_verify: true
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
metric_relabel_configs:
- source_labels: [instance]
separator: ;
regex: (.+)
target_label: node
replacement: $1
action: replace以上关于token和ca证书的获取可以参考:k8s集群授权prometheus(集群外部署)_Apex Predator的博客-优快云博客
token是创建一个名为k8s.token的文件,把k8s集群获取到的token放进去即可,ca证书就直接拷贝过来
重启prometheus服务
systemctl restart prometheus
查看Prometheus是否获取到kubelet接口数据
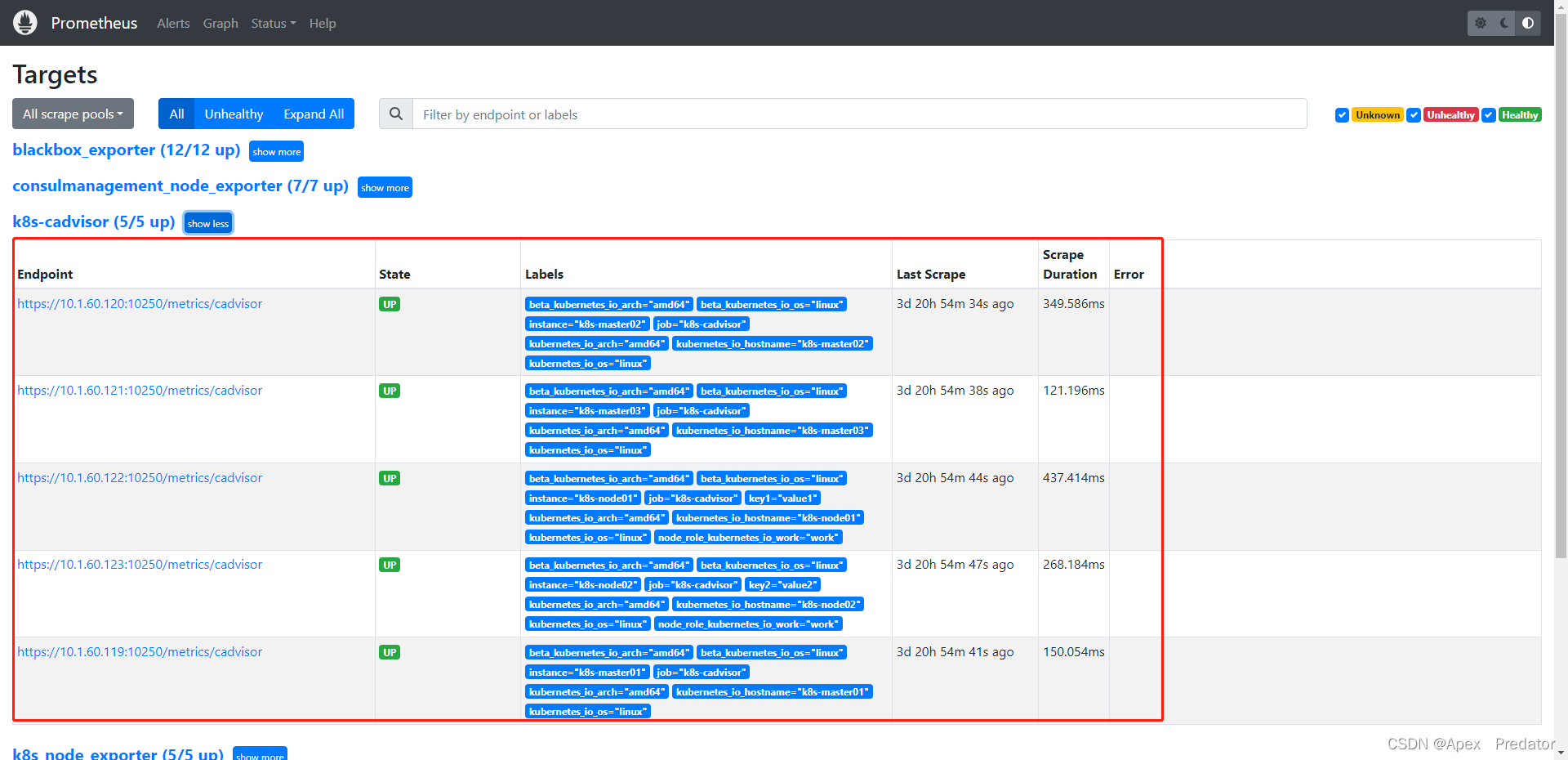
以下是k8s集群内部署的prometheus配置
vi /opt/prometheus/prometheus/prometheus.yml
scrape_configs: #在该配置项下写入以下内容
- job_name: 'k8s-kubelet'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- job_name: 'k8s-cadvisor' #配置cadvisor数据监控接口
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #配置证书,该路径为prometheus pod内部的路径
insecure_skip_verify: true #必须加入此项配置,不然访问接口会报错
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token #配置token,该路径为prometheus pod内部的路径
kubernetes_sd_configs:
- role: node
relabel_configs:
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
metric_relabel_configs:
- source_labels: [instance]
separator: ;
regex: (.+)
target_label: node
replacement: $1
action: replace
- job_name: kube-state-metrics #配置kube-state-metrics数据监控接口
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- ops-monit
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_name]
regex: kube-state-metrics
replacement: $1
action: keep重启prometheus服务
systemctl restart prometheus
以上就是两种不同的Prometheus部署方式去获取kubelet监控数据的配置方法
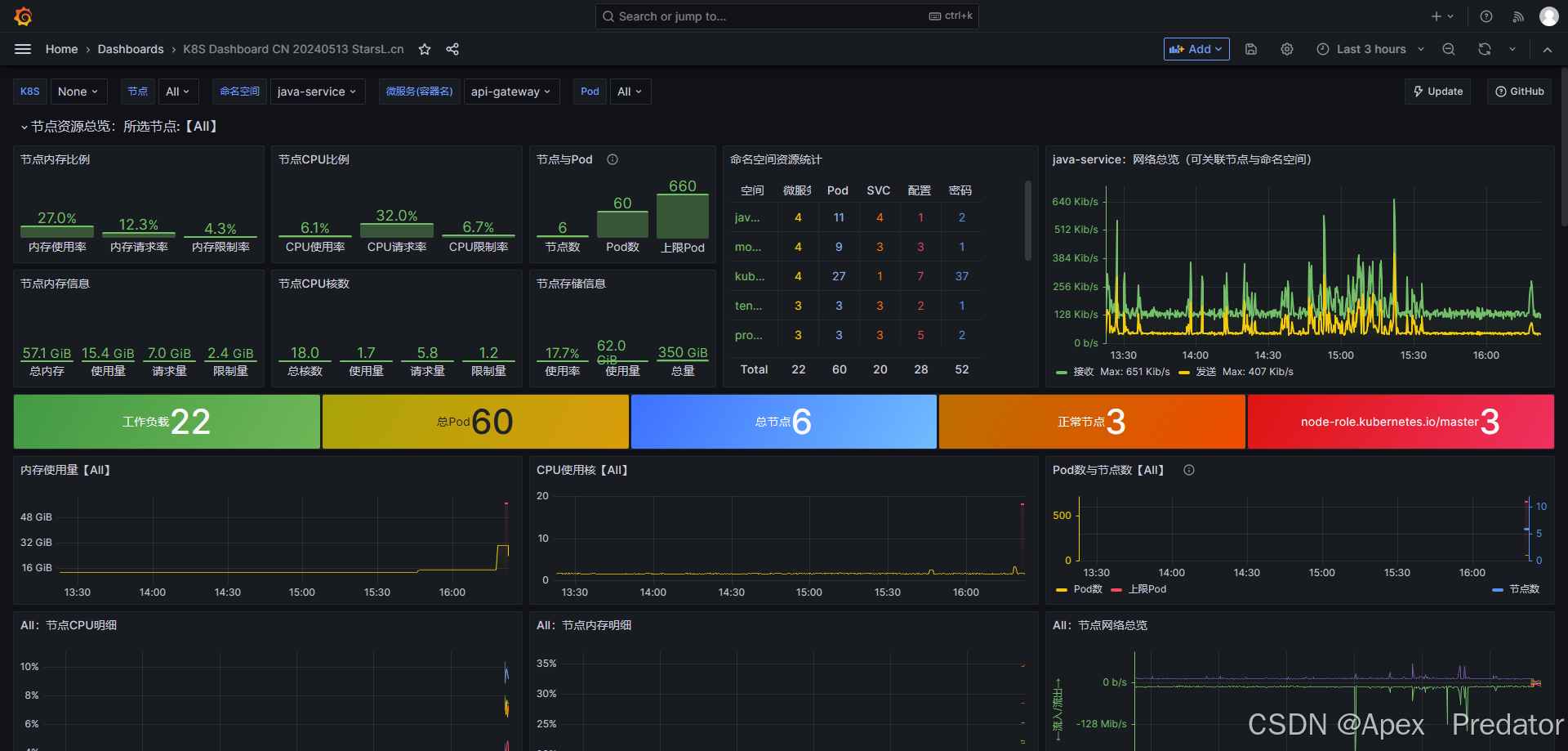
关于granfana使用的资源监控模板则是使用:
K8S Dashboard CN 20240513 StarsL.cn | Grafana Labs
需要配合kube-state-metrics监控一起使用,但是使用该模板在1.24本版以上的k8s中都会出现数据缺失


















 2117
2117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









