




1.案例
当kafka集群的broker节点宕机重启后,此broker节点的partition分区的leader节点会被选举为其它broker节点,此broker节点恢复后就会导致配分不均衡


可以看到所有partition的leader节点都在broker id为1的节点上,原来是平均分配到3个broker节点上,replicas项的首位就是表示原来的leader节点在哪个broker节点上
2.解决方法
观察isr列表是否三个broker节点都在,以保证三个broker节点数据一致性
bin/kafka-topics.sh --describe --bootstrap-server 10.1.60.114:9092 --topic apex

在任意kafka集群的broker节点执行以下命令,若有多个分区要重新选举则更改--partition项执行
/etc/kafka/kafka/bin/kafka-leader-election.sh --bootstrap-server 10.1.60.114:9092 --topic test --partition 1 --election-type preferred
--partition为指定要重新选举的分区号
--election-type为选举模式,可以是preferred或unclean
在preferred选举模式下,选举过程中会首先尝试将leader选举为ISR列表中的一个副本。这是因为ISR副本与leader副本保持同步,因此它们的数据是一致的,可以保证不会发生数据丢失。如果ISR列表中没有可用的副本,则会将leader选举为非ISR副本。非ISR副本与leader副本可能存在数据不一致的情况,因此在选举非ISR副本为新leader时,可能会发生数据丢失
在unclean模式下,则会将leader选举为分区中的任何一个副本,而不考虑其是否与leader同步。这种类型的选举可能会导致数据丢失,因此应该谨慎使用
总之,preferred选举模式的工作原理是优先选举与leader副本同步的ISR副本作为新的leader,以保证数据的一致性和可靠性
重新选举一般都是选举为replica项的第一个broker id为leader,即原来的broker节点

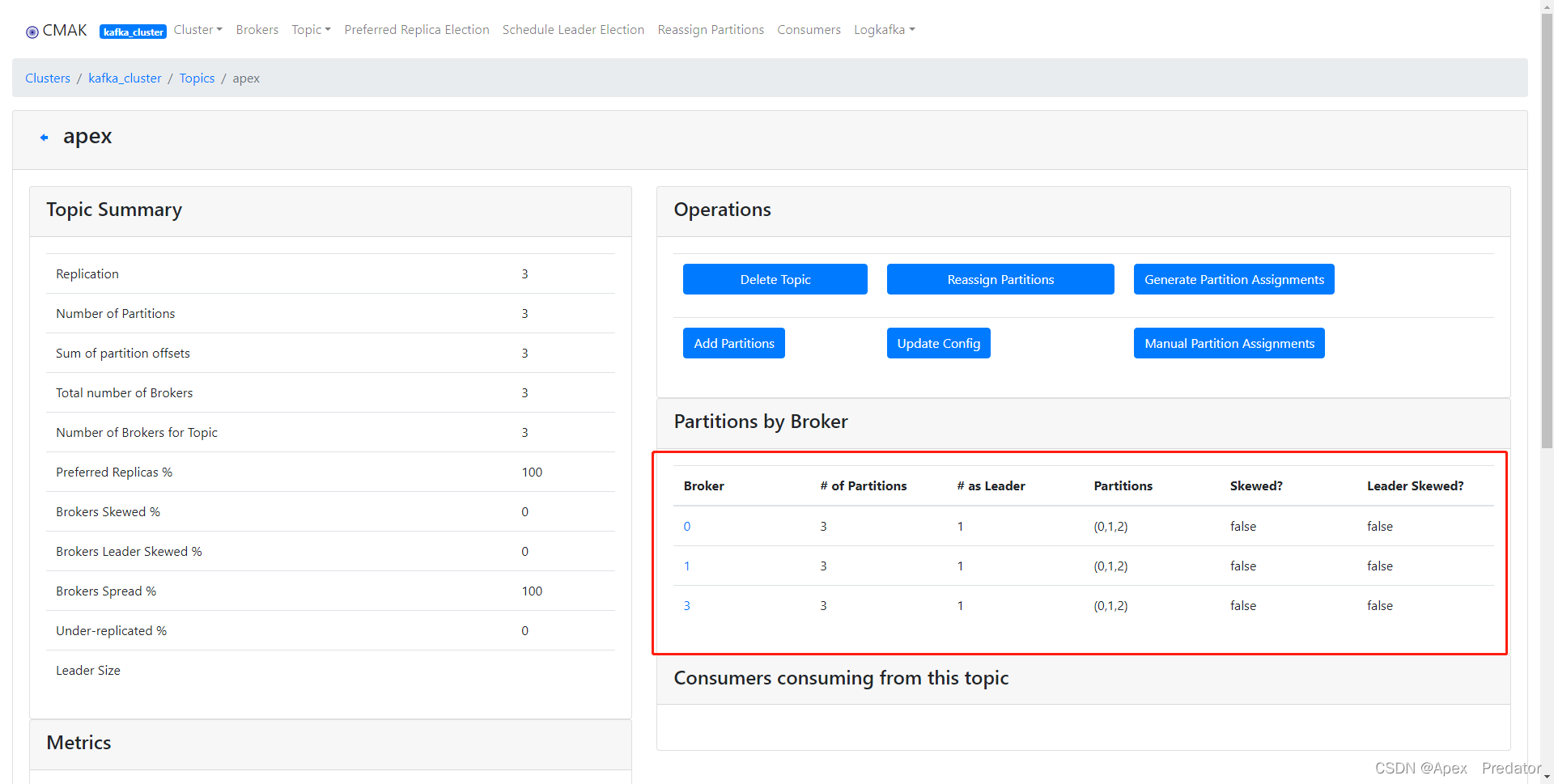

可以看到partition的leader都被分配回了原来的broker节点上
不用担心重新选举其它节点为leader节点后数据会不一致
在Kafka中,ISR副本是与leader副本保持同步的副本,它们的数据是一致的。当一个ISR副本被选举为新的leader时,它会从上一个leader副本处继续消费消息,因此不会出现重复消费的情况
当一个ISR副本失去同步时,它就会从ISR列表中删除,此时就需要重新选举一个新的leader。如果选举过程中选举为非ISR副本,那么可能会出现数据丢失或重复消费的情况。因此,在选举新的leader时,应该优先选择ISR副本,以保证数据的一致性和可靠性
ISR中所有的副本在任意时刻都与leader的数据是一致的,这是Kafka提供的数据可靠性保证之一
当生产者向Kafka发送消息时,只有当消息被ISR列表中的所有副本都成功地写入后,才会向生产者返回成功的响应。这意味着ISR列表中的所有副本都已经成功地复制了消息,因此它们的数据是一致的。当消费者从ISR副本中读取消息时,它们也可以保证读取到与leader副本相同的数据

















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









