




文章目录
在大规模语言模型(LLM)的研究与应用中,Attention(注意力机制) 是最核心的概念之一。它不仅改变了深度学习处理序列数据的方式,也在一定程度上模拟了人类的“选择性注意”(Selective Attention)过程。本文将探讨选择性注意在LLM中的体现、它与传统注意力机制的差异,以及它对模型效率与智能行为的启示。
一、人类的选择性注意:从信息过载到聚焦
在人类认知中,选择性注意 是一种有限资源的管理方式。面对大量感官输入,我们会自动筛选出与当前任务相关的信息,而忽略无关的背景。心理学家Broadbent在1958年提出的“过滤器模型”认为,大脑在早期阶段就会过滤无关刺激,只保留必要的信息进入意识处理。
这种机制的意义在于:
-
提高处理效率:避免被无关信息干扰。
-
强化语义理解:将认知资源集中于关键刺激。
-
体现目标导向:根据任务需求动态调整注意焦点。
这种人类的认知模式,为人工神经网络中的注意力机制提供了启发。
二、从Attention到Selective Attention:模型的聚焦方式
在Transformer架构中,Self-Attention 允许每个token根据上下文动态分配注意权重,从而捕获长程依赖关系。然而,标准的Attention是全连接式的:每个token都要计算与其他所有token的相关性。这种全局机制带来了两大问题:
-
计算复杂度高:O(n²)的代价在长序列任务中难以承受。
-
语义冗余:许多token之间的注意力权重接近零,计算资源被浪费。
为此,研究者提出了Selective Attention 的概念,即在模型中引入“选择性”机制,让模型自动聚焦于最相关的部分,而非全局遍历。
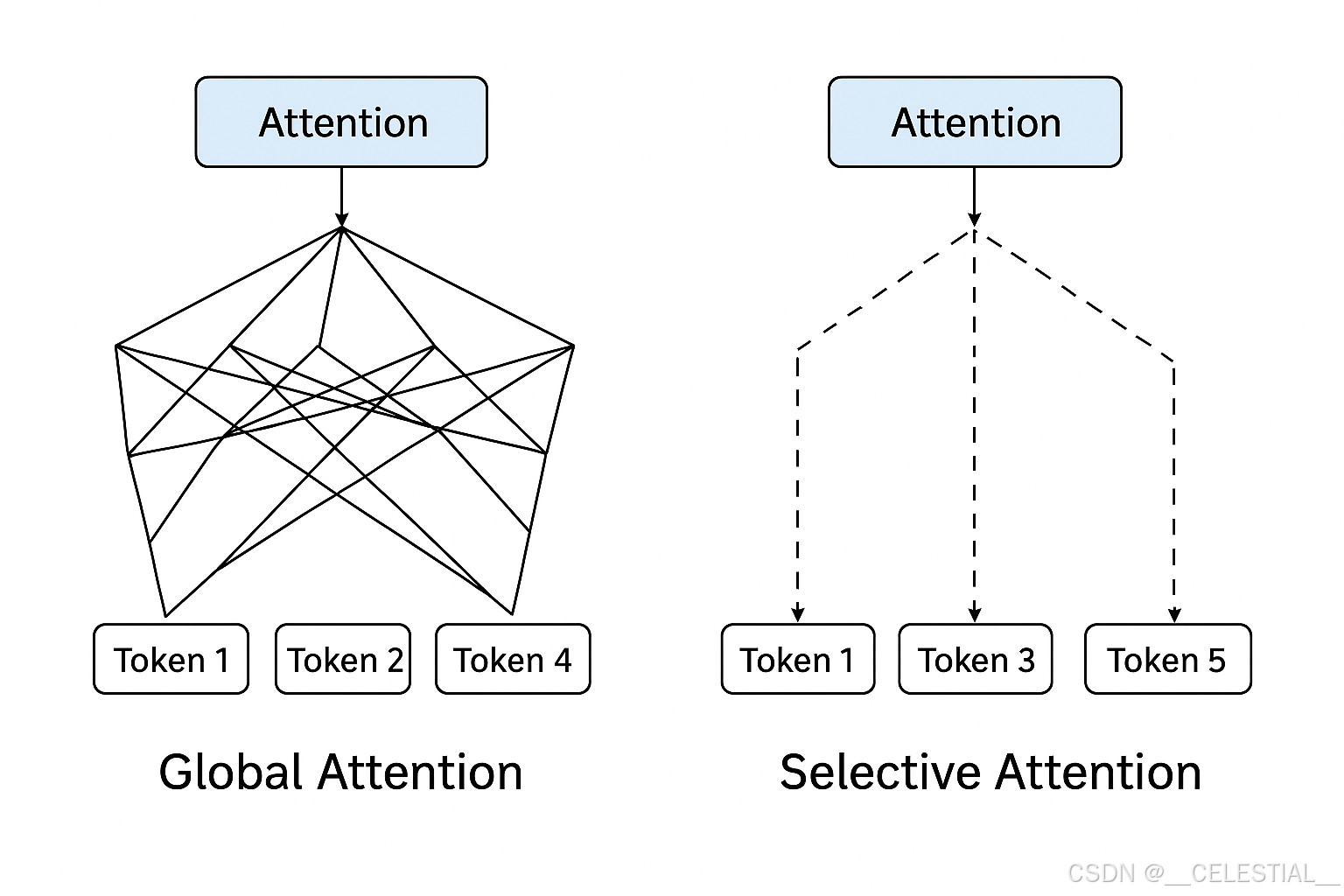
三、LLM中的Selective Attention实现
Selective Attention在LLM中的实现形式多样,常见方向包括:
-
Sparse Attention(稀疏注意力)
模型只计算局部或模式化连接,如Longformer、BigBird等。通过设计稀疏矩阵结构,模型能在保留语义依赖的同时,将复杂度降至近线性级别。 -
Learned Attention Patterns(学习型注意模式)
模型在训练中学习何处应关注,如Routing Transformer使用动态路由,使每个token只与特定簇内的token交互。 -
Selective KV Caching(选择性缓存)
在推理阶段,只保留与当前上下文强相关的Key-Value对,以降低存储开销。这是当前高效推理研究的热点,例如StreamingLLM与Dynamic Context Pruning等方法。 -
Token Pruning / Attention Head Pruning
模型在推理过程中动态剪枝,移除贡献较小的token或注意头,从而在保证输出质量的前提下降低计算量。
这些方法的共同点在于:通过引入“选择性”机制,让模型学会忽略冗余信息、集中资源于语义关键部分。
四、选择性注意与智能行为
引入选择性注意不仅是为了提升性能,更是为了让LLM的行为更接近人类认知。
在长上下文理解中,模型需要判断哪些信息应被保留、哪些可以遗忘。这种“注意的分配”其实就是一种认知控制,体现了智能体的目标导向与信息约束。
未来,选择性注意可能成为模型可解释性与高效记忆系统的重要桥梁:
-
模型可以展示“为什么关注这些内容”,帮助人类理解决策路径。
-
模型可以通过Selective Attention实现持续学习与上下文记忆,而非简单地依赖海量参数。
五、结语
从人类的聚焦机制到Transformer的注意力,再到LLM的选择性注意,人工智能的发展正在逐渐逼近人类认知的本质:在有限资源下作出有意义的选择。
Selective Attention 不仅是算法优化的方向,更是通向具备理解力与目标意识的智能系统的一扇窗口。


















 3092
3092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









