




Motivation:
目前在命名实体识别任务上表现最好的模型都严重依赖于人工构造的特征(基于规则),因为关于NER任务的语料很少,通过神经网络难以训练一个合适的模型,所以很多人提出在使用监督+无监督的语料提升模型的表现。本文提出两种神经网络结构且仅仅使用有限的监督数据实现了state-of-the-art performance。
模型结构:
本文提出两种模型,LSTM-CRF和Stack LSTM:
- LSTM-CRF:源序列(一段文本)输入到BiLSTM中,然后输出一个单词的考虑到上下文的特征表示ht。然后ht输入到CRF中,因为CRF可以考虑全局依赖。以序列Mark Watney visited Mars为例,输出B-PER其中B代表一个实体的开始,PER代表实体类别(person)。
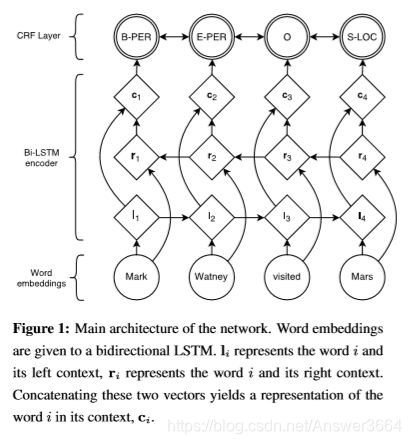
2. Stack LSTM:源序列(一段文本)输入到LSTM中,然后输出每个单词对于各种操作(SHI
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









