




 本文介绍了马尔可夫决策过程(MDP)的基本概念及其在强化学习中的应用,包括状态、行为、转移概率、奖励和策略等核心元素,并讨论了策略迭代与值迭代算法。
本文介绍了马尔可夫决策过程(MDP)的基本概念及其在强化学习中的应用,包括状态、行为、转移概率、奖励和策略等核心元素,并讨论了策略迭代与值迭代算法。
引言
在概率论及统计学中,马尔可夫过程(英语:Markov process)是一个具备了马尔可夫性质的随机过程,因为俄国数学家安德雷·马尔可夫得名。马尔可夫过程是不具备记忆特质的(memorylessness)。换言之,马尔可夫过程的条件概率仅仅与系统的当前状态相关,而与它的过去历史或未来状态,都是独立、不相关的。

概论

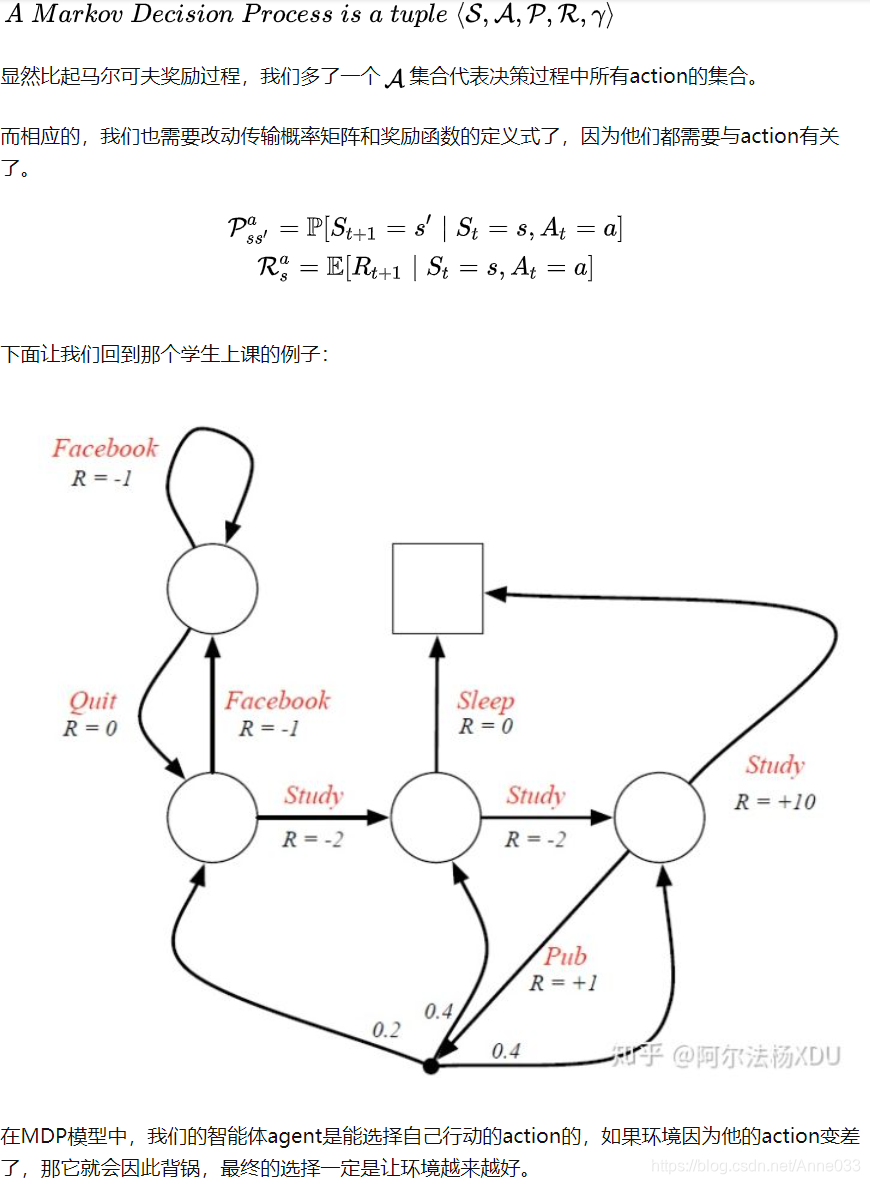
1. Markov Decision Process马尔可夫决策过程
机器学习算法(有监督,无监督,弱监督)中,马尔科夫决策过程是弱监督中的一类叫增强学习。增加学习与传统的有监督和无监督不同的地方是,这些方法都是一次性决定最终结果的,而无法刻画一个决策过程,无法直接定义每一次决策的优劣,也就是说每一次的决策信息都是弱信息,所以某种程度上讲,强化学习也属于弱监督学习。从模型角度来看,也属于马尔科夫模型,其与隐马尔科夫模型有非常强的可比性。
下面是一个常用的马尔科夫模型的划分关系

1.1 MDP定义
MDP就是具有决策状态的马尔可夫奖励过程。这里我们直接给出了马尔可夫决策过程的定义:

- 状态(state): 智能体在每个步骤中所处于的状态集合
- 行为(action): 智能体在每个步骤中所能执行的动作集合
- 转移概率(transition): 智能体处于状态s下,执行动作a后,会转移到状态s’的概率
- 奖励(reward): 智能体处于状态s下,执行动作a后,转移到状态s’后获得的立即奖励值
- 策略(policy): 智能体处于状态s下,应该执行动作a的概率

值得注意的是,在马尔科夫决策过程中,状态集合是离散的,动作集合是离散的,转移概率是已知的,奖励是已知的。在这个条件下的学习称之为有模型学习。
1.2 问题求解1

1.2.1 策略迭代算法


1.2.2 值迭代算法


1.3 实例
1.3.1 策略迭代实例

使用马尔科夫决策过程策略迭代算法进行计算,具体过程详见,
https://github.com/persistforever/ReinforcementLearning/tree/master/carrental
1.3.2 值迭代实例
赌徒问题 :一个赌徒抛硬币下赌注,如果硬币正面朝上,他本局将赢得和下注数量相同的钱,如果硬币背面朝上,他本局将输掉下注的钱,当他输光所有的赌资或者赢得$100则停止赌博,硬币正面朝上的概率为p。赌博过程是一个无折扣的有限的马尔科夫决策问题。
使用马尔科夫决策过程值迭代算法进行计算,具体过程详见,
https://github.com/persistforever/ReinforcementLearning/tree/master/gambler
1.4 问题求解2
1.4.1 Policies策略

1.4.2 Policy based Value Function基于策略的价值函数

1.4.3 Bellman Expectation Equation贝尔曼期望方程



1.4.4 Optimal Value Function最优价值函数

1.4.5 Theorem of MDP定理

1.4.6 Finding an Optimal Policy寻找最优策略

1.4.7 Bellman Optimality Equation贝尔曼最优方程


1.4.7.1 Solving the Bellman Optimality Equation求解贝尔曼最优方程
贝尔曼最优方程是非线性的,通常而言没有固定的解法,有很多著名的迭代解法:
- Value Iteration 价值迭代
- Policy Iteration 策略迭代
- Q-learning
- Sarsa
这个可以大家之后去多了解了解。
1.5 最优决策
也许上面的目标函数还不清晰,如何求解最有决策,如何最大化累积回报
下面结合例子来介绍如何求解上面的目标函数。且说明累积回报函数本身就是一个过程的累积回报,回报函数才是每一步的回报。

下面再来看求解上述最优问题,其中 就是以s为初始状态沿着决策函数走到结束状态的累积回报。
1.6 值迭代

1.7 策略迭代
值迭代是使累积回报值最优为目标进行迭代,而策略迭代是借助累积回报最优即策略最优的等价性,进行策略迭代。

1.8 MDP中的参数估计
回过头来再来看前面的马尔科夫决策过程的定义是一个五元组,一般情况下,五元组应该是我们更加特定的问题建立马尔科夫决策模型时该确定的,并在此基础上来求解最优决策。所以在求解最优决策之前,我们还需更加实际问题建立马尔科夫模型,建模过程就是确定五元组的过程,其中我们仅考虑状态转移概率,那么也就是一个参数估计过程。(其他参数一般都好确定,或设定)。
假设,在时间过程中,我们有下面的状态转移路径:

2. Markov Reward Process马尔可夫奖励过程
2.1 MRP
简单来说,马尔可夫奖励过程就是含有奖励的马尔可夫链,要想理解MRP方程的含义,我们就得弄清楚奖励函数的由来,我们可以把奖励表述为进入某一状态后收获的奖励。奖励函数如下所示:

2.2 Return回报

2.3 Value Function价值函数

2.4 Bellman Equation贝尔曼方程

https://zhuanlan.zhihu.com/p/271221558

















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









