




 本文探讨了在面对复杂HTTP日志数据时如何提取特征变量,包括依赖专家知识或研究文献来确定特征。接着介绍了数据预处理步骤,如归一化和处理缺失值。最后,讨论了使用不同聚类算法(如BIRCH、DBSCAN、K-MEANS、MEAN-SHIFT)结合特征权重检测异常点的方法及其效果。
本文探讨了在面对复杂HTTP日志数据时如何提取特征变量,包括依赖专家知识或研究文献来确定特征。接着介绍了数据预处理步骤,如归一化和处理缺失值。最后,讨论了使用不同聚类算法(如BIRCH、DBSCAN、K-MEANS、MEAN-SHIFT)结合特征权重检测异常点的方法及其效果。
实际上遇到数据的时候,数据很可能是非常隐晦的,很难看出来想表达出来什么,像列表那样的数据其实已经是一目了然的很清晰的数据了,但是如果是碰到类似于下图所示的数据时,我们就要想办法提取出一些特征变量了。
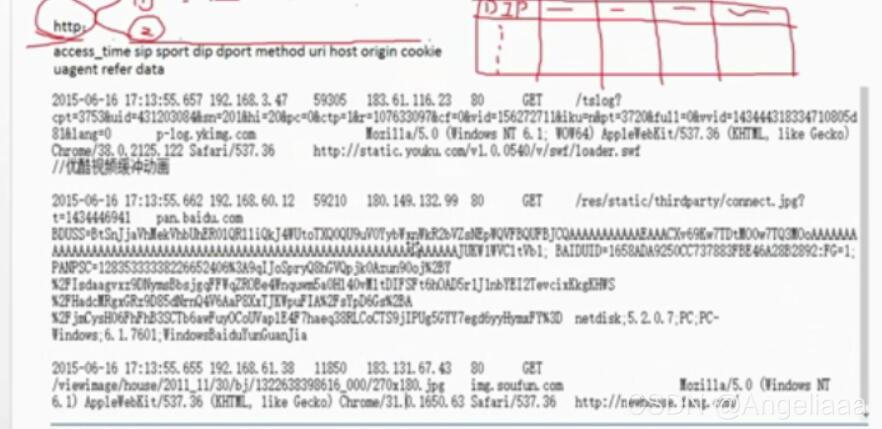
1.提取特征变量
根据题目要求,提取出一些特征变量,提取这些特征变量的方法有两个,第一就是找一个从业三十多年的专家,他说哪个是特征变量,咱就如醍醐灌顶一样立马提取这些特征变量,另一个就是根据平时积累的知识,或者看一些期刊、论文去提取出这些特征变量。提取出的特征变量如下图所示

对应的数量列是这样的:
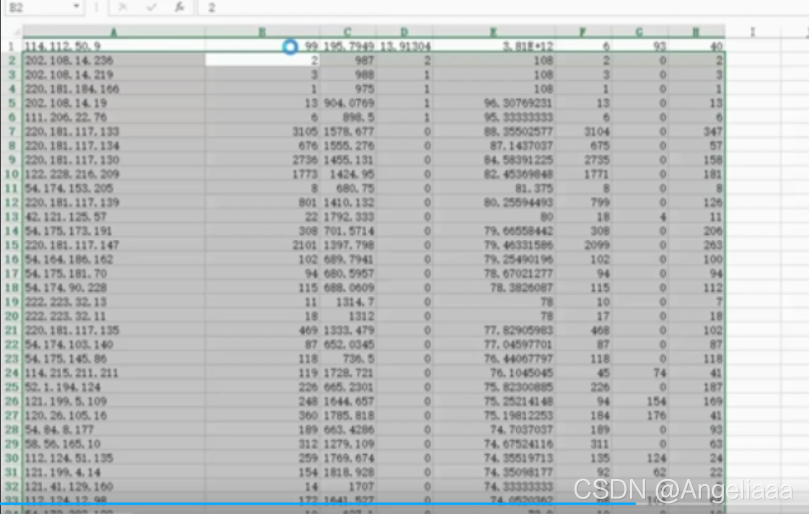
2.处理特征数据
提取完数据之后,对这些数据进行归一化,但是有些列的数据大的太大,小的太小,所以我们不妨可以将前几十个最大的数字给去掉,然后再算归一化的值,end_value=now_value/(maxx-minn),有大于1的数据也没什么关系。最后处理一下缺失值,删掉有缺失值的样本或者删掉某一列特征就可以。
3.运用聚类算法检查一下异常点
聚类算法有很多种,常见的是BIRCH、DBSCAN、K-MEANS、MEAN--SHIFT,然后由于特征之间的重要性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









