




 本文深入探讨了Spark SQL中丰富的内置函数,包括UDF自定义函数、聚合函数、日期时间函数等多种类型,共计307个。这些函数极大简化了Spark数据分析流程,适合通过大量实践来熟练掌握。
本文深入探讨了Spark SQL中丰富的内置函数,包括UDF自定义函数、聚合函数、日期时间函数等多种类型,共计307个。这些函数极大简化了Spark数据分析流程,适合通过大量实践来熟练掌握。
前言
Spark源码中的org.apache.spark.sql包下有一个叫做functions.scala的文件,该文件包含了大量的内置函数,尤其是在agg中会广泛使用(不仅限于此)
这些内置函数可以极大的简化spark数据分析,到Spark2.2已经拥有307个函数,只有通过大量实践才能熟练掌握
函数分类
UDF自定义函数、聚合函数、日期时间函数、排序函数、非聚合函数、数学函数、窗口函数、字符串函数、集合函数、其他函数等,如下所示。
- Functions函数功能可用于DataFrame的操作。
- @groupname udf_funcs UDF自定义函数
- @groupname agg_funcs聚合函数
- @groupname datetime_funcs日期时间函数
- @groupname sort_funcs排序功能
- @groupname normal_funcs非聚合函数
- @groupname math_funcs数学函数
- @groupname misc_funcs其他功能
- @groupname window_funcs窗口函数
- @groupname string_funcs字符串函数
- @groupname collection_funcs集合函数功能
- @groupname DataFrames不分组支持功能
- @since自从1.3.0
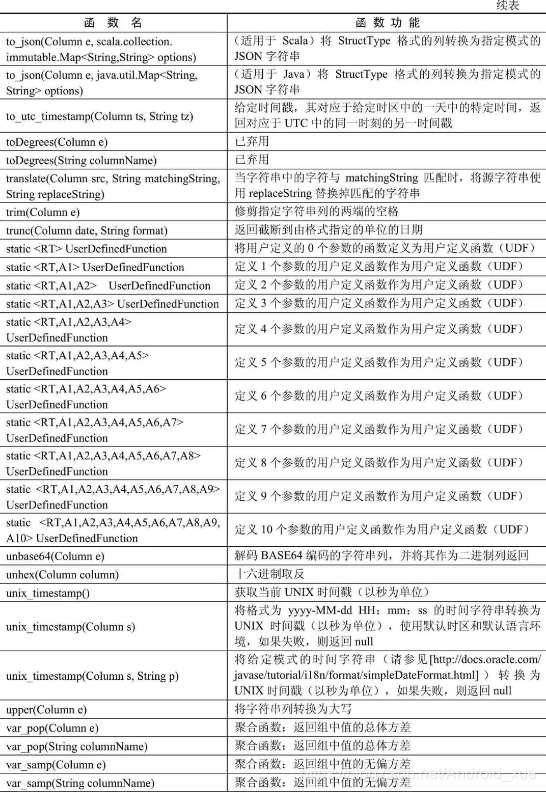
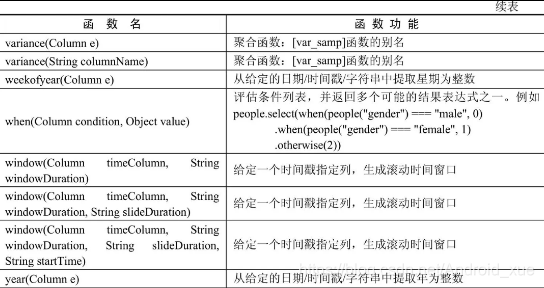
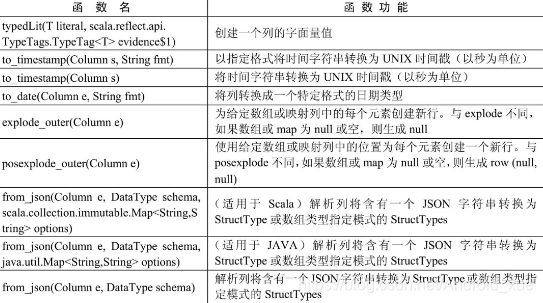
API汇总
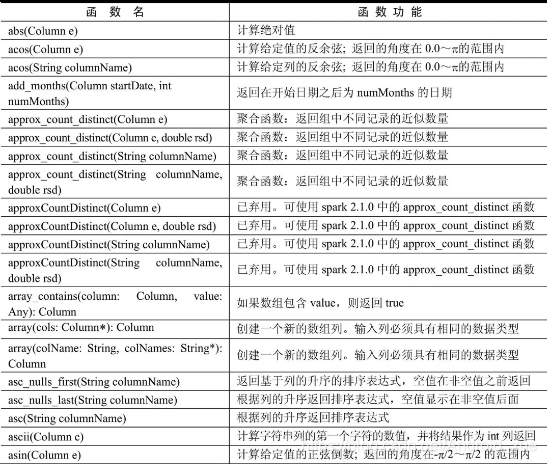
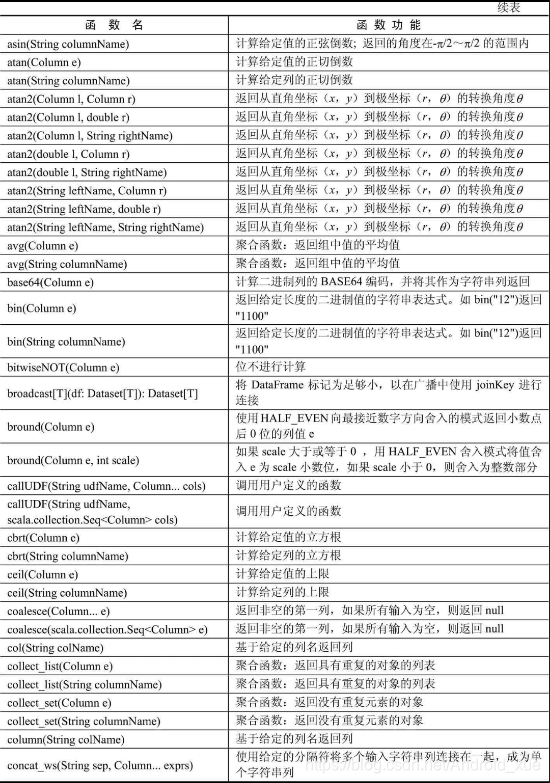
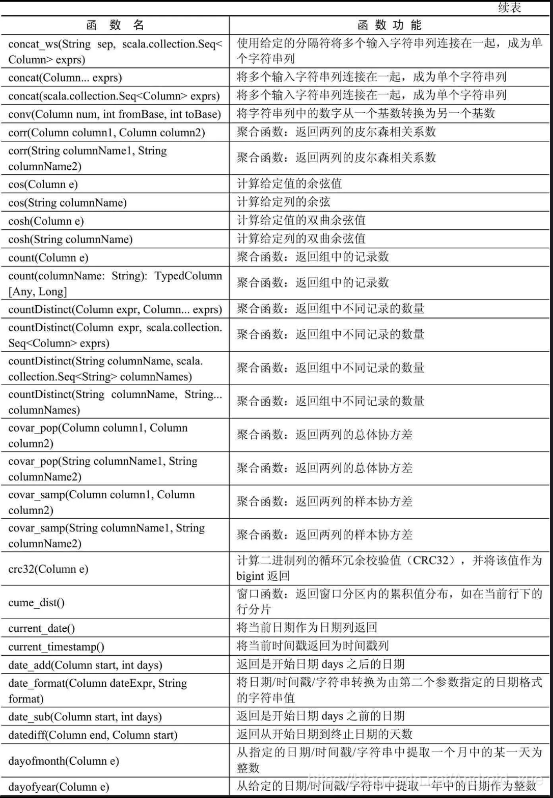
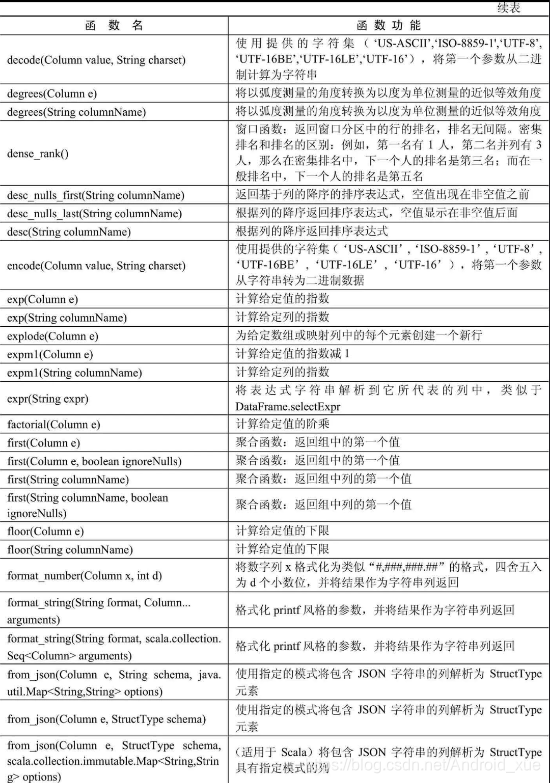
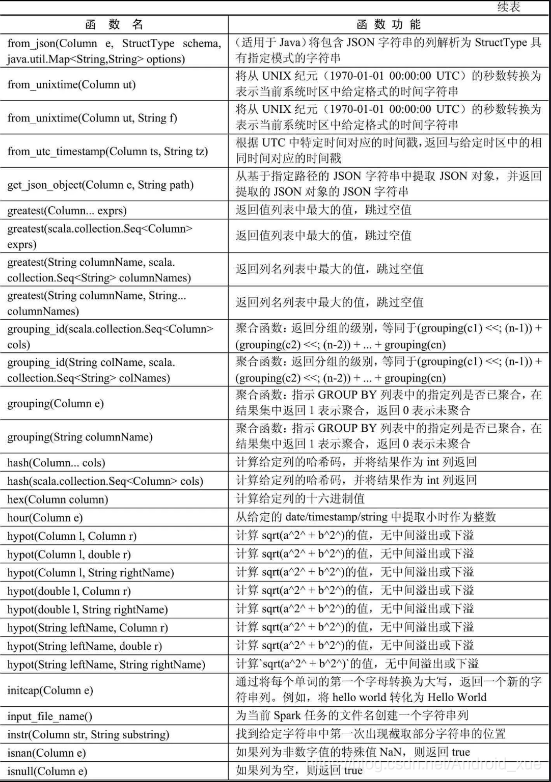
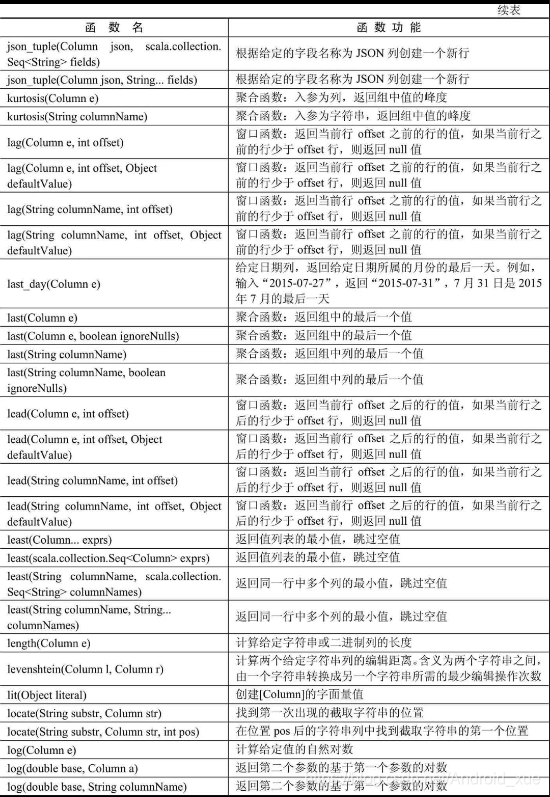
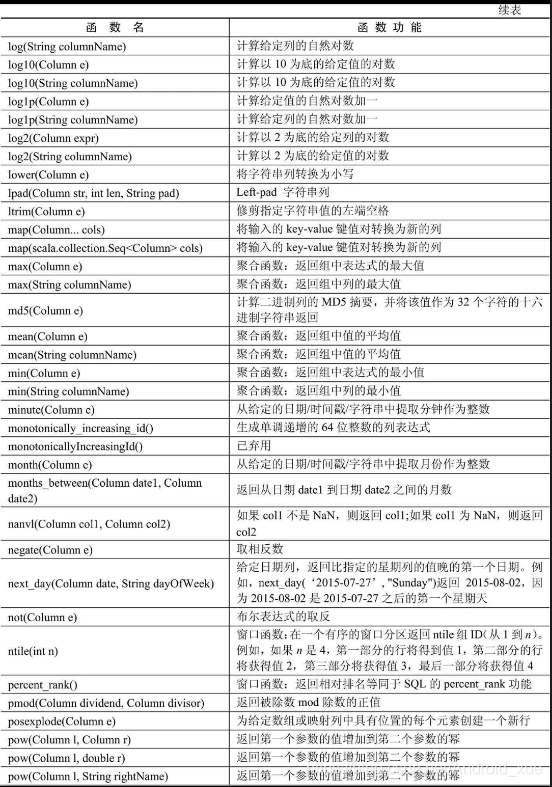

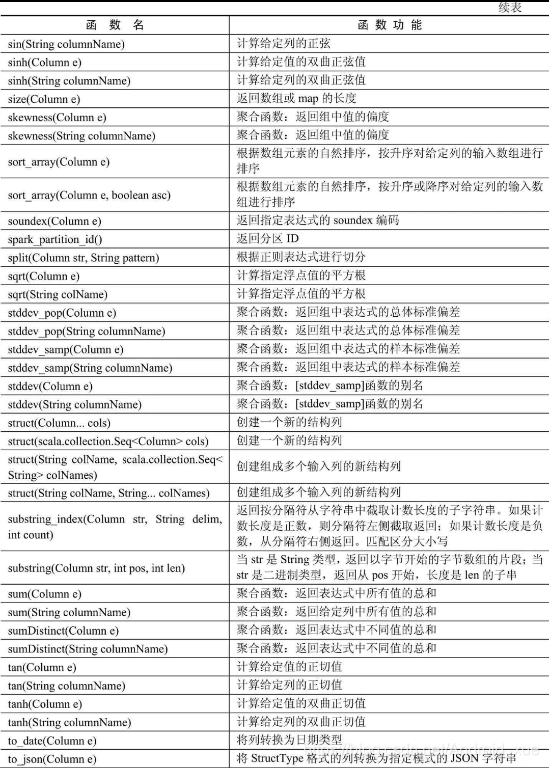
后记
看到这么多函数,是不是很happy啊,哈哈,赶紧登陆官网慢慢享受吧


















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











