 Spark为何比MapReduce快
Spark为何比MapReduce快





 本文探讨了Spark相较于Hadoop MapReduce速度快的原因,关键在于其先进的DAG程序、内存处理和减少磁盘I/O,以及应用程序级别的任务链接,无需频繁写入磁盘。
本文探讨了Spark相较于Hadoop MapReduce速度快的原因,关键在于其先进的DAG程序、内存处理和减少磁盘I/O,以及应用程序级别的任务链接,无需频繁写入磁盘。
前言
边上的哥们问了这样一个问题:
无论什么数据都必须得加载到在内存中计算,为什么Spark就比MapReduce快那么多?
先上一幅Spark官网的图:

在官网这张图里隐隐约约的看到一个词:DAG
使用最先进的DAG程序——这一句话已经告诉我们速度提高100倍的关键原因(当然后面写的查询优化器和物理执行引擎也是一部分原因),好了,这哥们的问题已经解决了
简要说明
Spark对速度的最大声称是它能够 “在内存中运行程序比Hadoop MapReduce快100倍,在磁盘上运行速度提高10倍。” Spark可以提出这种说法,因为它在工作节点的主存储器中进行处理,并防止对磁盘进行不必要的 I / O操作。
Spark提供的另一个优势是即使在应用程序编程级别也可以链接任务,而无需写入磁盘或最大限度地减少对磁盘的写入次数(说的就是DAG的好处)。
煮个例子描述
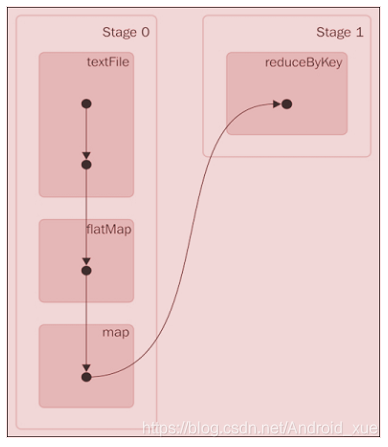
val textFile = sc.textFile("README.md")
val wordCounts = textFile.flatMap(line => line.split(" ")).map(word =>
(word, 1)).reduceByKey((a, b) => a + b)
wordCounts.collect()
代码在运行中生成的上一个Spark作业的DAG将如下所示:
后记
可参考


















 1075
1075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











