



最近在研究智能体的时候,突然意识到一个问题:我们花了这么多时间优化RAG,可能从一开始就搞错了重点。
RAG不是终点,它只是个过渡阶段。真正的未来在AI记忆上。
今天想和你聊聊这个话题,顺便手把手带你实现一个带记忆功能的智能体。
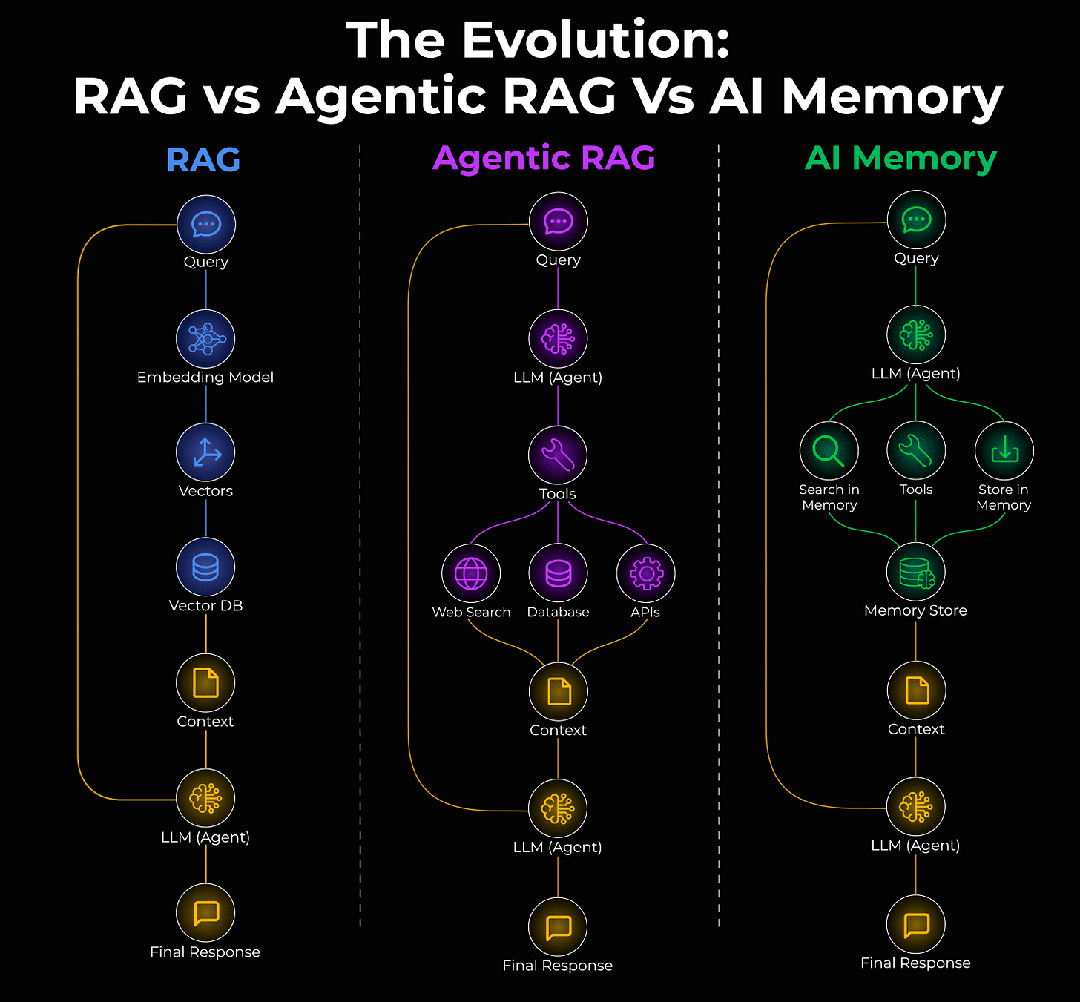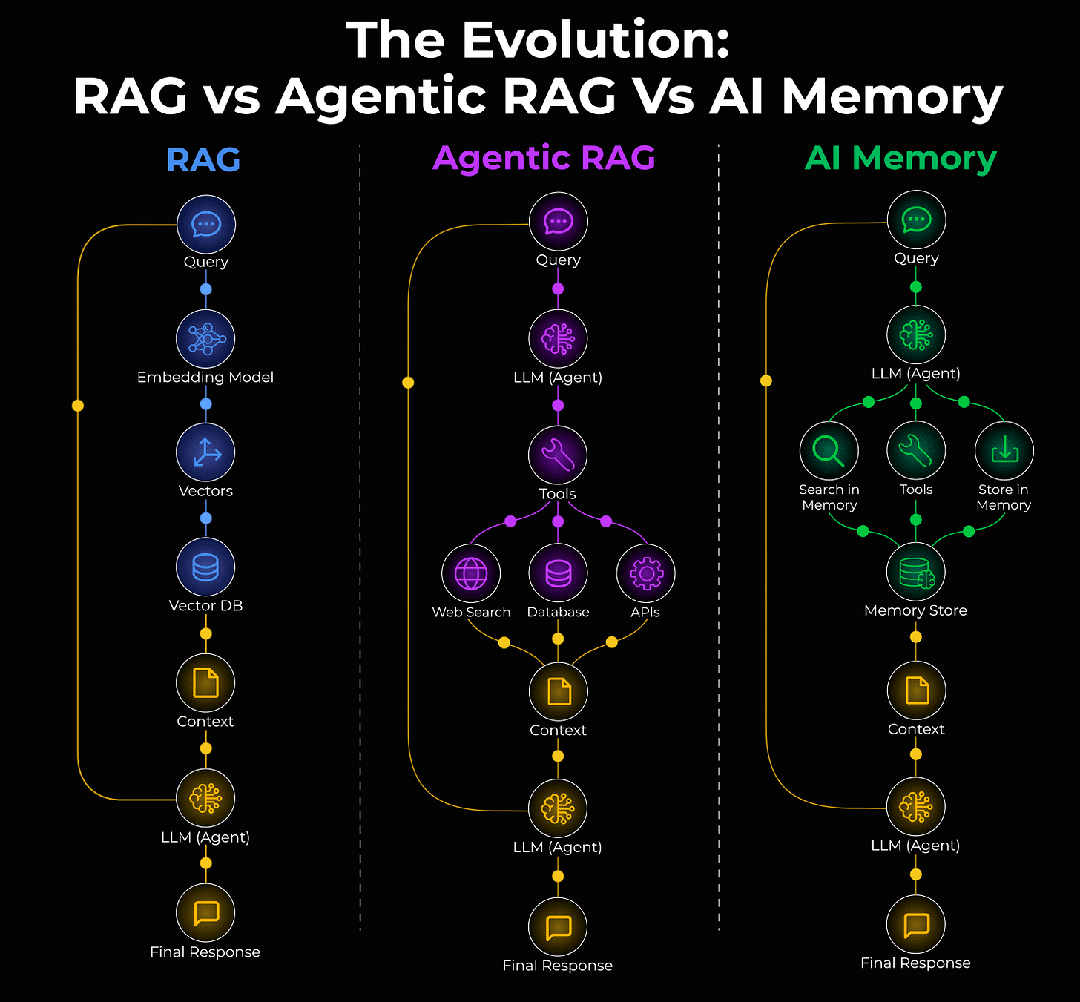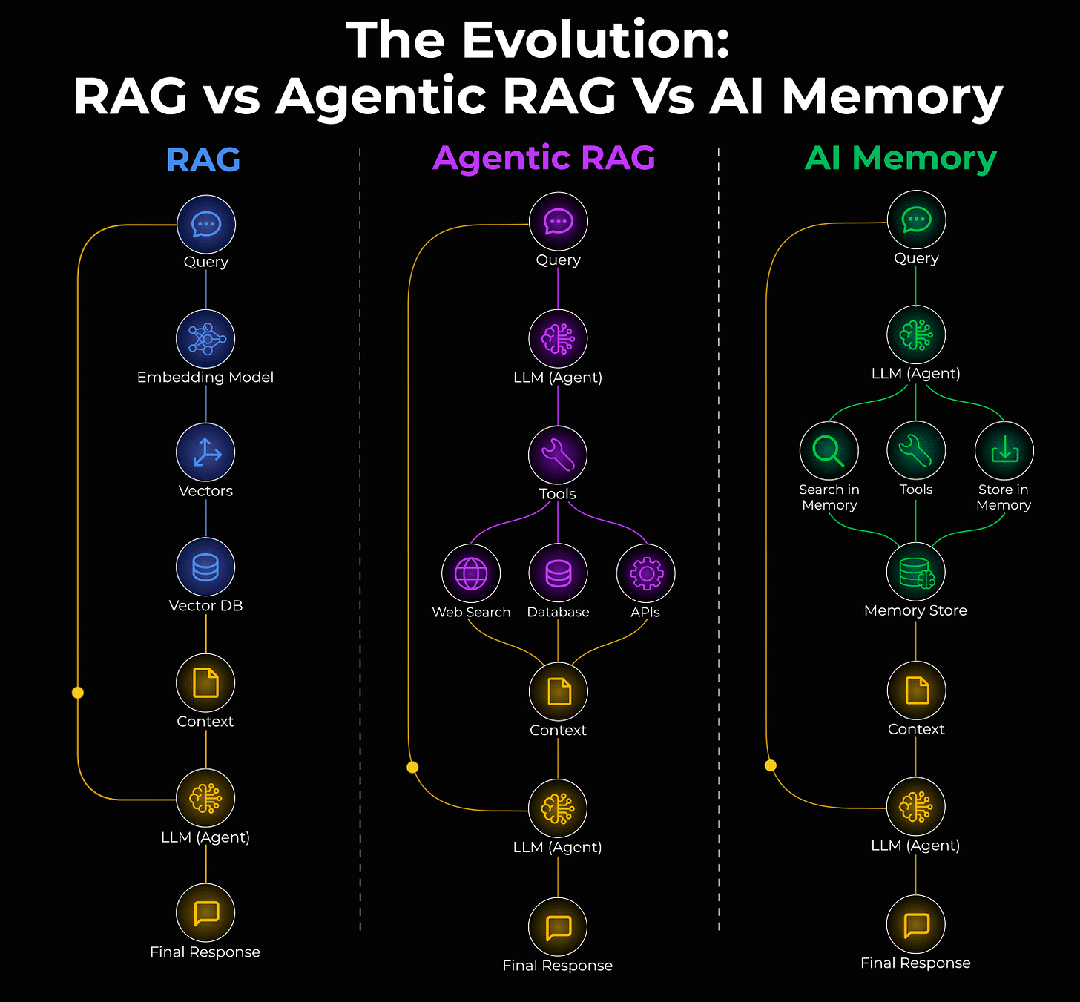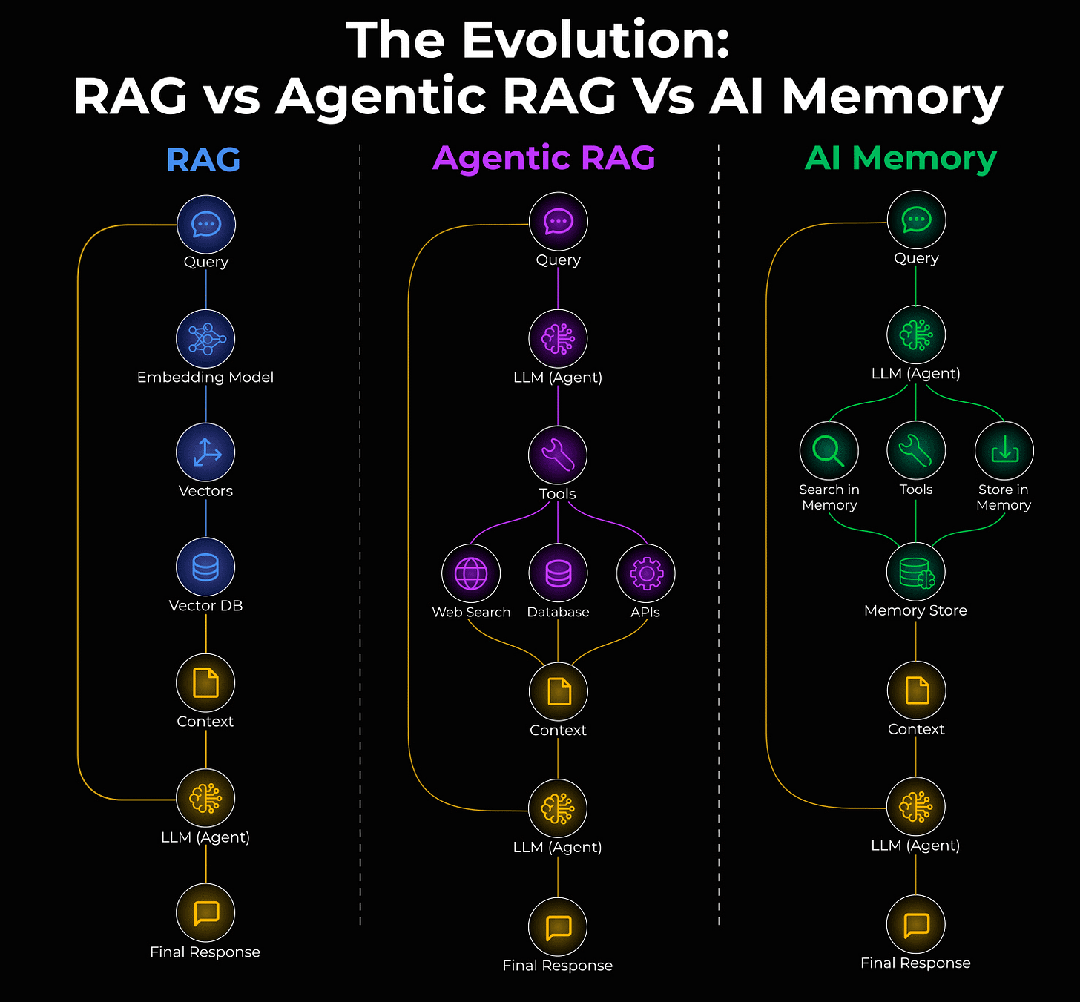
一、先说说这三个阶段
第一阶段:传统RAG(2020-2023)
这个你肯定熟悉。用户问问题,系统检索向量数据库,找到相关文档,塞给大模型,生成回答。整个过程像个流水线,机械但高效。
问题也很明显:检索到的上下文经常不相关,或者说相关但不够精准。你搜"苹果手机发热",它可能给你返回一堆"手机散热原理"的理论知识,而不是实际的解决方案。
第二阶段:智能体RAG
这时候智能体登场了。它不再傻乎乎地每次都检索,而是会判断:
- 这个问题需要检索吗?
- 该去哪个数据源找?
- 检索结果靠谱吗?
本质上,智能体把RAG变成了一个"工具",想用就用,不用就不用。
但问题是:它还是只读的。每次对话结束,所有上下文都丢了。下次用户再来,又是从零开始。
第三阶段:AI记忆
这才是真正有意思的部分。
智能体不仅能读取知识,还能写入记忆。它会记住:
- 用户叫什么,做什么工作
- 上次聊到哪儿了
- 用户的偏好和习惯
- 之前解决问题的经验
这意味着什么?意味着智能体终于可以"成长"了。
二、动手实现一个记忆系统
说了这么多理论,咱们来点实际的。我基于Graphiti项目做了个简化版的记忆系统,让你看看这东西到底怎么运作。
先装依赖:
pip install anthropic neo4j graphiti-core
核心代码不复杂,分三块:
1. 初始化记忆引擎
import os
from anthropic import Anthropic
from graphiti_core import Graphiti
from graphiti_core.nodes import EpisodicNode
from datetime import datetime
import asyncio
# ============= 配置部分 =============
# 需要设置以下环境变量:
# export ANTHROPIC_API_KEY="your-api-key"
# export NEO4J_URI="bolt://localhost:7687"
# export NEO4J_USER="neo4j"
# export NEO4J_PASSWORD="your-password"
class MemoryAgent:
"""带记忆功能的AI智能体"""
def __init__(self):
# 初始化Anthropic客户端
self.client = Anthropic(api_key=os.environ.get("ANTHROPIC_API_KEY"))
# 初始化Graphiti记忆引擎
self.graphiti = Graphiti(
neo4j_uri=os.environ.get("NEO4J_URI", "bolt://localhost:7687"),
neo4j_user=os.environ.get("NEO4J_USER", "neo4j"),
neo4j_password=os.environ.get("NEO4J_PASSWORD")
)
async def initialize(self):
"""异步初始化记忆系统"""
await self.graphiti.build_indices()
print("✓ 记忆系统初始化完成")
async def store_memory(self, user_input: str, assistant_response: str, user_id: str = "default_user"):
"""
存储对话记忆
参数:
user_input: 用户输入
assistant_response: 助手回复
user_id: 用户ID
"""
# 构建情景记忆内容
episode_content = f"用户说: {user_input}\n助手回复: {assistant_response}"
# 创建情景节点
episode = EpisodicNode(
name=f"conversation_{datetime.now().isoformat()}",
labels=["Conversation"],
content=episode_content,
source_description="用户对话",
created_at=datetime.now()
)
# 存入图数据库
await self.graphiti.add_episode(
name=episode.name,
episode_body=episode_content,
source_description=episode.source_description,
reference_time=datetime.now()
)
print(f"✓ 记忆已存储: {episode.name}")
async def retrieve_memories(self, query: str, limit: int = 5):
"""
检索相关记忆
参数:
query: 查询文本
limit: 返回结果数量
返回:
相关记忆列表
"""
results = await self.graphiti.search(
query=query,
num_results=limit
)
memories = []
for result in results:
if hasattr(result, 'content'):
memories.append(result.content)
return memories
async def chat(self, user_input: str, use_memory: bool = True):
"""
对话接口
参数:
user_input: 用户输入
use_memory: 是否使用记忆功能
返回:
助手回复
"""
messages = []
# 如果启用记忆,先检索相关历史
if use_memory:
memories = await self.retrieve_memories(user_input, limit=3)
if memories:
context = "以下是相关的历史记忆:\n\n"
for i, memory in enumerate(memories, 1):
context += f"{i}. {memory}\n\n"
context += f"\n基于以上记忆和当前问题,请给出回答。\n\n当前问题: {user_input}"
messages.append({
"role": "user",
"content": context
})
else:
messages.append({
"role": "user",
"content": user_input
})
else:
messages.append({
"role": "user",
"content": user_input
})
# 调用Claude API
response = self.client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=messages
)
assistant_message = response.content[0].text
# 存储本次对话到记忆
if use_memory:
await self.store_memory(user_input, assistant_message)
return assistant_message
async def close(self):
"""关闭连接"""
await self.graphiti.close()
print("✓ 记忆系统已关闭")
# ============= 使用示例 =============
async def demo():
"""演示记忆功能的效果"""
agent = MemoryAgent()
await agent.initialize()
print("\n========== 第一轮对话 ==========")
response1 = await agent.chat("我叫老谭,是一名Python开发者,最近在研究AI智能体")
print(f"助手: {response1}\n")
print("========== 第二轮对话 ==========")
response2 = await agent.chat("我对RAG和向量数据库比较熟悉")
print(f"助手: {response2}\n")
print("========== 第三轮对话(测试记忆) ==========")
response3 = await agent.chat("你还记得我是做什么的吗?")
print(f"助手: {response3}\n")
print("========== 第四轮对话(测试记忆) ==========")
response4 = await agent.chat("根据我的背景,推荐一些学习资源")
print(f"助手: {response4}\n")
await agent.close()
async def interactive_mode():
"""交互式对话模式"""
agent = MemoryAgent()
await agent.initialize()
print("\n=== AI记忆助手已启动 ===")
print("输入 'exit' 退出, 'memory' 查看记忆统计\n")
try:
while True:
user_input = input("你: ").strip()
if user_input.lower() == 'exit':
break
if user_input.lower() == 'memory':
# 这里可以添加记忆统计功能
print("记忆功能正在运行中...")
continue
if not user_input:
continue
response = await agent.chat(user_input)
print(f"\n助手: {response}\n")
finally:
await agent.close()
# ============= 运行脚本 =============
if __name__ == "__main__":
import sys
print("选择运行模式:")
print("1. 演示模式(自动对话)")
print("2. 交互模式(手动输入)")
choice = input("\n请选择 (1/2): ").strip()
if choice == "1":
asyncio.run(demo())
elif choice == "2":
asyncio.run(interactive_mode())
else:
print("无效选择")
sys.exit(1)
这套代码实现了三个核心功能:
- 存储记忆 (
store_memory):把每次对话都存进Neo4j图数据库。注意,这里不是简单的键值存储,而是带语义关系的图结构。 - 检索记忆 (
retrieve_memories):根据当前问题,找出最相关的历史记忆。这里用的是语义搜索,不是关键词匹配。 - 对话 (
chat):把检索到的记忆塞给Claude,让它基于历史上下文回答问题。
2. 环境准备
要跑通这个代码,你需要:
安装Neo4j
最简单的方式是用Docker:
docker run \
--name neo4j \
-p 7474:7474 -p 7687:7687 \
-e NEO4J_AUTH=neo4j/your-password \
neo4j:latest
然后浏览器打开 http://localhost:7474,能看到Neo4j界面就说明启动成功了。
设置环境变量
export ANTHROPIC_API_KEY="你的Claude API Key"
export NEO4J_URI="bolt://localhost:7687"
export NEO4J_USER="neo4j"
export NEO4J_PASSWORD="your-password"
3. 运行测试
代码里我写了两个模式:
- 演示模式:自动跑一组对话,让你看到记忆效果
- 交互模式:你可以手动输入,实时体验
直接运行:
python memory_agent.py
选择1进入演示模式,你会看到类似这样的输出:
========== 第一轮对话 ==========
助手: 你好老谭!很高兴认识你...
========== 第三轮对话(测试记忆) ==========
助手: 当然记得,你是老谭,一名Python开发者,目前在研究AI智能体...
关键点在第三轮:我没有重复说自己的信息,但助手记得。这就是记忆的力量。
三、背后的原理
你可能会好奇:这和传统RAG有什么本质区别?
1、数据结构不同
- 传统RAG:文档切块→向量化→存入向量数据库
- 记忆系统:对话→实体提取→构建知识图谱
向量数据库存的是"相似性",图数据库存的是"关系"。
举个例子:
- 向量库知道"老谭"和"Python开发"语义相近
- 图数据库知道"老谭"是"Python开发者","正在研究"AI智能体
2、写入能力
这是最关键的差异。RAG是只读的,记忆系统是读写的。
每次对话后,系统会:
- 提取新的实体和关系
- 更新现有节点的属性
- 建立新的关联边
这意味着知识图谱是"活"的,会随着交互不断生长。
3、检索策略
- 传统RAG:语义相似度排序
- 记忆系统:图遍历+语义搜索
比如你问"我上周提到的那个bug解决了吗?",系统会:
- 找到"上周"的时间节点
- 遍历相关的"bug"实体
- 查找最近的"解决状态"属性
这种多跳推理是纯向量检索做不到的。
四、实际应用中的坑
理论很美好,实际操作有不少坑“”
1、记忆污染
用户有时会说错话,或者开玩笑。系统如果全信,记忆就污染了。
我的处理方式是加一个置信度评分:
# 伪代码
if memory_confidence < 0.7:
mark_as_uncertain()
关键信息会要求多次确认才写入永久记忆。
2、遗忘机制
不是所有记忆都该永久保留。"今天天气真好"这种记忆一周后就该忘掉。
可以给记忆加个衰减权重:
memory_weight = base_weight * exp(-decay_rate * time_elapsed)
检索时优先返回高权重记忆。
3、多类型记忆
人的记忆分三种:
- 程序性记忆:怎么做事(骑自行车)
- 情景性记忆:发生了什么(昨天的对话)
- 语义性记忆:知识概念(Python是编程语言)
理想的系统应该分开管理这三种记忆,但实现起来很复杂。目前大部分系统混在一起存,效果其实也还行。
五、为什么这很重要
你可能会想:这不就是个聊天记录搜索吗?有必要搞这么复杂?
区别在于泛化能力。
- 传统聊天记录:你只能搜到说过的原话
- 记忆系统:它能理解你说的,推理出没说的
举个例子:
你说过:“我喜欢喝咖啡,但乳糖不耐”
几天后问:“附近有什么餐厅推荐?”
- 传统系统:推荐一堆餐厅
- 记忆系统:推荐餐厅,同时提醒"建议选择提供植物奶的咖啡店"
它把两条看似无关的记忆关联起来了。这才是真正的智能。
六、未来会怎样
记忆系统现在还在早期。
我觉得接下来会出现:
- 跨智能体的共享记忆(多个AI共享知识)
- 联邦学习的记忆更新(隐私保护)
- 多模态记忆(不只是文字,还有图片、声音)
最激动人心的是持续学习这个方向。
想象一下:你的AI助手今天学会了一个新技巧,明天所有用户的助手都会这个技巧,但不需要重新训练模型。
这才是记忆系统的终极形态。
七、总结
代码放在文章里了,你可以直接拿去跑。
本文只是抛砖引玉,可以参考这个思路,不是推荐某一个开源框架,使用过程中需要注意:
- Neo4j第一次启动会慢,别急
- Claude API有调用限制,别刷太快,也可以替换成国内的开源模型
- 记忆会一直累积,定期清理测试数据
最后说一句:别把记忆系统想得太神。它本质上就是个会写入的RAG,真正的挑战在于决策逻辑——什么该记,什么该忘,什么记忆更重要。
这些问题,现在没人有标准答案。
但这正是有意思的地方,不是吗?
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









