 大模型工作原理解析
大模型工作原理解析




大模型是如何工作的
近几十年来,人工智能经历了从基础算法到生成式AI的深刻演变。生成式AI通过学习大量数据可以创造出全新的内容,如文本、图像、音频和视频,这极大地推动了AI技术的广泛应用。常见的应用场景包括智能问答(如DeepSeek、GPT)、创意作画(如Stable Diffusion)以及代码生成(如通义灵码)等,涵盖了各个领域,让AI触手可及。
智能问答作为大模型最经典且广泛的应用之一,是我们探索大模型工作机制的最佳范例。接下来将介绍大模型在问答场景中的工作流程,帮助你更深入地理解其背后的技术原理。
在这里插入图片描述
大模型的工作流程
大模型的问答过程可分为 5 个核心阶段,以 “Python is a powerful” 生成完整句子为例:
阶段 1:输入文本分词化(Tokenization)
- 定义:将自然语言文本分割为模型可处理的基本单元(Token)
- 过程:
- 原始文本:“Python is a powerful”
- 分词结果:[“Python”, “is”, “a”, “powerful”](不同模型的分词规则略有差异,如 GPT 用 Byte Pair Encoding,通义千问用自定义分词器)
- Token ID 映射:每个 Token 对应唯一数字 ID(如 "Python"→54321,"is"→6789)
阶段 2:Token 向量化(Embedding)
- 作用:将离散的 Token 转换为连续的向量(数字矩阵),让计算机理解语义
- 细节:
- 每个 Token 被映射为固定维度的向量(如 GPT-3.5 为 1536 维,GPT-4 为 4096 维)
- 向量值由模型训练过程学习,语义相近的 Token 向量距离更近(如 “猫” 和 “狗” 的向量距离小于 “猫” 和 “汽车”)
阶段 3:大模型推理(Inference)
-
核心任务:基于输入向量,计算下一个 Token 的概率分布
-
过程:
-
模型通过注意力机制(Attention)捕捉 Token 间的语义关联(如 “Python” 与 “programming language” 的关联性)
-
输出所有可能 Token 的概率(如 “programming language” 概率 0.8,“tool” 概率 0.1,“script” 概率 0.05…)
阶段 4:输出 Token(Token Selection)
- 过程:根据 temperature/top_p 等参数,从候选 Token 中选择下一个 Token
- 示例:基于参数选择 “programming language” 作为下一个 Token
阶段 5:循环生成与结束判断
- 循环:将新生成的 Token(如 “programming language”)加入输入,重复阶段 3~4,继续生成下一个 Token(如 “used for data analysis”)
- 结束条件:
- 生成 “句子结束标记”(如
<|endoftext|>) - 输出 Token 数量达到
max_tokens阈值 - 最终结果:“Python is a powerful programming language used for data analysis.”
参数说明
temperature(温度参数)
- 作用:调整候选 Token 的概率分布,控制回答的多样性
- 取值范围:0~2(默认 1.0):
temperature=0:确定性最高,仅选择概率最高的 Token,适合事实性问答(如 “Python 中 list 和 tuple 的区别”)temperature=0.7:平衡随机性与准确性,适合创意性任务(如 “写一段产品宣传文案”)temperature=1.5:随机性极高,适合发散性思维(如 “为科幻小说构思 3 个世界观设定”)
top_p(核采样参数)
-
作用:通过累计概率筛选候选 Token 集合,控制采样范围
-
取值范围:0~1(默认 1.0)
-
例如:
top_p=0.9表示仅从概率累计达 90% 的 Token 中选择,排除低概率 Token -
使用建议:通常不与 temperature 同时调整,二选一即可(若需精准控制确定性,用 temperature;若需控制候选范围,用 top_p)
2.2.3 top_k(通义千问专属参数)
-
作用:从概率排名前 k 的 Token 中随机选择,控制候选数量
-
取值范围:1~100(默认 40)
-
top_k=1:仅选择概率最高的 Token,输出完全固定 -
top_k=50:从 top50 的 Token 中选择,兼顾多样性与准确性
seed(种子参数)
- 作用:固定生成结果的 “初始条件”,提升结果可重复性
- 使用场景:需多次生成相同 / 相似内容的场景(如固定格式的报告生成)
- 注意:即使设置相同 seed,分布式计算、模型优化等因素仍可能导致结果微小差异(无法 100% 完全一致)
假设在一个对话问答场景中,用户提问为:“在大模型课程中,你可以学习什么?”。为了模拟大模型生成内容的过程,我们预设了一个候选Token集合,这些Token分别为:“RAG”、“提示词”、“模型”、“写作”、“画画”。大模型会从这5个候选Token中选择一个作为结果输出(next-token),如下所示。
用户提问:在大模型ACP课程中,你可以学习什么? 大模型回答:RAG
在这个过程中,有两个重要参数会影响大模型的输出:temperature 和 top_p,它们用来控制大模型生成内容的随机性和多样性。 在大模型生成下一个词(next-token)之前,它会先为候选Token计算一个初始概率分布。这个分布表示每个候选Token作为next-token的概率。temperature是一个调节器,它通过改变候选Token的概率分布,影响大模型的内容生成。通过调节这个参数,你可以灵活地控制生成文本的多样性和创造性。
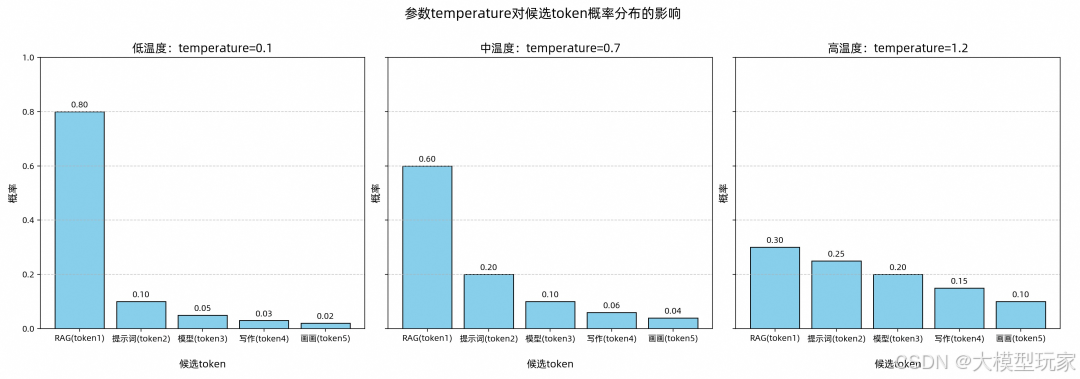
image.png
由上图可知,温度从低到高(0.1 -> 0.7 -> 1.2),概率分布从陡峭趋于平滑,候选Token“RAG”从出现的概率从0.8 -> 0.6 -> 0.3,虽然依然是出现概率最高的,但是已经和其它的候选Token概率接近了,最终输出也会从相对固定到逐渐多样化。

大模型的局限性与应对方案
局限性 1:输出随机性无法完全消除
问题描述
即使将 temperature 设为 0、top_p 设为 0.0001、seed 固定,仍可能出现结果不一致。
应对方案
- 工程层面:多次调用取交集(如生成 3 次回答,提取共同内容作为最终结果)
- 提示层面:在 prompt 中加入 “输出需严格遵循事实,不得添加无关内容” 等约束性描述
局限性 2:无法回答私域知识(未训练过的内容)
问题场景
如 “公司内部产品的技术参数”、“未公开的行业报告数据” 等,大模型无法直接回答。
应对方案(两种路径)
路径 1:不改变模型(低成本快速实现)
- 方法:采用 “提示工程 + 上下文注入”,将私域知识作为参考信息传入 prompt
- 示例:
defanswer_private_question(private_knowledge: str, user_question: str) -> str:
prompt = f"""基于以下私域知识回答问题:
{private_knowledge}
用户问题:{user_question}
要求:仅使用上述知识回答,不添加外部信息,若无法回答请说明。
"""
return get_gpt_response(prompt)
# 调用示例(注入公司产品知识)
product_knowledge = "公司X的A产品采用32位MCU,续航时间120小时,支持蓝牙5.0"
result = answer_private_question(product_knowledge, "A产品的续航时间是多少?")
路径 2:改变模型(高成本长期方案)
- 方法 1:模型微调(Fine-tuning):用私域数据训练模型,让模型 “记住” 特定知识(适合数据量中等的场景,如 1000~10 万条数据)
- 方法 2:训练专属模型:基于开源模型(如 Llama 3、Qwen-7B),用私域数据从头 / 增量训练(适合数据量极大、对模型定制化要求高的场景)
大模型开发环境搭建与 API 配置
核心开发环境要求
- 编程语言:推荐 Python 3.8+(生态完善,OpenAI / 通义千问等 API 均提供官方 Python SDK)
- 依赖库:
openai:OpenAI 官方 SDK,用于调用 GPT 系列模型python-dotenv:安全管理环境变量,避免 API Key 泄露requests:若需自定义 API 请求,用于发送 HTTP 请求streamlit/fastapi(可选):快速搭建大模型应用前端 / 后端
API Key 安全管理(关键操作)
错误做法:直接硬编码 API Key,因为这样很容易在分享代码时泄露密钥
# 风险示例:直接在代码中写入API Key,分享代码时易泄露
import openai
openai.api_key = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"# 高危操作!
正确做法:通过环境变量加载
创建.env 配置文件:在项目根目录新建.env文件,存储 API Key,如下:
# .env文件内容(添加到.gitignore,禁止提交到代码仓库)
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
QWEN_API_KEY=sk-yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy
通过 python-dotenv 加载API Key示例:
# 安全加载API Key示例
import os
from dotenv import load_dotenv
import openai
# 加载.env文件中的环境变量
load_dotenv() # 自动读取项目根目录的.env文件
# 从环境变量中获取API Key
openai.api_key = os.getenv("OPENAI_API_KEY")
# 验证API Key是否加载成功
ifnot openai.api_key:
raise ValueError("API Key加载失败,请检查.env文件是否正确配置")
大模型API 调用与参数优化
基础 API 调用流程(以 OpenAI GPT-3.5/4 为例)
非流式调用(完整结果返回)
适用于对响应速度要求不高,需获取完整回答的场景(如文档生成、数据分析):
defget_gpt_response(prompt: str) -> str:
"""非流式调用GPT-3.5,获取完整回答"""
try:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo", # 模型名称,可选gpt-4
messages=[
{"role": "system", "content": "你是专业的技术助手,回答需简洁准确"},
{"role": "user", "content": prompt}
],
max_tokens=1024, # 最大输出长度(含输入tokens)
temperature=0.7# 控制随机性,0.7为平衡值
)
# 提取回答内容
return response.choices[0].message["content"].strip()
except Exception as e:
returnf"API调用失败:{str(e)}"
# 调用示例
result = get_gpt_response("请解释大模型的tokenization过程")
print(result)
流式调用(实时返回结果)
适用于对话机器人、实时问答等场景,提升用户体验(避免长时间等待):
defstream_gpt_response(prompt: str):
"""流式调用GPT-3.5,实时返回回答片段"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是实时对话助手,逐句返回回答"},
{"role": "user", "content": prompt}
],
stream=True, # 开启流式输出
temperature=0.5
)
# 逐段处理流式响应
full_response = ""
print("流式输出结果:")
for chunk in response:
# 提取当前片段内容(忽略空片段)
chunk_content = chunk.choices[0].delta.get("content", "")
if chunk_content:
print(chunk_content, end="", flush=True) # 实时打印
full_response += chunk_content
return full_response
# 调用示例
stream_gpt_response("请分步说明大模型推理的核心步骤")
实践案例:快速搭建一个大模型对话助手
基于 Streamlit 和 OpenAI API,10 分钟实现一个 Web 版对话助手:
步骤 1:安装依赖
pip install streamlit openai python-dotenv
步骤 2:编写代码(app.py)
import streamlit as st
import openai
import os
from dotenv import load_dotenv
# 加载API Key
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# 页面配置
st.set_page_config(page_title="大模型对话助手", page_icon="💬")
st.title("💬 大模型对话助手")
# 初始化会话状态(存储对话历史)
if"messages"notin st.session_state:
st.session_state.messages = [
{"role": "system", "content": "你是友好的对话助手,回答简洁易懂"}
]
# 显示对话历史
for message in st.session_state.messages[1:]: # 跳过system消息
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 处理用户输入
if prompt := st.chat_input("请输入你的问题..."):
# 添加用户消息到会话状态
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# 调用OpenAI API获取回答(流式输出)
with st.chat_message("assistant"):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=st.session_state.messages,
stream=True
)
# 实时显示回答
full_response = st.write_stream(response)
# 添加助手消息到会话状态
st.session_state.messages.append({"role": "assistant", "content": full_response})
步骤 3:运行应用
streamlit run app.py
运行后会自动打开浏览器,输入问题即可与大模型对话(支持流式实时输出)
六、提升应用稳定性与用户体验
- 错误处理:添加 API 调用超时、额度不足、网络异常等场景的捕获(用 try-except 包裹 API 调用代码)
- 限流控制:若面向多用户,添加接口调用频率限制(如每用户每分钟最多 10 次调用)
- 成本优化:
- 选择合适的模型(如非关键场景用 GPT-3.5 替代 GPT-4,降低 token 成本)
- 控制
max_tokens,避免生成过长内容(根据需求设置合理阈值)
- 隐私保护:若处理用户敏感数据,需对输入内容进行脱敏(如替换手机号、邮箱等信息)
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 1918
1918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









