



LLM、RAG、Agent:AI从业者必懂的三层栈指南
首先声明:这不是纸上谈兵的概念科普,而是基于国内产品落地的实战笔记!如果你正在做AI产品,这篇文章能帮你少走不少弯路。
先说结论
很多人把 LLM、RAG、Agent 看成三个竞争选项,或者是三选一 or 三选二的选项,而实际上,它们是同一个AI系统的三个能力层:
① LLM 是大脑
② RAG 是记忆
③ Agent 是”行动“,也就是决策和执行系统
生产级AI产品的标准做法是:按需叠加。不是"选一个",而是根据场景的复杂度,逐层加上去。
第一层:LLM——最强大脑,但这个脑子是"冻结"的
LLM 的本质是什么?
LLM 最强的能力是意图理解 → 结构化生成,说人话就是:能听懂你的需求,还能用各种格式(文本、JSON、SQL、代码)给你吐出来。
LLM 的真实能力边界:
- 擅长的事:文案生成、代码辅助、逻辑推理、多轮对话、角色扮演、长文本理解
- 不擅长的事:实时信息(停留在训练数据的时间点,比如:你截一张股票的分时图发给deepseek,让它猜股票,你看它的推理过程,肯定是2024年的股票数据。所以顺带提醒各位,不要迷信AI炒股!)、专有数据(从没见过的企业内部文档)、数值计算(尤其是复杂四则运算)
国内产品案例:腾讯混元/deepseek + 微信
腾讯混元大模型在微信生态中的纯 LLM 应用场景很典型。比如你在微信里搜索"周末旅游的行程",搜索结果最顶部就是AI的回答↓(默认是混元,你也可以选择ds深度思考模型)
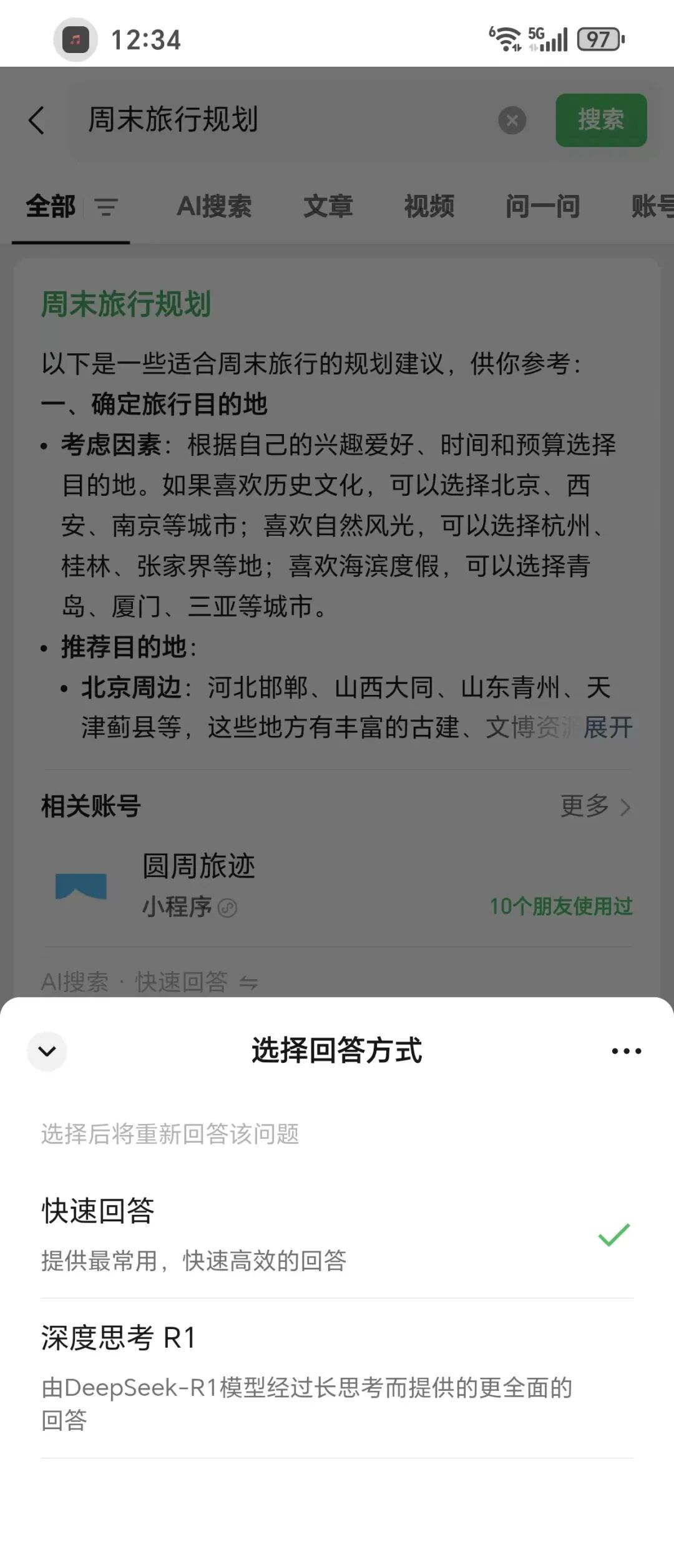
AI输出的计划虽然很详细,包括酒店推荐、景点顺序等,但是这个场景里只要有LLM就够了,完全**不需要 RAG,不需要 Agent。从它的回答你也能看的出来,它给出来的信息,没有那种实时的内容。**因为我只是需要一个信息输出作为参考,没有让它给我具体到时间、金钱、地点、出行方式等这样一个详细规划。
而且出于成本的考虑,微信也好,小红书也好,它们的内置搜索都集成了大模型能力,但是很少会调用RAG,更不用说Agent了。
因此即使你输入了详细的出行要求,默认的AI回答依然是LLM为主,他不会通过实时检索,关联最新的票价、路况、住宿费用等动态信息,你真要”新鲜有效的信息“,那就只能看下面最近发布的具体文章、笔记了。
所以LLM这个大脑很聪明,但它一旦涉及到一些新鲜信息,就会有一些脱节,因为它的学习”进度“跟当下这个时间点,是存在一定的时间差的。但是,这并不影响它是一个高手这个事实。
第二层:RAG——记忆,把"冻结的脑子"接上实时数据库
为什么需要 RAG?
这是最常见的场景:企业的 AI 客服系统不能每次都"胡说八道",用户问"你们产品保修期是多久",系统得从产品手册里查到真实答案再回答。
RAG(Retrieval-Augmented Generation)做的事就是:
- 把用户的问题转成"向量"(数值化表示)
- 到知识库(向量数据库)里找最相关的文档/信息
- 把这些文档作为"上下文",一起送给 LLM
- LLM 基于这些真实信息生成答案
流程简图
用户问题 ↓[向量化] ← 用Embedding模型 ↓[向量数据库检索] ← 找Top K相关文档 ↓[RAG上下文拼接] → "这是我们的产品手册,基于以下信息回答问题..." ↓[LLM生成答案] ← 带有引用出处 ↓用户 ✓ 得到准确、可验证的答案
产品案例:字节豆包 + 云搜索 RAG
字节跳动的豆包大模型内置了基于云搜索的百亿级向量检索能力。生产环境下,毫秒级召回,秒级索引更新。这意味着:
- 企业把最新的产品文档、政策手册导入
- 用户随时问,豆包都能查出最新信息
- 不需要每次人工更新 FAQ
典型场景:保险代理的知识库。某保险公司用豆包+RAG,自动生成产品解释和销售话术,人均提效 50%。
RAG 的关键工程细节
做好 RAG 系统,最常见的坑:
| 问题 | 常见错误 | 正确做法 |
|---|---|---|
| 检索不准 | 用的 Embedding 模型太烂,把"保修期"和"维修费"混为一谈 | 用领域特定的 Embedding 或做微调,必要时用混合检索(BM25 + 向量) |
| 幻觉依然高 | 把相关文档 dump 进去,LLM 还是随意编 | 用"Chain-of-Thought"让 LLM 先列出依据,再生成答案 |
| 数据不新 | 只更新了 RAG 库,没同步到向量索引 | 自动化索引更新,或定期全量重建向量库 |
| 成本爆表 | 每个请求都检索 Top 100 文档 | 分层检索(先快速粗筛,再精排),设置文档数量上限 |
第三层:Agent——手脚和自主决策系统
LLM + RAG 的天花板
还是周末游的例子,你这么问AI,即使是LLM+RAG也解决不:
“帮我规划个周末上海两日游,包括订酒店、订餐厅、规划路线,最后给我一份PDF”
这个需求涉及:
- 查询事实景点信息库(用 RAG)
- 调用酒店推荐和预订接口
- 调用餐厅推荐和预订接口
- 生成 PDF 并发送
- 如果酒店没房了,自动重试其他酒店
纯 LLM + RAG 做不到这些,因为 LLM 不会"真正去做"这些事,只会生成一个todolist。
而”做“,Do这个动作,就是 Agent 的精髓和它的用武之地了。
Agent 的工作流程简图
用户意图 ↓[意图解析] ← LLM理解"我要订酒店+订餐厅" ↓[规划] ← 拆分成步骤序列 ↓[调用工具1] ← 查酒店库 → 得到候选列表 ↓[反思] ← "酒店太贵?需要换条件吗?"(这一步很关键!) ↓[调用工具2] ← 调用预订接口 → 完成预订 ↓[调用工具3] ← 推荐餐厅 → 返回名单 ↓[最终执行] ← 生成行程单,发送 PDF ↓[结束] 或 [需要改进?回到反思步骤]
这里面最关键的是"反思环"!因为我们都知道大模型是存在幻觉的,如果你赋予了大模型”做“这个权利,那么,整个流程里面,一步错,可能后面就步步错了!
所以,Agent 在每一步之后都要问自己"我做对了吗?是否偏离原始目标?需要改策略吗?"。没有这个循环,Agent 很大概率会一条路走到黑!
产品案例:阿里飞猪旅行 Agent
荣耀新发布的手机,AI智能助理集成了飞猪旅行 Agent。所以用户跟手机说"帮我规划三天xx出行计划"后,语音助理初步识别后就会调用Agent,然后后续跟用户的交互流程大概是这样:
- 意图理解:识别出"旅行规划+需要预订"
- 信息收集:问用户"预算多少?几个人?什么时间?出行方式?…"
- 多源查询:同时查景点库、酒店库、航班库…
- 智能过滤:基于用户预算+评分,自动筛选最优组合
- 一键预订:用户确认后,Agent 调用支付接口完成预订
- 反思检查:预订成功?如果失败,自动选择备选方案
整个流程中,Agent 不只是"建议",而是真实地"代理执行"了用户的意愿。所以在这一类场景中,Agent 在整个思考过程中,会基于用户需求做多次相关外部数据源的联动和决策,这是LLM或LLM+RAG 所不具备的能力。
⭐️关键决策:什么时候用哪一层?
决策树
用户问题来了 ↓问题是"纯语言处理"吗? ├─ YES → 只用 LLM ✓ │ 例子:写文案、改邮件、翻译、总结 │ └─ NO ↓ 需要准确的、可核查的事实吗? ├─ YES → LLM + RAG ✓ │ 例子:产品问答、政策查询、文档QA、知识库问答 │ └─ NO ↓ 需要跨多步执行、调用外部系统、最后产出实际结果吗? ├─ YES → LLM + RAG + Agent ✓✓✓ │ 例子:旅行规划、订单处理、自动化工作流、智能客服 │ └─ NO → 可能不需要 AI...
举个例子: 大家都用deepseek会知道,现在这类ai助手工具基本都有一个”联网“的按钮,其实这就是RAG。就是这个功能打开后,它会根据我们问的问题,判断是否需要实时检索。 如果不需要,它就直接动一动自己这个LLM大脑,就直接回答你了。如果它发现你的问题涉及一些实时的数据或八卦、新闻什么的,那它就得借助RAG去联网搜索一下相关的网页等,最后把搜索结果给回LLM大脑,大脑综合这些信息后,再给你一个最终的答案。
延迟与准确度对比(仅供参考)
| 方案 | 响应时间 | 准确率 | 复杂度 |
|---|---|---|---|
| 纯 LLM | <1秒 | 60-70% | 低 ⭐ |
| LLM + RAG | 1-3秒 | 85-95% | 中 ⭐⭐ |
| LLM + RAG + Agent | 3-10秒(多步) | 70-90%* | 高 ⭐⭐⭐ |
*准确率取决于工具调用的成功率和反思机制的质量
工程实现的三个痛点与解决方案
痛点 1:向量检索的"语义漂移"
问题:用户问"手机屏幕碎了怎么修",系统检索出了"屏幕保护膜怎么贴"的文档。
原因:Embedding 模型没有理解"修"和"贴"的本质区别。
解决方案:
- 用国产的中文 Embedding 模型,而不是通用英文模型
- 对关键领域词做"同义词扩展":修 = 维修/修理/返修
- 用混合检索:BM25(精确词匹配)+ 向量(语义匹配)
痛点 2:Agent 的"死循环"
问题:Agent 陷入无限重试,一直在重复调用同一个失败的接口。
解决方案:
- 设置最大步数限制(比如最多 10 步)
- 每次失败后,强制 Agent"反思为什么失败",然后改策略
- 设置"降级策略":如果智能流程失败,直接转人工
- 记录失败案例,定期做 Agent 的"微调"
痛点 3:长尾问题的"超预期成本"
问题:99% 的用户问题用 LLM 或 RAG 解决,但剩下 1% 的奇葩问题,Agent 要调用 10 个接口才能搞定,成本爆表。
解决方案:
- 用"分层策略":先用便宜的 LLM 试试,不行再上 RAG,最后才激活 Agent
- 对频繁出现的"长尾",做专项优化(比如常见的 5 个奇葩场景)
- 一旦 Agent 成本超过"转人工"的阈值,立即转人工处理
给产品经理的五条军规
1. 不要一开始就想搞 Agent
很多团队看到 Agent 的酷炫效果,就想一步到位。结果投入 3 个月工程资源,最后 Agent 的成功率只有 50%,不如简单的 RAG。
正确做法:用"功能演进"的思路,从 LLM → RAG → Agent 逐层加。每一层都要有明确的用户价值验证。
2. RAG 的效果取决于知识库质量,不是 Embedding 模型
很多团队觉得"用了高端 Embedding 模型就能解决问题"。实际上,50% 的效果来自数据准备,40% 来自 Embedding,10% 来自模型选择。
正确做法:投入人力做好知识库的清洗、分类、去重,比盲目升级模型有效 10 倍。
3. 别忘了"反思循环"
Agent 之所以比 RAG 强,核心在于有"反思"能力。用 LangGraph 等框架,把"检查→纠正→继续"的循环固化到系统里。
代码示例(伪代码):
while step < MAX_STEPS: # 执行当前任务 result = call_tool(task) # 反思(这是关键!) reflection = llm.reflect(original_goal, step, result) if reflection.is_complete(): return result elif reflection.needs_correction(): task = reflection.corrected_task step += 1 else: # 失败或需要人工 return escalate_to_human(task)
4. 用"分层定价"而不是"统一定价"
如果你的 AI 服务要商业化,不要所有功能都一个价格。应该是:
- 纯文本生成:¥0.99/次
- 文档问答(RAG):¥4.99/次或订阅制
- 复杂工作流(Agent):¥19.99/次或按工作流长度计费
这样既能覆盖成本,又不会把用户吓跑。
5. 质检和反馈循环不能少
90% 的 AI 产品失败,不是因为模型选错了,而是因为做完了就不管了,没有后续的用户反馈循环。
必须建立的机制:
- 用户反馈(点赞/点踩)
- 定期标注 10-20% 的输出结果,评估质量
- 每月根据反馈做 1-2 次的模型或 prompt 调优
- 记录失败案例,每个季度做一次大的系统优化
最后的话
LLM、RAG、Agent 的本质,是在解决 AI 系统的"三个维度的问题":
- LLM 解决的是"理解与表达"
- RAG 解决的是"准确性与可信度"
- Agent 解决的是"自主执行与流程复杂度"
没有绝对的好坏,只有"用对场景"的差别。
一个 MVP 可能只需要 LLM;一个成熟的企业应用需要 LLM + RAG;而一个要真正替代人工的系统,才需要全套的 LLM + RAG + Agent。
开发一个 AI 产品前,先问自己三个问题:
- 用户的问题是"需要创意",还是"需要事实",还是"需要真实执行"?
- 我团队有多少人?投入周期是多少?
- 如果这个 AI 失败了会带来什么后果?
答好这三个问题,你就知道该用哪一层了。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









