



现代 AI 聊天机器人常常依赖 Retrieval-Augmented Generation (RAG),也就是检索增强生成技术。这种技术让机器人能从外部数据中提取真实信息来支撑回答。如果你用过“与你的文档聊天”之类的工具,你就见过 RAG 的实际应用:系统会从文档中找到相关片段,喂给大语言模型(LLM),让它能用准确的信息回答你的问题。
RAG 大大提升了 LLM 回答的事实准确性。不过,传统 RAG 系统大多把知识看成一堆互不关联的文本片段。LLM 拿到几段相关内容后,得自己把它们拼凑起来回答。这种方式对简单问题还行,但遇到需要跨多个来源串联信息的复杂查询,效果就不理想了。
这篇文章会深入浅出地解释两个能让聊天机器人更上一层楼的概念:ontologies(本体论) 和 knowledge graphs(知识图谱),以及它们如何与 RAG 结合,形成 GraphRAG(基于图的检索增强生成)。我们会用简单的语言说明它们是什么,为什么重要。
为什么这很重要?你可能会问。因为 GraphRAG 能让聊天机器人的回答更准确、更贴合上下文、更有洞察力,比传统 RAG 强多了。企业在探索 AI 解决方案时很看重这些特质——一个真正理解上下文、避免错误、能处理复杂问题的 AI 可以彻底改变游戏规则。(不过,这需要完美的实现,实际中往往没那么理想。)
通过把非结构化文本和结构化的知识图谱结合起来,GraphRAG 系统能提供感觉上更“有学问”的回答。把知识图谱和 LLM 结合起来,是让 AI 不仅能检索信息,还能真正理解信息的关键一步。
什么是 RAG?
Retrieval-Augmented Generation,简称 RAG,是一种通过外部知识来增强语言模型回答的技术。RAG 系统不是仅靠模型记忆里的东西(可能过时或不完整)来回答,而是会从外部来源(比如文档、数据库或网络)抓取相关信息,喂给模型来帮助生成答案。
简单来说,RAG = LLM + 搜索引擎:模型先检索支持数据,增强对主题的理解,然后结合内置知识和检索到的信息生成回答。
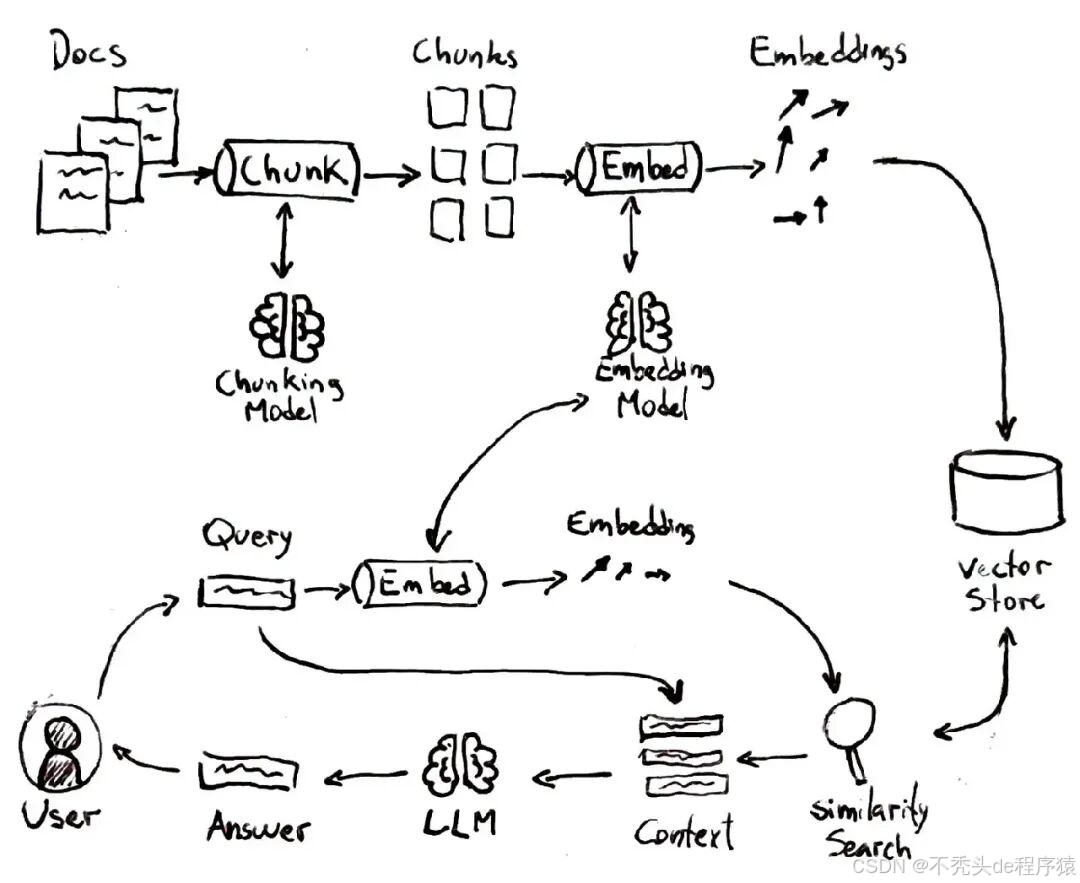

如上图所示,典型的 RAG 流程包含几个步骤,就像一个智能查找过程:
-
- 索引知识:系统先把知识来源(比如一堆文档)分成小块文本,为每块生成 vector embeddings(向量嵌入)。这些嵌入是文本含义的数字表示,存进一个向量数据库或索引中。
-
- 查询嵌入:用户提出问题时,查询也会用同样的技术转成向量嵌入。
-
- 相似性搜索:系统把查询向量和存储的向量对比,找出与问题最“相似”或相关的文本块。
-
- 结合上下文生成:最后,语言模型拿到用户问题和检索到的文本片段作为上下文,生成包含这些信息的回答。
RAG 让 LLM 在现实场景中变得更实用。像 Bing Chat 或各种文档问答机器人就是靠 RAG 提供最新、具体的答案,还能附上参考资料。通过用检索到的文本来“锚定”回答,RAG 减少了 hallucinations(模型瞎编),还能访问超出 AI 训练截止日期的信息。不过,传统 RAG 也有一些明显的局限:
- • 它把检索到的文档基本上当作独立的、非结构化的文本块。如果回答需要综合多个文档的信息或理解它们之间的关系,模型得在生成时自己完成这个重活。
- • RAG 的检索通常基于 semantic similarity(语义相似性)。它能找到相关段落,但不一定理解内容的真正含义,或者一个事实如何与另一个事实关联。
- • 没有内置机制来推理或确保检索数据的一致性;LLM 只是拿到一堆文本,尽力把它们串起来。
在实际中,对于简单的事实查询,比如“这家公司什么时候成立的?”,传统 RAG 表现很好。但对于复杂问题,比如“比较第一季度销售和营销支出的趋势,并找出相关性”,传统 RAG 就可能掉链子。它可能返回一段关于销售的文本,另一段关于营销的,但逻辑整合得靠 LLM 自己来,可能不一定能连贯成功。
这些局限性指向一个机会。如果我们不只是给 AI 一堆文档,而是再给它一个 knowledge graph(知识图谱),也就是实体和它们关系的网络,作为推理的框架呢?如果 RAG 检索不只是基于相似性返回文本,而是返回一组相互关联的事实,AI 就能顺着这些联系生成更有洞察力的回答。
GraphRAG 就是把基于图的知识整合进 RAG 流程。通过这样做,我们希望解决上面提到的多来源、歧义和推理问题。
在深入 GraphRAG 的工作原理之前,我们先搞清楚 knowledge graphs(知识图谱) 和 ontologies(本体论) 是什么——它们是这种方法的基础。
知识图谱(Knowledge Graphs)
知识图谱 是一种对现实世界知识的网络化表示,图中的每个 node(节点) 代表一个实体,每条 edge(边) 代表实体间的关系。
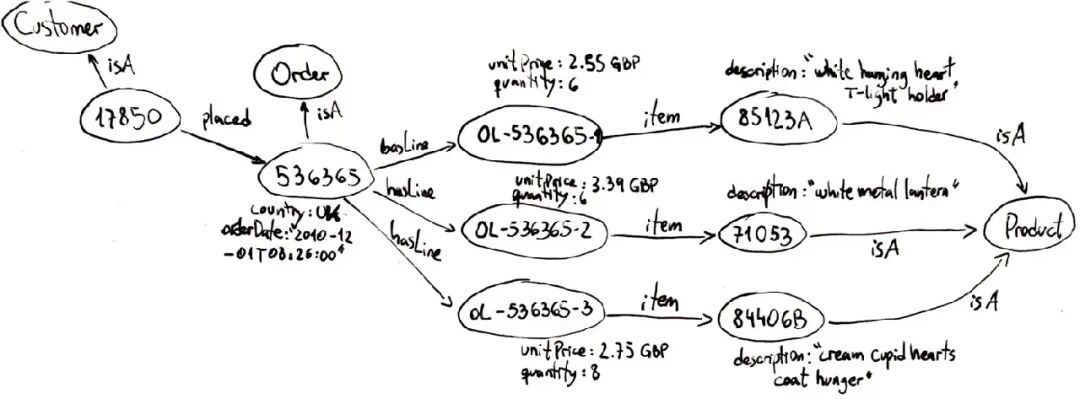
如上图所示,知识图谱以图的形式组织数据,而不是表格或孤立的文档。这意味着信息天然就捕捉了联系。一些关键特点:
- • 灵活性:你可以随时添加新的关系类型或实体的属性,不会搞乱整个系统。图可以轻松扩展以适应新知识。
- • 语义化:每条边都有含义,这让沿着图遍历并提取有意义的推理链成为可能。图不仅能表示内容,还能表示上下文。
- • 支持多跳查询:如果你想知道两个实体如何关联,图数据库可以遍历邻居、邻居的邻居,依此类推。
知识图谱通常存储在专门的 graph databases(图数据库) 或 triplestores(三元存储) 中。这些系统专为存储节点和边、运行图查询而优化。
知识图谱的结构对 AI 系统(尤其在 RAG 场景中)是个大加分项。因为事实是相互关联的,LLM 能拿到一整个相关信息的网络,而不是孤立的片段。这意味着:
- • AI 系统能更好地消除歧义。比如,如果问题提到“Jaguar”,图可以通过关系明确是汽车还是动物,提供文本单独无法给出的上下文。
- • AI 系统可以通过“连接”或遍历收集相关事实。图查询可以提供一个全相关的子图,而不是零散的段落,为模型提供一个预先拼好的拼图,而不是单个碎片。
- • 知识图谱保证一致性。比如,如果图知道产品 X 包含部件 A 和 B,它就能可靠地只列出这些部件,不像文本模型可能会瞎编或漏掉信息。图的结构化特性让事实的聚合更完整、更准确。
- • 图通过追踪推理链的节点和边提供 explainability(可解释性),让推理过程清晰,增加答案的可信度。
总结来说,知识图谱为 AI 的上下文注入了意义。它不是把数据当一堆词袋处理,而是当作一个知识网络。这正是我们希望 AI 在回答复杂问题时拥有的:一个可以导航的、丰富的关联上下文,而不是每次都要硬解析一堆文档。
现在我们了解了知识图谱是什么,以及它如何助力 AI 系统,接下来看看 ontologies(本体论) 是什么,以及它们如何帮助构建更好的知识图谱。
本体论(Ontologies)
在知识系统的语境中,ontology(本体论) 是一个特定领域的知识的正式规范。它定义了该领域中存在的实体(或概念)以及这些实体之间的关系。
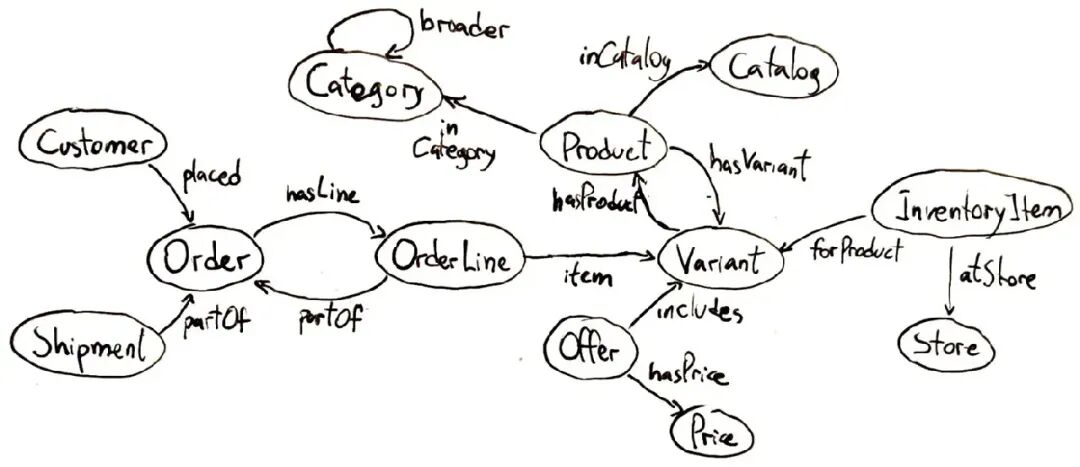
本体论通常将概念组织成层级或分类体系,但也可能包含逻辑约束或规则。比如,可以声明“每个订单必须至少包含一个产品项目”。
为什么本体论重要?你可能会问。本体论为一个领域提供了共享的理解,这在整合多个来源的数据或构建需要推理该领域的 AI 系统时特别有用。通过定义一组通用的实体类型和关系,本体论确保不同团队或系统用一致的方式指代事物。比如,如果一个数据集把人叫“Client”,另一个叫“Customer”,通过映射到同一个本体论类(比如 Customer 作为 Person 的子类),就能无缝合并这些数据。
在 AI 和 GraphRAG 的语境中,本体论是知识图谱的蓝图——它决定了图中会有哪些节点和链接。这对复杂推理至关重要。如果你的聊天机器人知道在你的应用中“Amazon”是一个 Company(公司)(而不是河流),而 Company 在本体论中有定义(包含 headquarters、CEO 等属性,以及 hasSubsidiary 等关系),它就能更精确地锚定答案。
现在我们了解了知识图谱和本体论,来看看如何把它们整合进类似 RAG 的流程中。
GraphRAG
GraphRAG 是传统 RAG 的进化版,它明确将知识图谱纳入检索过程。在 GraphRAG 中,用户提问时,系统不只是对文本做向量相似性搜索,还会查询知识图谱中相关的实体和关系。
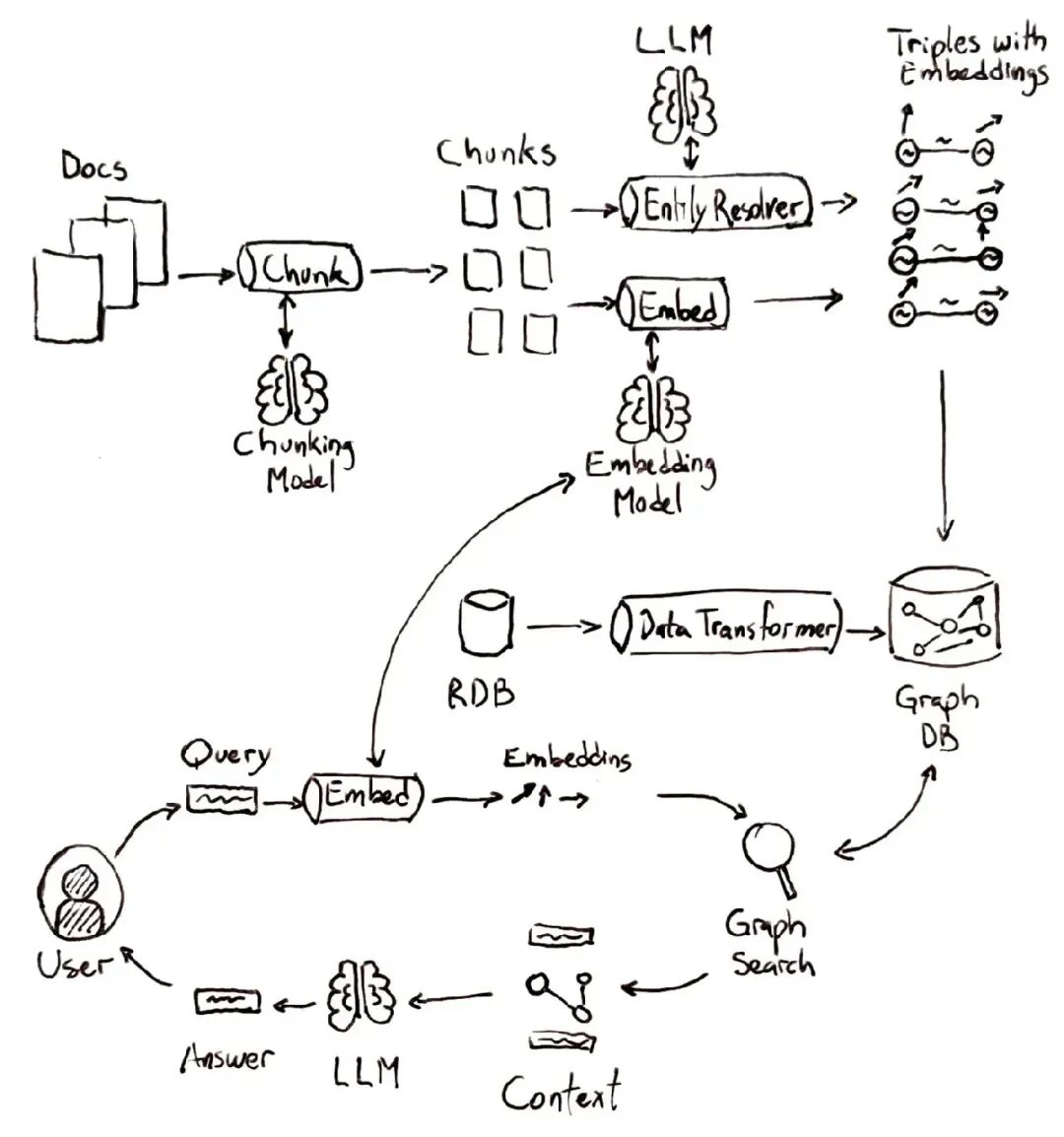
我们来高层次地走一遍典型的 GraphRAG 流程:
-
- 索引知识:输入包括结构化数据(比如数据库、CSV 文件)和非结构化数据(比如文档)。结构化数据通过数据转换,将表格行转为三元组。非结构化数据被拆成可管理的文本块,从中提取实体和关系,同时计算 embeddings(嵌入),生成带嵌入的三元组。
-
- 问题分析与嵌入:分析用户查询,识别关键术语或实体,用相同的嵌入模型将这些元素转为嵌入。
-
- 图搜索:系统查询知识图谱,找到与关键术语相关的节点,不只是检索语义相似的项目,还利用关系。
-
- 结合图上下文生成:生成模型使用用户查询和检索到的图增强上下文生成答案。
在底层,GraphRAG 可以用多种策略整合图查询。系统可能先做常规的语义搜索,找 top-K 文本块,然后遍历这些块的图邻居以收集额外上下文,再生成答案。这确保了即使相关信息分散在不同文档中,图也能把它们拉到一起。在实际中,GraphRAG 可能涉及额外步骤,比如 entity disambiguation(实体消歧)(确保问题中的“Apple”链接到正确的节点,可能是公司或水果)和图遍历算法来扩展上下文。但总体思路如上:搜索 + 图查询,而不只是搜索。
对非技术读者来说,你可以把 GraphRAG 想象成给 AI 增加了一个“类脑”知识网络,除了文档库之外。AI 不再孤立地读每本书(文档),而是有一本事实及其关联的百科全书。对技术读者来说,你可以想象一个架构,里面既有向量索引又有图数据库,两者协同工作——一个检索原始段落,另一个检索结构化事实,都喂进 LLM 的上下文窗口。
构建用于 RAG 的知识图谱:方法
构建支持 GraphRAG 系统的知识图谱有两种主要方法:Top-Down(自上而下) 和 Bottom-Up(自下而上)。它们不完全互斥(通常会混用),但区分它们有助于理解。
方法 1:自上而下(优先本体论)
自上而下的方法从定义领域的本体论开始,由领域专家或行业标准建立类、关系和规则。这个模式加载到图数据库中作为空的框架,指导数据提取和组织,相当于一个蓝图。
一旦本体论(模式)就位,接下来是用真实数据填充它。有几种子方法:
- • 使用结构化来源:如果你有现有的结构化数据库或 CSV 文件,就把它们映射到本体论。如果映射简单,可以通过自动化 ETL 工具将 SQL 表转为图数据。
- • 通过本体论从文本提取:对于非结构化数据(比如文档、PDF),你会用 NLP 技术,但以本体论为指导。这通常涉及编写提取规则或用 LLM 配合引用本体论术语的提示。
- • 手动或半手动整理:在关键领域,可能需要人工验证每个提取的三元组,或手动输入一些数据到图中,特别是一次性设置的关键知识。比如,公司可能手动输入组织架构或产品层级到图中,因为这些数据相对静态且非常重要。
关键在于,自上而下的方法中,本体论在每一步都起到指导作用。它告诉提取算法要找什么,确保输入的数据符合一个连贯的模型。
使用正式本体论的一大优势是你可以利用 reasoners(推理器) 和 validators(验证器) 保持知识图谱一致性。本体论推理器可以自动推断新事实或检查逻辑矛盾,而像 SHACL 这样的工具可以强制执行数据形状规则(类似更丰富的数据库模式)。这些检查能防止矛盾事实,并通过自动推导关系丰富图。在 GraphRAG 中,这意味着即使多跳连接不明确,本体论也能帮助推导出来。
方法 2:自下而上(数据优先)
自下而上的方法直接从数据生成知识图谱,不依赖预定义的模式。NLP 和 LLM 的进步让从非结构化文本中提取结构化三元组成为可能,这些三元组随后被输入图数据库,实体成为节点,关系成为边。
在底层,自下而上的提取可以结合传统 NLP 和现代 LLM:
- • Named Entity Recognition (NER,命名实体识别):识别文本中的人名、组织、地点等。
- • Relation Extraction (RE,关系提取):识别这些实体之间是否有提到的关系。
- • Coreference Resolution(共指消解):弄清楚段落中代词的指代对象,以便三元组使用完整名称。
有像 spaCy 或 Flair 这样的传统方法库,也有整合 LLM 调用的新库用于 IE(信息提取)。另外,像 ChatGPT 插件 或 LangChain 代理 这样的技术可以设置来填充图:代理可以逐个读取文档,找到事实时调用“图插入”工具。另一个有趣的策略是用 LLM 通过读取文档样本建议模式(这有点像本体论生成,但自下而上)。
自下而上提取的一个大问题是,LLM 可能不完美,甚至会“创造性”输出。它们可能瞎编一个不存在的关系,或错误标记一个实体。因此,验证很重要:
- • 对关键事实与源文本交叉检查。
- • 使用多轮提取:比如第一轮提取实体,第二轮验证和填充关系。
- • 人工抽查:让人审阅一部分提取的三元组,尤其是那些影响大的。
这个过程通常是迭代的。你运行提取,找到错误或缺失,调整提示或过滤器,再运行一次。久而久之,这能大幅提高知识图谱的质量。好消息是,即使有些错误,知识图谱对很多查询仍然有用——你可以优先清理对用例最重要的部分。
最后,记住,发送文本进行提取会将你的数据暴露给 LLM/服务,所以要确保符合隐私和保留要求。
GraphRAG 生态中的工具和框架
构建 GraphRAG 系统听起来可能有点复杂,你得管理向量数据库、图数据库、运行 LLM 提取流程等。好消息是,社区正在开发工具让这事变得更简单。我们来简单提一些工具和框架,以及它们的作用。
图存储
首先,你需要一个地方存储和查询知识图谱。传统的图数据库如 Neo4j、Amazon Neptune、TigerGraph 或 RDF triplestores(如 GraphDB 或 Stardog)是常见选择。
这些数据库专为我们讨论的操作优化:
- • 遍历关系
- • 查找邻居
- • 执行图查询
在 GraphRAG 设置中,检索流程可以用这些查询来获取相关的子图。一些向量数据库(像 Milvus 或带 Graph 插件的 Elasticsearch)也开始整合类图查询,但通常专用图数据库提供最丰富的功能。重要的是,你的图存储要能高效检索直接邻居和多跳邻居,因为复杂问题可能需要抓取整个事实网络。
新兴工具
一些新工具正在将图与 LLM 结合:
- • Cognee:一个开源的“AI 记忆引擎”,为 LLM 构建和使用知识图谱。它作为代理或聊天机器人的语义记忆层,将非结构化数据转为结构化的概念和关系图。LLM 能查询这些图以获得精确答案。Cognee 隐藏了图的复杂性:开发者只需提供数据,它就生成可查询的图。它与图数据库整合,提供数据摄取、图构建和 LLM 查询的流程。
- • Graphiti(由 Zep AI 提供):一个为需要实时、动态记忆的 AI 代理设计的框架。与许多静态数据的 RAG 系统不同,Graphiti 能在新信息到达时增量更新知识图谱。它存储事实及其时间上下文,使用 Neo4j 存储,提供面向代理的 API。与早期基于批处理的 GraphRAG 系统不同,Graphiti 能高效处理流式数据,适合持续学习的长期运行代理,确保答案始终反映最新数据。
- • 其他框架:像 LlamaIndex 和 Haystack 这样的工具添加了图模块,尽管不是以图优先。LlamaIndex 能从文档提取三元组并支持基于图的查询。Haystack 实验了整合图数据库来扩展问答功能,超越向量搜索。云服务商也在增加图功能:AWS Bedrock Knowledge Bases 支持 GraphRAG,通过托管摄取到 Neptune;Azure Cognitive Search 也与图整合。生态系统发展很快。
无需从头开始
重点是,如果你想尝试 GraphRAG,不用从零开始。你可以:
- • 用 Cognee 处理知识提取和图构建,省去自己写提示和解析逻辑的麻烦。
- • 如果需要即插即用的记忆图,尤其是对话或时间相关数据的代理,用 Graphiti。
- • 用 LlamaIndex 或其他工具,只需几行代码就能获得基本的知识图谱提取功能。
- • 依靠成熟的图数据库,省去写自定义图遍历引擎的麻烦。
总之,虽然 GraphRAG 处于前沿,但周边生态正在快速成长。你可以利用这些库和服务快速搭建原型,然后迭代优化知识图谱和提示。
结论
传统 RAG 适合简单的事实查询,但在需要深入推理、准确性或多步回答的查询上会吃力。这时 GraphRAG 就大显身手了。通过结合文档和知识图谱,它用结构化事实锚定回答,减少 hallucinations(瞎编),支持多跳推理,让 AI 能以标准 RAG 无法做到的方式连接和综合信息。
当然,这种能力也有代价。构建和维护知识图谱需要模式设计、提取、更新和基础设施开销。对于简单用例,传统 RAG 仍是更简单高效的选择。但当需要更丰富的回答、一致性或 explainability(可解释性) 时,GraphRAG 的优势显而易见。
展望未来,知识增强的 AI 正在快速发展。未来平台可能直接从文档自动生成图,LLM 直接在图上推理。对于像 GoodData 这样的公司,GraphRAG 将 AI 与分析结合,带来超越“发生了什么”到“为什么发生”的洞察。
最终,GraphRAG 让我们更接近于不仅能检索事实,还能真正理解和推理事实的 AI,就像人类分析师,但规模和速度更大。虽然这条路有复杂性,但目标(更准确、可解释、更有洞察力的 AI)绝对值得投资。关键不仅在于收集事实,而在于连接它们。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 19
19

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









