



大型语言模型 (LLM) 架构大比拼
看到一个看到个写得非常好的文章——大型 LLM 架构对比,文中列举了 llama-3.2, Qwen3-4B, SmolLM3-3B, DeepSeek-V3, Qwen3-235B-A22B, Kimi-K2 的架构并详细探讨了他们的区别和优势。在学习大模型的同学建议读一读!
英文文章:https://sebastianraschka.com/blog/2025/the-big-llm-architecture-comparison.html
距离最初的 GPT 架构问世已七年有余。乍看之下,从 2019年的 GPT-2 到展望 2024-2025 年的 DeepSeek-V3 和 Llama 4,人们可能会惊讶于这些模型在结构上依然保持着高度的相似性。
当然,位置嵌入(positional embeddings)已从绝对位置编码(absolute positional encoding)演变为旋转位置嵌入 (RoPE),多头注意力(Multi-Head Attention, MHA)也大体被分组查询注意力(Grouped-QueryAttention, GQA)所取代,而更高效的 SwiGLU 激活函数替换了 GELU 等。但这些细微的改进之下,我们是真正看到了突破性的变革,还是仅仅在原有架构基础上进行打磨呢?
要比较不同的 LLM,找出影响其性能(无论是好是坏)的关键因素极具挑战性:数据集、训练技术和超参数差异巨大,而且往往缺乏详细记录。
然而,我认为深入研究架构本身的结构变化,以了解 LLM 开发者在 2025 年的最新动态,仍然具有重要价值(部分架构如图 1 所示)。
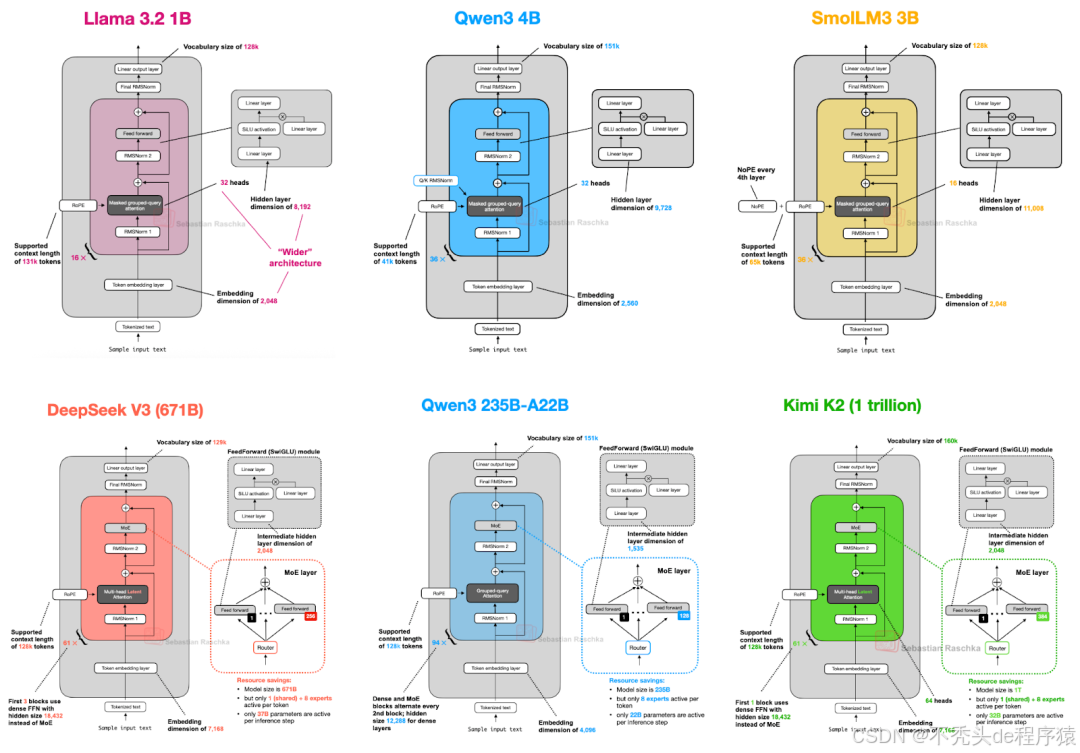
图 1:本文涵盖的部分架构。
因此,在本文中,作者将不探讨基准性能或训练算法,而是重点关注当前主流开源模型在架构上的发展。
目录
-
- DeepSeek V3/R1
- 1.1 多头潜在注意力 (MLA)
- 1.2 专家混合 (MoE)
- 1.3 DeepSeek 总结
-
- OLMo 2
- 2.1 归一化层的位置
-
2.2 QK-范数 (QK-Norm)
-
2.3 OLMo 2 总结
-
- Gemma 3
- 3.1 滑动窗口注意力
- 3.2 Gemma 3 中的归一化层放置
- 3.3 Gemma 3总结
- 3.4 Gemma 3n
-
- Mistral Small 3.1
-
- Llama 4
-
- Qwen3
- 6.1 Qwen3 (密集模型)
- 6.2 Qwen3 (MoE)
-
7.SmolLM3
- 7.1 无位置嵌入 (NoPE)
-
- Kimi 2
1. DeepSeek V3/R1
您可能已经多次听说,DeepSeek R1 于 2025 年 1 月发布时引起了巨大反响。DeepSeek R1 是一个基于 DeepSeek V3 架构 构建的推理模型,该架构于 2024 年 12 月问世。
尽管本文的重点是 2025 年发布的架构,但作者认为将 DeepSeek V3纳入其中是合理的,因为它是伴随 2025 年 DeepSeek R1 的发布才获得广泛关注和应用的。
如果您对 DeepSeek R1 的具体训练过程感兴趣,您可能会发现作者今年早些时候撰写的 一篇关于深度理解推理 LLM 的文章 会有所帮助。
本节中,作者将重点介绍 DeepSeek V3中引入的两个关键架构技术,它们提高了计算效率并使其不同于许多其他 LLM:
- 多头潜在注意力(Multi-Head Latent Attention, MLA)
- 专家混合(Mixture-of-Experts, MoE)
1.1 多头潜在注意力 (MLA)
在讨论多头潜在注意力 (MLA) 之前,我们先简要回顾一下相关的背景知识,以了解其应用动机。为此,我们从分组查询注意力 (GQA) 说起,近年来,GQA 已成为多头注意力 (MHA) 的一种新型标准替代方案,因为它在计算和参数效率上更胜一筹。
GQA 的核心思想可以简要概括如下:与 MHA 中每个注意力头都有自己独立的键(key)和值(value)不同,为了减少内存占用,GQA 将多个查询头分组,使其共享同一组键和值投影。
例如,如图 2 所示,如果存在 2 个键值组和 4 个注意力头,那么注意力头 1 和 2 可能共享一组键值,而注意力头 3 和 4 共享另一组。这减少了键值计算的总量,从而降低了内存使用并提高了效率(根据消融研究,对模型性能没有显著影响)。
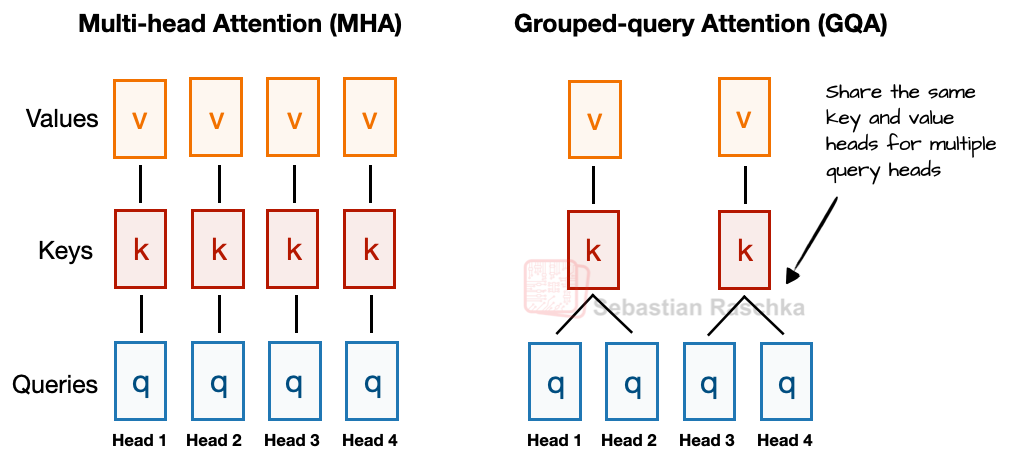
图 2:MHA 和 GQA 的比较。这里,分组大小为 2,这意味着一个键值对由 2 个查询共享。
因此,GQA 的核心思想是通过让多个查询头共享键(key)和值(value)来减少键值头的数量。这不仅(1)降低了模型的参数数量,而且(2)减少了推理时键值张量(tensor)的内存带宽使用,因为需要存储和从 KV 缓存中检索的键值更少。
(如果您对 GQA 的代码实现感兴趣,可以查看作者的 GPT-2 到 Llama 3 转换指南,其中包含一个不带 KV 缓存的版本;带 KV 缓存的版本则可在此处查看:这里。)
尽管 GQA 主要是一种弥补 MHA 计算效率不足的变通方法,但消融研究(例如 GQA 原论文 和 Llama 2 论文 中的研究)表明,它在 LLM 建模性能方面与标准 MHA 表现相当。
现在,多头潜在注意力 (MLA) 提出了一种不同的内存节省策略,该策略特别适用于 KV 缓存。与 GQA 共享键(key)和值(value)头不同,MLA 在将键和值张量存储到 KV 缓存之前,将其压缩到较低维度的空间中。
在推理时,这些压缩后的张量会先被恢复到原始大小,然后才能被使用,如图 3 所示。这虽然增加了额外的矩阵乘法运算,但显著减少了内存占用。
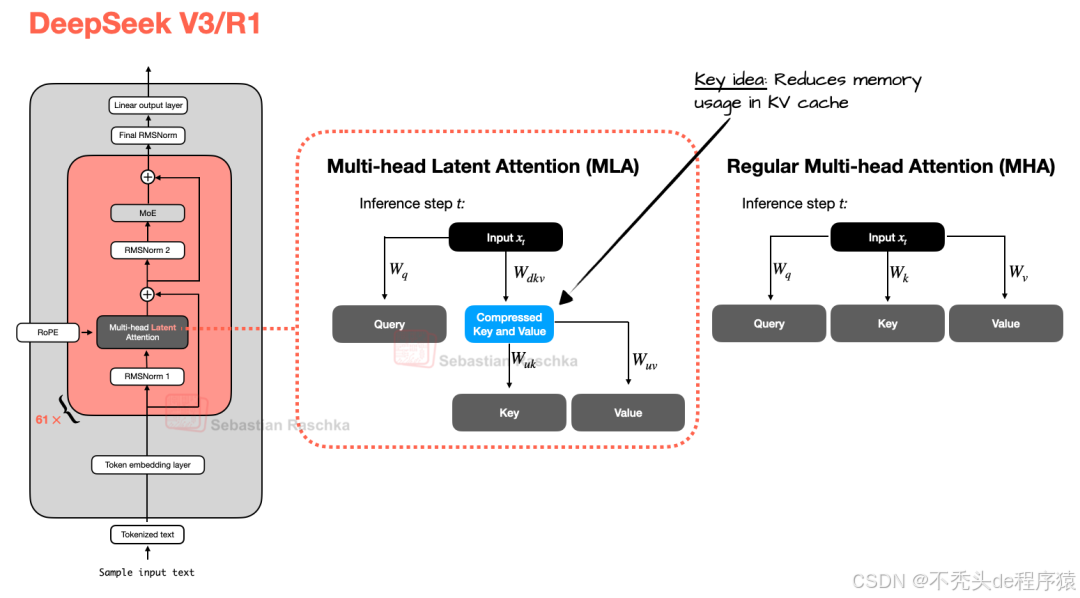
图 3:MLA(DeepSeek V3 和 R1 中使用)与常规 MHA 的比较。
(顺便提一下,查询(Queries)也会被压缩,但仅在训练期间,而非推理期间。)
此外,MLA 并非 DeepSeek V3 中的新内容,其 DeepSeek-V2 前身 也曾使用(甚至首次引入)该技术。V2 论文还包含了一些有趣的消融研究,这或许能解释 DeepSeek 团队为何选择 MLA 而非 GQA(参见图 4)。
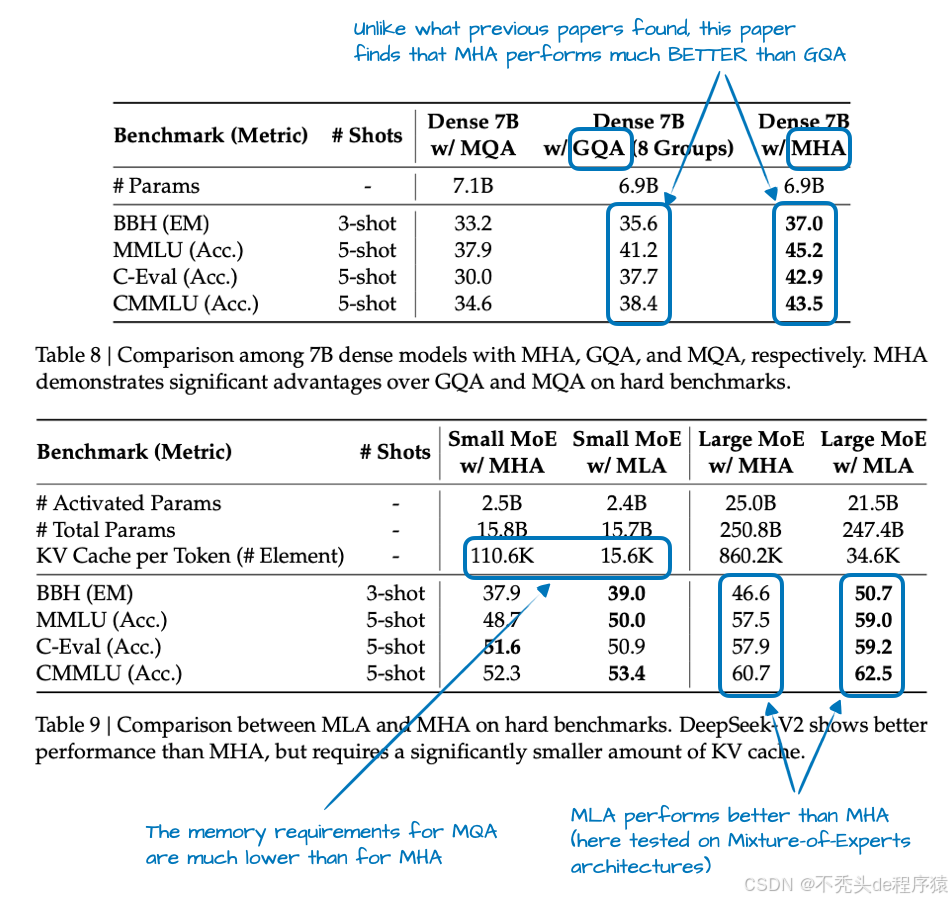
图 4:DeepSeek-V2 论文中的标注表格,https://arxiv.org/abs/2405.04434
如图4 所示,GQA 的性能似乎不如 MHA,而 MLA 在模型性能方面优于 MHA,这很可能是 DeepSeek 团队选择 MLA 而非 GQA 的原因。(如果能看到 MLA 和 GQA之间“每词元 KV 缓存”的节省量比较,那会更有趣!)
在进入下一个架构组件之前,我们总结一下本节:MLA 是一种巧妙的技巧,既能减少 KV 缓存内存使用,又能在模型性能方面略微优于 MHA。
1.2 专家混合 (MoE)
DeepSeek 中另一个值得关注的主要架构组件是其专家混合(MoE)层的应用。尽管 MoE 并非 DeepSeek 的独创,但它在今年重新流行起来,我们之后会讨论的许多模型也采用了这种方法。
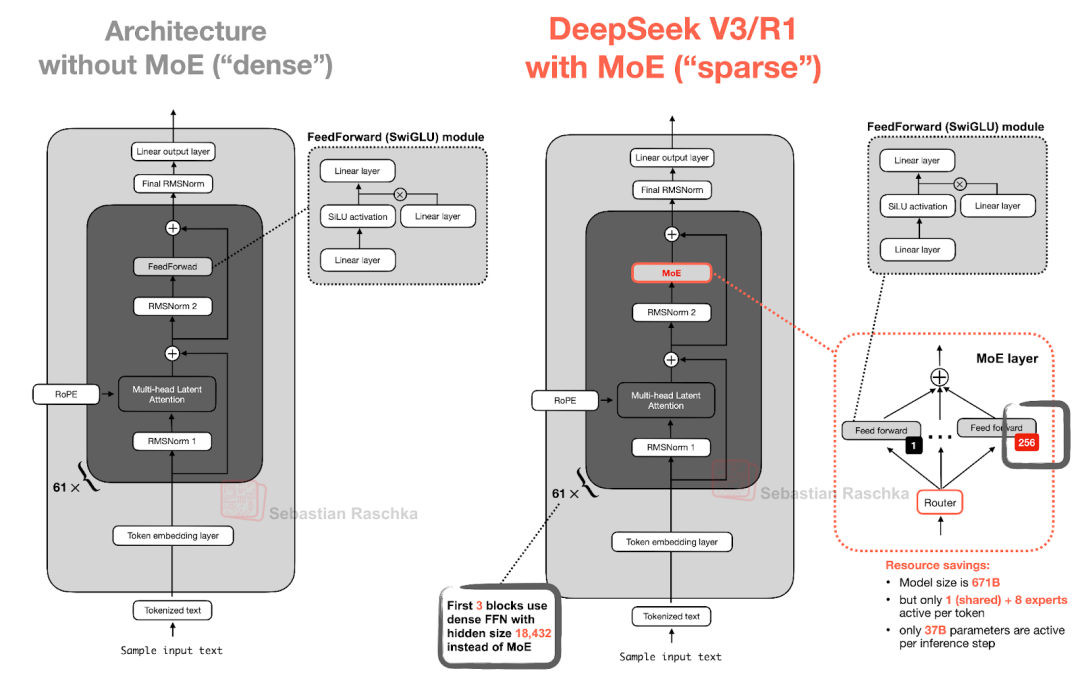
您可能已经熟悉 MoE 了,但快速回顾一下可能仍有帮助。MoE 的核心思想是用多个专家层替换 Transformer 块中的每个前馈神经网络(FeedForward)模块,其中每个专家层也都是一个前馈神经网络模块。这意味着我们将单个前馈层替换为多个前馈层,如图5 所示。
 img
img
图 5:DeepSeek V3/R1 中的专家混合 (MoE) 模块(右)与使用标准前馈块的 LLM(左)的示意图。
Transformer 块内部的前馈神经网络(图中深灰色模块)通常包含模型总参数的很大一部分。(请注意,Transformer 块以及前馈神经网络在 LLM 中会重复很多次;在 DeepSeek-V3 中,重复了 61 次。)
因此,将单个前馈块替换为多个前馈块(如 MoE 设置中所做)会大幅增加模型的总参数数量。然而,其中的关键技巧在于,我们不会为每个词元都使用(“激活”)所有专家。相反,一个路由机制会为每个词元选择一小部分专家。(为节省时间,或者说文章篇幅,作者会在以后更详细地介绍路由策略。)
由于一次只激活少数专家,MoE 模块通常被称为稀疏模块,与始终使用全部参数集的密集模块形成对比。然而,MoE 通过大量参数增加了 LLM 的容量,这意味着它在训练期间可以吸收更多的知识。稀疏性则保持了推理效率,因为我们不会同时使用所有参数。
例如,DeepSeek-V3 的每个 MoE 模块拥有 256 位专家,模型总参数量达到 6710 亿。但在推理时,每次只激活 9 位专家(1 位共享专家外加 8 位由路由选择的专家)。这意味着每步推理只使用 370 亿参数,而不是全部 6710 亿。DeepSeek-V3 的 MoE 设计中一个显著特点是使用了“共享专家”。这是一个始终为每个词元激活的专家。这个想法并不新鲜,它在 DeepSeek 2024 MoE 和 2022 年 DeepSpeedMoE 论文 中就已经被引入了。
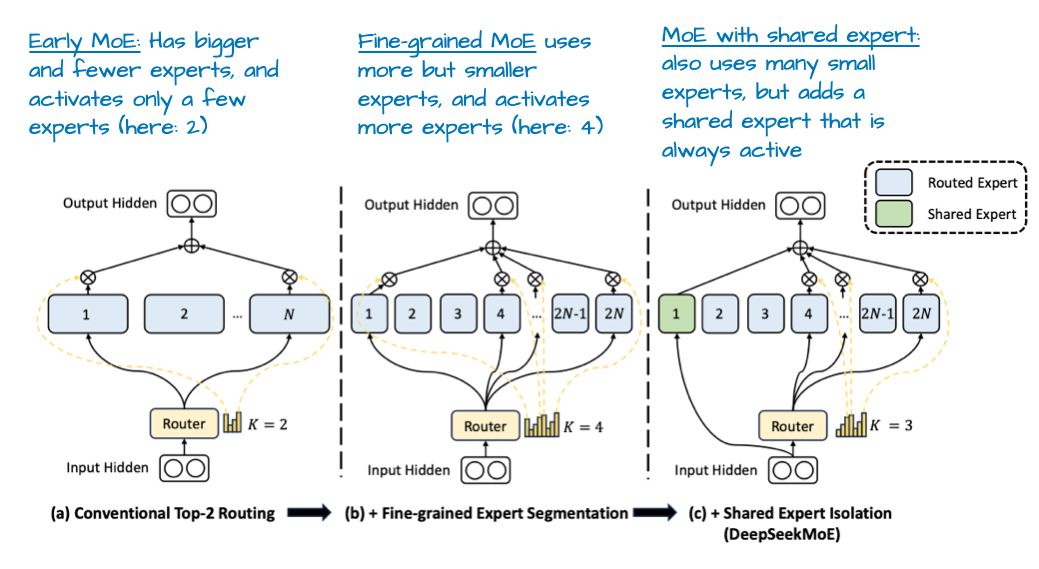
图 6:取自《DeepSeekMoE:实现专家混合语言模型中终极专家特化》的标注图,https://arxiv.org/abs/2401.06066
在 DeepSpeedMoE 论文 中,首次指出共享专家的好处,他们发现其相比没有共享专家的情况能提升整体模型性能。这可能是因为常见的或重复的模式无需由多个独立专家分别学习,从而让这些专家有更多空间学习更特化的模式。
1.3 DeepSeek 总结
总而言之,DeepSeek-V3 是一个拥有 6710 亿参数的大型模型,发布时其性能超越了包括 4050 亿参数的 Llama3 在内的其他开源模型。尽管体量更大,但得益于其专家混合(MoE)架构,它在推理时效率更高,因为每个词元仅激活一小部分(仅 370 亿)参数。
另一个关键的显著特征是 DeepSeek-V3 采用了多头潜在注意力 (MLA) 而非分组查询注意力 (GQA)。MLA 和 GQA 都是标准多头注意力(MHA)的推理高效替代方案,尤其是在使用 KV 缓存时。尽管 MLA 的实现更为复杂,但 DeepSeek-V2 论文中的研究表明,它比 GQA 具有更好的模型性能。

2. OLMo 2
Allen 人工智能研究所(Allen Institute for AI)开发的 OLMo 系列模型因其在训练数据和代码方面的透明度,以及相对详细的技术报告而备受关注。
虽然您可能不会在任何基准测试或排行榜上看到OLMo 模型名列前茅,但它们非常清晰,更重要的是,由于其透明性,它们成为了开发 LLM 的绝佳蓝图。
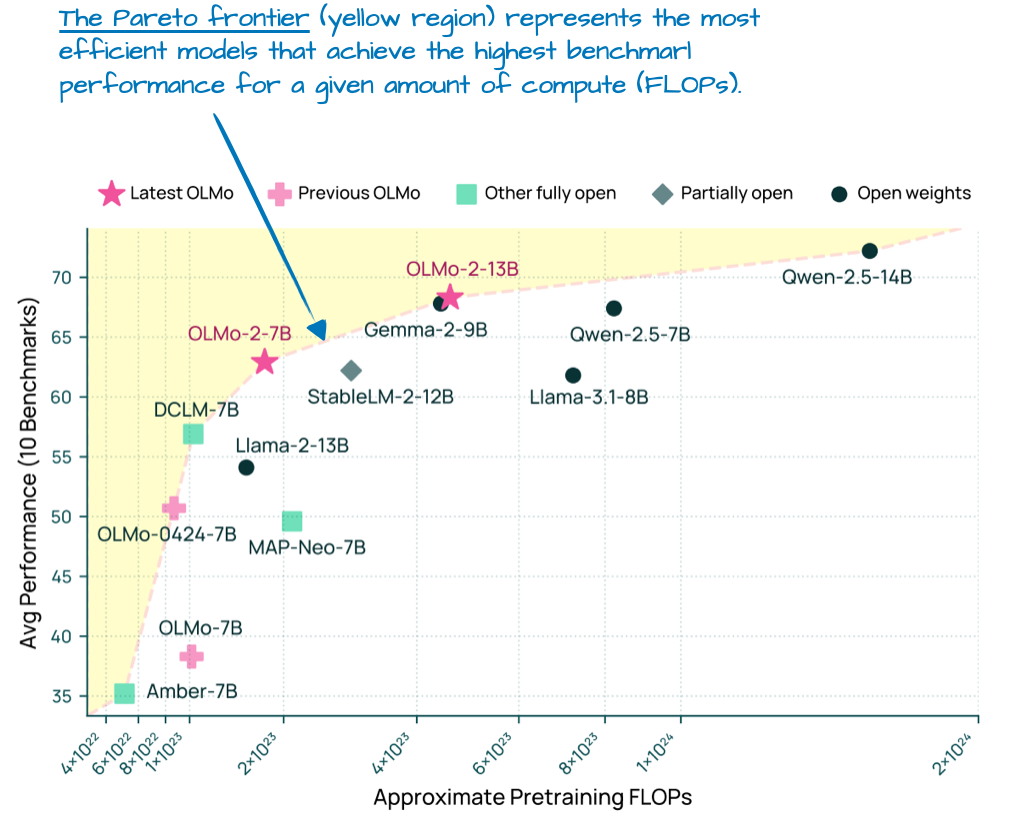
尽管 OLMo 模型因其透明度而备受欢迎,但它们的性能也相当不俗。事实上,在 1 月发布时(早于 Llama 4、Gemma 3 和 Qwen 3),OLMo 2 模型已达到计算效率与性能的帕累托最优前沿,如图 7 所示。
 img
img
图 7:不同 LLM 的模型基准性能(越高越好)与预训练成本(FLOPs;越低越好)对比图。此图取自 OLMo 2 论文并进行了标注,https://arxiv.org/abs/2501.00656
如本文前面所述,作者致力于只关注 LLM 的架构细节(而非训练或数据),以保持文章篇幅适中。那么,OLMo2 中有哪些有趣的架构设计选择呢?主要归结于归一化:RMSNorm 层的放置以及 QK-范数的添加,作者将在下面讨论。
值得一提的是,OLMo 2 仍然使用传统的多头注意力 (MHA),而非 MLA 或 GQA。
2.1 归一化层的位置
总体而言,OLMo 2 在很大程度上遵循了原始 GPT 模型的架构,与其他当代 LLM 类似。然而,也存在一些值得注意的偏差。让我们从归一化层开始。
与 Llama、Gemma 和大多数其他大型语言模型一样,OLMo 2 也从 LayerNorm 切换到了 RMSNorm。
但由于 RMSNorm 已是“老生常谈”(它本质上是 LayerNorm的简化版,可训练参数更少),作者将跳过 RMSNorm 与 LayerNorm 的讨论。(感兴趣的读者可以在作者的 GPT-2 到 Llama 转换指南 中找到 RMSNorm 的代码实现。)
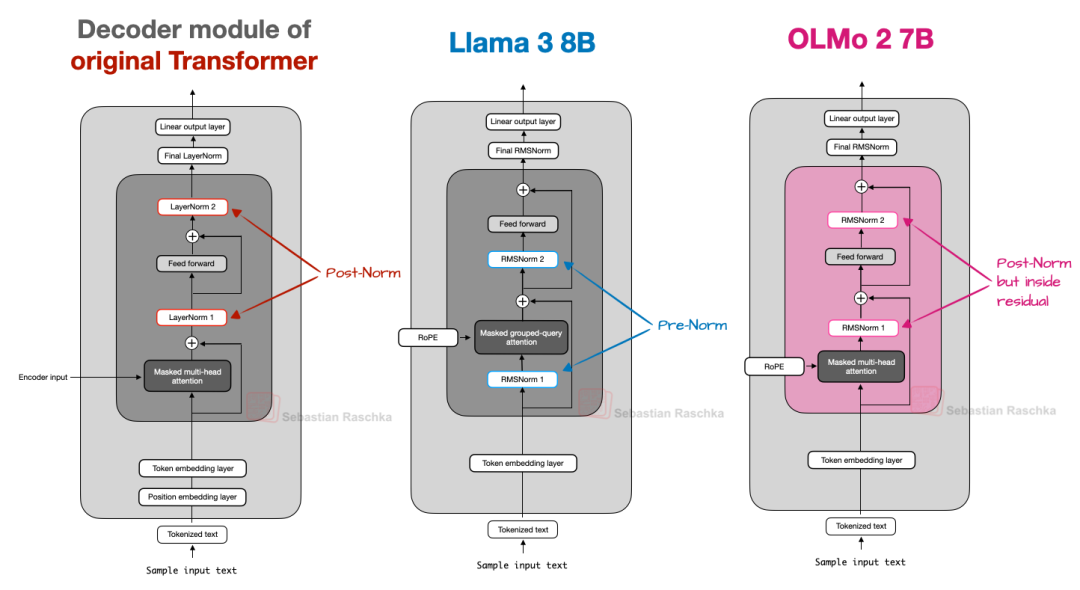
然而,RMSNorm 层的放置位置值得讨论。原始 Transformer 模型(出自“ Attention is all you need”论文)将两个归一化层分别放置在 Transformer 块的注意力模块和前馈模块之后。
这也被称作后归一化(Post-LN 或 Post-Norm)。
GPT 模型和许多后续的 LLM 则将归一化层放置在注意力模块和前馈模块之前,这被称为前归一化(Pre-LN 或 Pre-Norm)。后归一化和前归一化的比较如图所示。
 img
img
图 8:后归一化、前归一化和 OLMo 2 的后归一化变体的比较。
在 2020 年,Xiong 等人 的研究表明,前归一化 (Pre-LN)在初始化时能产生更理想的梯度行为。此外,研究人员还指出,前归一化甚至在没有仔细调整学习率预热的情况下也能表现良好,而学习率预热对于后归一化 (Post-LN) 来说是至关重要的工具。
现在,作者之所以提及这一点,是因为 OLMo 2 采用了一种后归一化形式(但使用的是 RMSNorm 而非 LayerNorm,因此作者称之为 Post-Norm)。在 OLMo 2 中,归一化层并非置于注意力层和前馈层之前,而是放在其后,如上图所示。然而,请注意,与原始 Transformer 架构不同的是,这些归一化层仍然位于残差层(跳跃连接)内部。
那么,他们为什么要改变归一化层的位置呢?原因是它有助于训练稳定性,如下图所示。
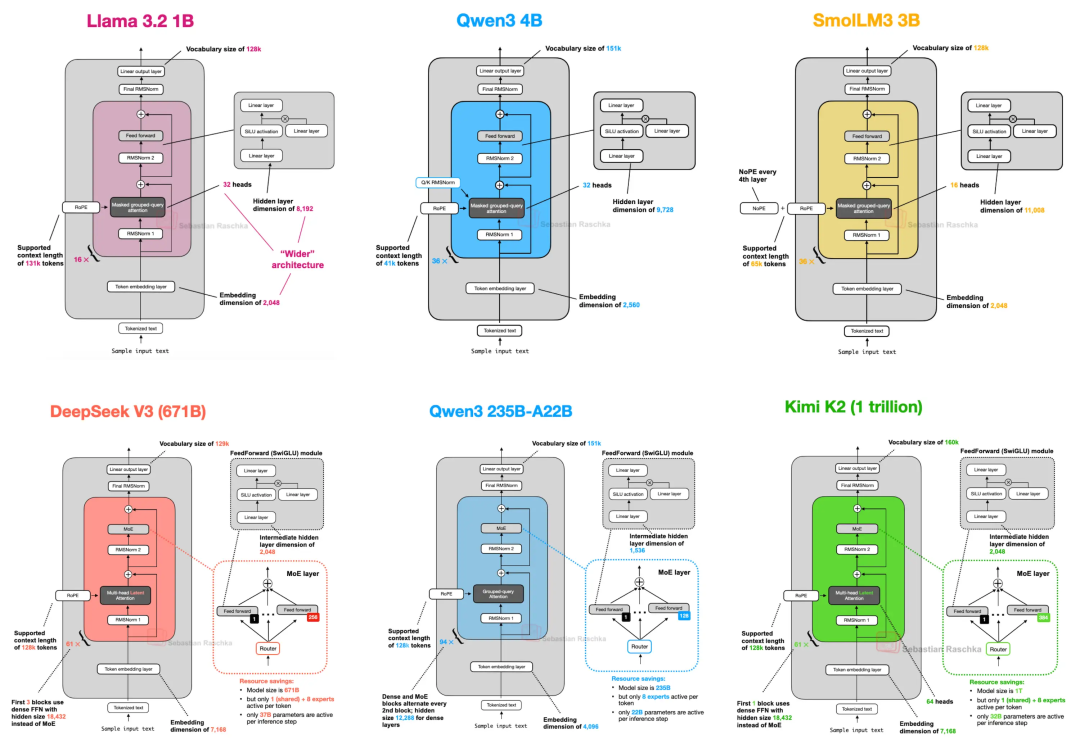
图 9:显示前归一化(如 GPT-2、Llama 3 和许多其他模型)与 OLMo 2 后归一化变体训练稳定性对比的图表。
不幸的是,这张图显示的是重排序与 QK-范数结合的结果,而 QK-范数是一个独立的机制。因此,很难判断归一化层重排序本身贡献了多少。
2.2 QK-范数 (QK-Norm)
既然前一节已经提到了 QK-范数,而且我们后面讨论的其他 LLM,如Gemma 2 和 Gemma 3,也使用了 QK-范数,那么我们来简要讨论一下这是什么。
QK-范数本质上是又一个 RMSNorm 层。它被放置在多头注意力 (MHA)模块内部,并在应用旋转位置嵌入 (RoPE) 之前应用于查询(q)和键(k)。为了说明这一点,下面是作者为 Qwen3 从零开始实现 所写的分组查询注意力 (GQA) 层的一个片段(GQA 中 QK-范数的应用与 OLMo 中的MHA 类似):
class GroupedQueryAttention(nn.Module):
def __init__(
self, d_in, num_heads, num_kv_groups,
head_dim=None, qk_norm=False, dtype=None
):
# ...
if qk_norm:
self.q_norm = RMSNorm(head_dim, eps=1e-6)
self.k_norm = RMSNorm(head_dim, eps=1e-6)
else:
self.q_norm = self.k_norm = None
def forward(self, x, mask, cos, sin):
b, num_tokens, _ = x.shape
# 应用投影
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
# ...
# 可选的归一化
if self.q_norm:
queries = self.q_norm(queries)
if self.k_norm:
keys = self.k_norm(keys)
# 应用 RoPE
queries = apply_rope(queries, cos, sin)
keys = apply_rope(keys, cos, sin)
# 扩展 K 和 V 以匹配头的数量
keys = keys.repeat_interleave(self.group_size, dim=1)
values = values.repeat_interleave(self.group_size, dim=1)
# 注意力计算
attn_scores = queries @ keys.transpose(2, 3)
# ...
如前所述,QK-范数与后归一化协同工作,共同稳定了训练过程。需要注意的是,QK-范数并非 OLMo 2 发明,其概念可追溯到 2023 年的 “扩展视觉 Transformers” 论文。
2.3 OLMo 2 总结
简而言之,OLMo 2 值得注意的架构设计决策主要在于RMSNorm 的放置:RMSNorm 放在注意力模块和前馈模块之后而非之前(一种后归一化的变体),以及在注意力机制内部为查询(queries)和键(keys)添加 RMSNorm(QK-范数),这两者共同有助于稳定训练损失。
下面是 OLMo 2 与 Llama 3 的并排比较图;可以看出,除了 OLMo 2 仍然使用传统的 MHA 而非GQA 外,两者架构相对相似。(不过,OLMo 2 团队在 3 个月后发布了使用 GQA 的 320 亿参数变体)。
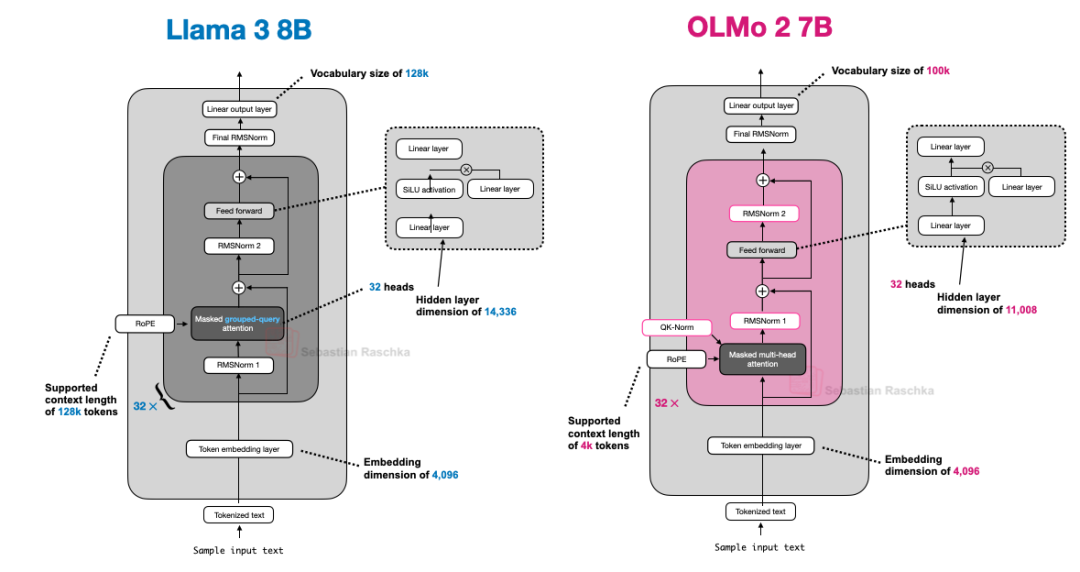
图 10:Llama 3 和 OLMo 2 的架构比较。
3. Gemma 3
谷歌的 Gemma 模型一直表现优异,在作者看来,它们一直被低估了,不如 Llama 系列等其他流行模型受关注。
Gemma 的独特之处在于其相对较大的词汇量(以便更好地支持多种语言),以及更侧重于 270 亿参数的模型尺寸(而非 80 亿或 700 亿)。但请注意,Gemma 2 也提供了更小的尺寸:10 亿、40 亿和 120 亿。
270亿参数的尺寸达到了一个非常好的平衡点:它比 80 亿参数的模型功能强大得多,但又不像 700 亿参数的模型那样耗费资源,而且在作者的 Mac Mini 上也能流畅运行。那么,Gemma 3 还有哪些值得关注的特点呢?正如前面讨论的,DeepSeek-V3/R1等其他模型采用专家混合 (MoE) 架构,以在给定固定模型尺寸下减少推理所需的内存(MoE 方法也被我们后面将讨论的多个其他模型所采用)。
Gemma 3 采用了不同的“技巧”来降低计算成本,即滑动窗口注意力(sliding window attention)。
3.1 滑动窗口注意力
借助于滑动窗口注意力(最初由 2020 年的 LongFormer 论文 引入,且已被 Gemma 2 采用),Gemma3 团队大幅减少了 KV 缓存的内存需求,如下图所示。
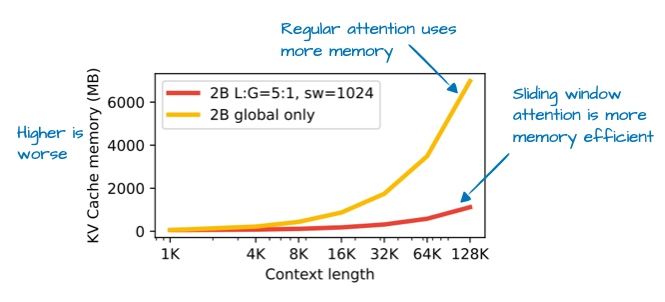
图 11:来自 Gemma 3 论文(https://arxiv.org/abs/2503.19786)的标注图,展示了通过滑动窗口注意力节省的 KV 缓存内存。
那么,什么是滑动窗口注意力呢?如果我们把常规的自注意力机制看作是一种全局注意力机制,因为每个序列元素都可以访问其他所有序列元素,那么滑动窗口注意力则可以看作是一种局部注意力机制,因为它限制了当前查询位置周围的上下文大小。这在下图中有所说明。
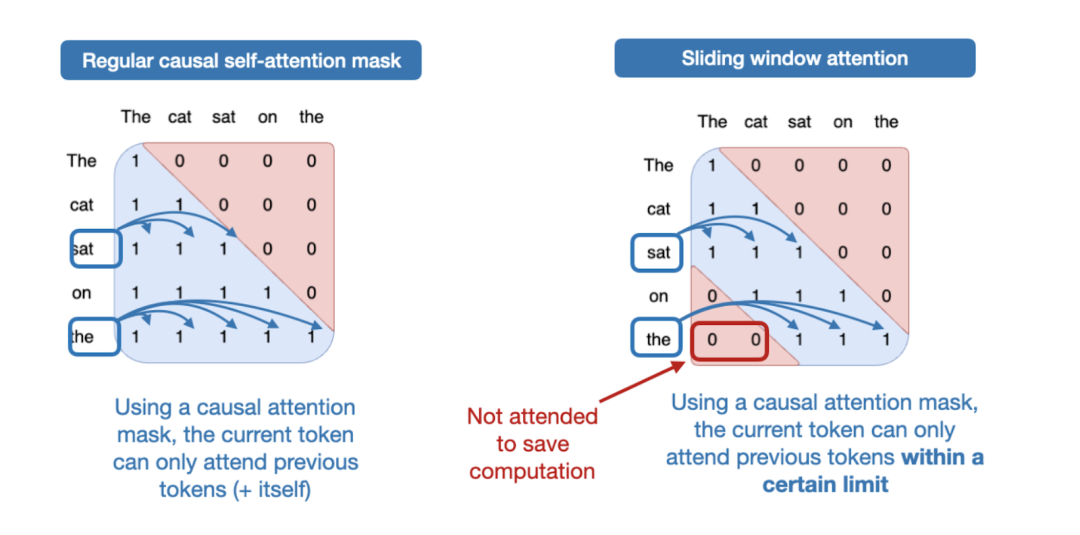
图 12:常规注意力(左)与滑动窗口注意力(右)的比较。
请注意,滑动窗口注意力可与多头注意力(MHA)和分组查询注意力(GQA)结合使用;Gemma 3 使用的是分组查询注意力。
如上所述,滑动窗口注意力也被称为 局部 注意力,因为局部窗口环绕并随当前查询位置移动。相比之下,常规注意力是 全局 的,因为每个词元都可以访问所有其他词元。
现在,正如前文简要提及,Gemma 2 的前身架构也曾使用滑动窗口注意力。Gemma 3 的不同之处在于,它们调整了全局(常规)注意力与局部(滑动)注意力之间的比例。
例如,Gemma 2 采用混合注意力机制,以 1:1 的比例结合了滑动窗口(局部)注意力和全局注意力。每个词元可以关注其附近 4k 词元的窗口。
Gemma 2 在每隔一层中使用滑动窗口注意力,而 Gemma 3 现在采用 5:1 的比例,这意味着每 5 个滑动窗口(局部)注意力层只有 1 个完整注意力层;此外,滑动窗口大小从 4096(Gemma 2)减少到仅 1024(Gemma 3)。这使得模型的重点转向更高效的局部计算。
根据他们的消融研究,滑动窗口注意力对模型性能的影响微乎其微,如下图所示。
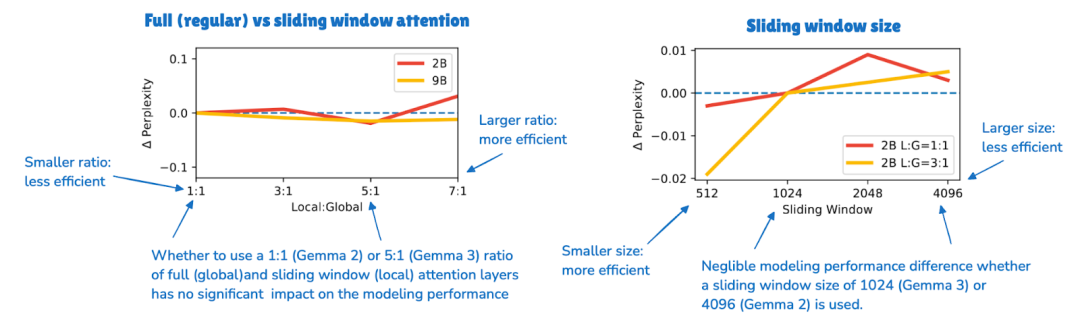
图 13:来自 Gemma 3 论文(https://arxiv.org/abs/2503.19786)的标注图,显示滑动窗口注意力对 LLM 生成输出的困惑度几乎没有影响。
尽管滑动窗口注意力是 Gemma 3 最显著的架构特点,但作者想在上一节 OLMo 2 的基础上,简要探讨一下归一化层的放置问题。
3.2 Gemma 3 中的归一化层放置
一个虽小但有趣的细节是,Gemma 3 在其分组查询注意力模块前后都使用了 RMSNorm,即同时采用了前归一化 (Pre-Norm) 和后归一化 (Post-Norm) 设置。
这与 Gemma 2 类似,但仍值得强调,因为它与(1)原始 Transformer(出自“Attention isall you need”)中使用的后归一化、(2)GPT-2 普及并随后在许多其他架构中使用的前归一化,以及(3)我们之前看到的 OLMo 2 中的后归一化变体有所不同。
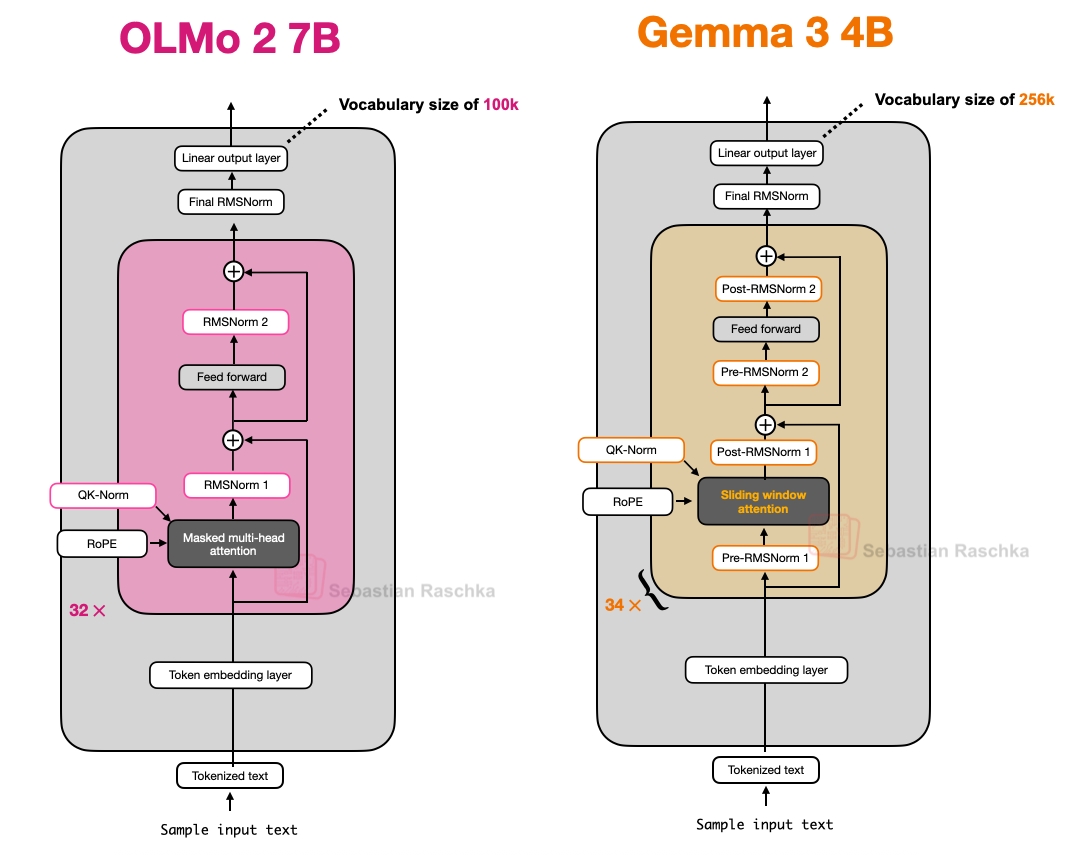
图 14:OLMo2和 Gemma 3 的架构比较;请注意 Gemma 3 中额外的归一化层。
作者认为这种归一化层放置方法相对直观,因为它兼顾了前归一化和后归一化的优点。在作者看来,多一点归一化总没坏处。最坏的情况下,如果多余的归一化是冗余的,这只会导致一些效率低下。但在实际应用中,由于 RMSNorm 的计算成本相对较低,这应该不会产生任何明显影响。
3.3 Gemma 3 总结
总之,Gemma 3 是一款性能优秀的开源 LLM,在作者看来,它在开源社区中多少被低估了。其最有趣的亮点在于利用滑动窗口注意力提升了效率(未来将其与 MoE 结合将会很有趣)。
此外,Gemma 3 独具匠心地放置了归一化层,在注意力模块和前馈模块的前后都设置了 RMSNorm 层。
3.4 Gemma 3n
在 Gemma 3 发布几个月后,谷歌发布了 Gemma 3n,这是一个经过优化以适应小型设备效率的 Gemma 3 模型,目标是在手机上运行。
Gemma 3n 实现更高效率的变化之一是所谓的“逐层嵌入参数层(Per-Layer Embedding, PLE)”。其核心思想是仅将模型参数的一个子集保留在 GPU 内存中。词元-层特有的嵌入,例如文本、音频和视觉模态的嵌入,则按需从 CPU 或固态硬盘(SSD)流式传输。
下图展示了 PLE 的内存节省效果,列出了标准 Gemma 3 模型 54.4 亿个参数。这很可能指的是 Gemma 3的 40 亿参数变体。
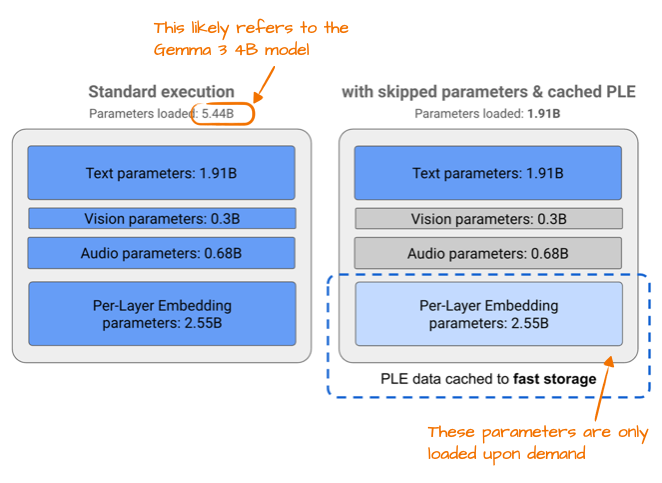 图 15:来自谷歌 Gemma 3n 博客(https://developers.googleblog.com/en/introducing-gemma-3n/)的标注图,说明了 PLE 内存节省情况。
图 15:来自谷歌 Gemma 3n 博客(https://developers.googleblog.com/en/introducing-gemma-3n/)的标注图,说明了 PLE 内存节省情况。
54.4 亿参数与 40 亿参数之间的差异,是因为谷歌在报告 LLM 参数数量时采用了一种有趣的方式。他们通常会排除嵌入参数,以使模型看起来更小,除非在这种情况下,为了让模型看起来更大而将其包含在内,这便显得很方便。这种做法并非谷歌独有,它已成为整个领域的普遍做法。
另一个有趣的技巧是 MatFormer 概念(Matryoshka Transformer 的缩写)。例如,Gemma 3n 使用一个共享的 LLM(Transformer)架构,该架构可以切分成更小的、可独立使用的模型。每个切片都经过训练,可以独立运行,因此在推理时,我们只需运行所需的部分(而不是整个大型模型)。
4. Mistral Small 3.1
Mistral Small3.1 24B 于 3 月份,也就是 Gemma 3 发布后不久问世,值得关注的是它在多项基准测试(数学除外)上超越了 Gemma 3 27B,并且速度更快。
Mistral Small 3.1 推理延迟较低的原因可能在于其定制化的分词器,以及对KV 缓存和层数的缩减。除此之外,它采用了标准的架构,如下图所示。
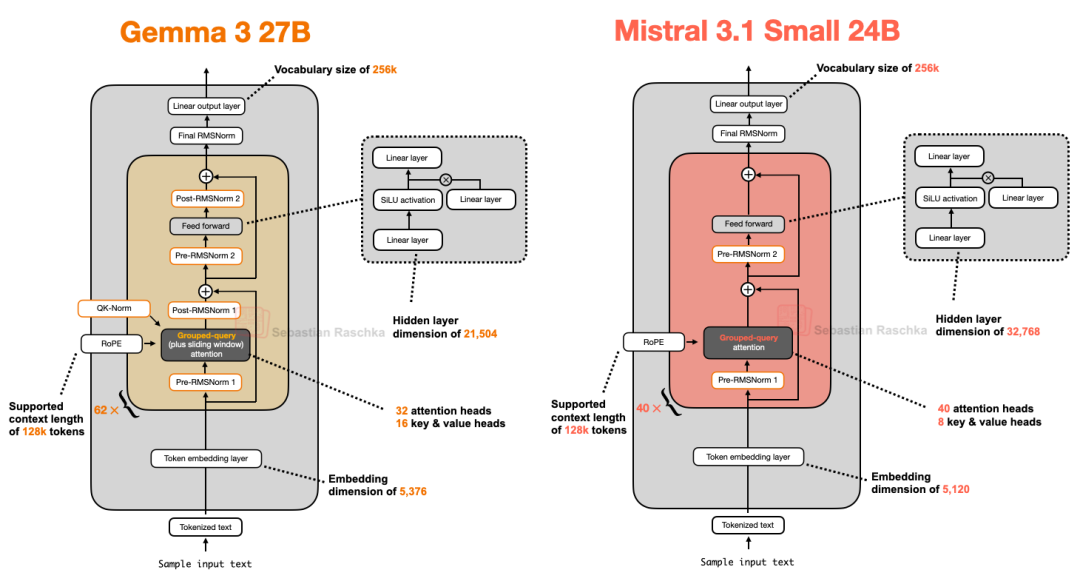
图 16:Gemma 3 27B 和 Mistral 3.1 Small 24B 的架构比较。
有趣的是,早期的 Mistral 模型曾利用滑动窗口注意力,但似乎在 Mistral Small 3.1 中放弃了这一技术。因此,由于 Mistral 使用常规的分组查询注意力,而非 Gemma 3 中带滑动窗口的分组查询注意力,可能存在额外的推理计算节省,这得益于能够使用更优化的代码(例如 FlashAttention)。例如,作者推测滑动窗口注意力虽然减少了内存使用,但不一定能降低推理延迟,而这正是 Mistral Small 3.1 所关注的重点。
5. Llama 4
本文前面关于专家混合 (MoE) 的详细介绍再次派上用场。Llama 4 也采用了 MoE 方法,其他方面则遵循相对标准的架构,与 DeepSeek-V3 非常相似,如下图所示。(Llama 4 包含原生多模态支持,类似于 Gemma 和 Mistral 等模型。然而,由于本文侧重于语言建模,我们仅关注文本模型部分。)
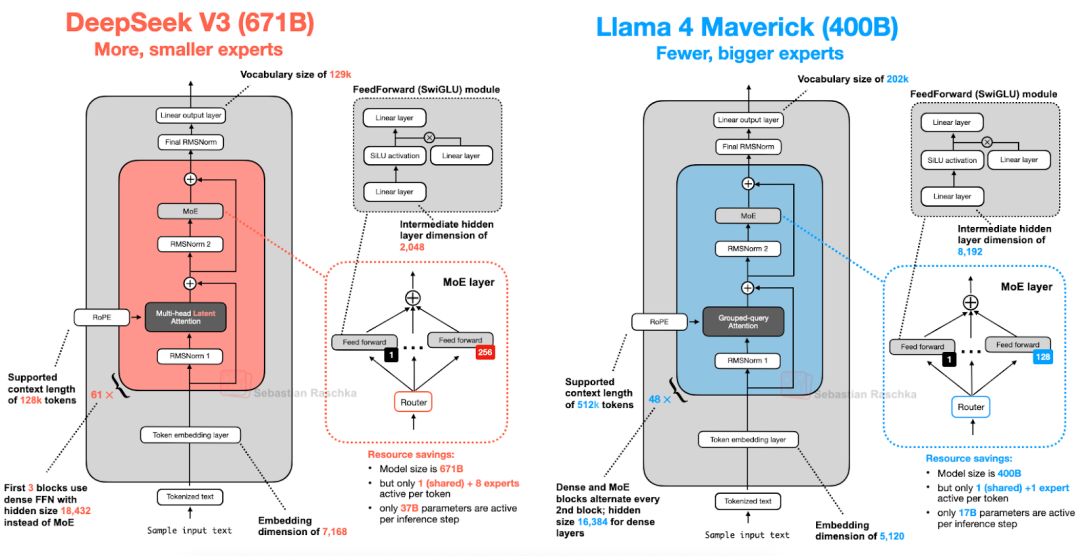
图 17:DeepSeek V3(6710 亿参数)和 Llama 4 Maverick(4000 亿参数)的架构比较。
虽然Llama 4 Maverick 的整体架构与 DeepSeek-V3 非常相似,但仍有一些值得强调的有趣区别。
首先,Llama 4 类似其前辈,使用了分组查询注意力 (GQA),而 DeepSeek-V3 则采用了我们在本文开头讨论过的多头潜在注意力 (MLA)。目前,DeepSeek-V3 和 Llama 4 Maverick 都是非常庞大的架构,DeepSeek-V3 的总参数量比 Llama 4Maverick 大约 68%。然而,DeepSeek-V3 拥有 370 亿个活跃参数,是 Llama 4 Maverick(170 亿)活跃参数的两倍多。
Llama 4Maverick 采用更经典的 MoE 设置,专家数量更少但规模更大(2 个活跃专家,每个隐藏层大小为 8192),而 DeepSeek-V3 则有 9 个活跃专家,每个隐藏层大小为 2048。此外,DeepSeek 在每个 Transformer 块(除了前 3 个)中都使用 MoE 层,而 Llama 4 则在每隔一个 Transformer 块中交替使用 MoE 和密集模块。
鉴于架构之间存在诸多细微差异,要准确判断它们对最终模型性能的影响实属不易。然而,主要结论是,专家混合(MoE)架构在 2025 年的受欢迎程度显著提升。
6. Qwen3
通义千问(Qwen)团队一直致力于提供高质量的开源 LLM。作者记得在 NeurIPS 2023 协助共同指导 LLM效率挑战赛时,所有最佳获奖方案都基于 Qwen2。
现在,Qwen3 又是另一个热门模型系列,在各自规模类别中名列排行榜前茅。它拥有 7 个稠密模型:0.6B、1.7B、4B、8B、14B 和 32B。此外,还有 2 个 MoE 模型:30B-A3B 和 235B-A22B。
(顺便提一句,“Qwen3”中没有空格并非打字错误;作者只是努力保留了通义千问开发者选择的原始拼写。)
6.1 Qwen3 (密集模型)
我们先来讨论密集模型架构。撰写本文时,0.6B 模型很可能是当前世代最小的开源模型。根据作者的个人经验,它在如此小的尺寸下表现异常出色。如果您打算在本地运行它,它具有出色的每秒词元吞吐量和较低的内存占用。更重要的是,由于其小巧的尺寸,它也很容易在本地进行训练(用于教育目的)。
因此,Qwen3 0.6B 在多数情况下已经取代了 Llama 3 1B。这两种架构的比较如下图所示。
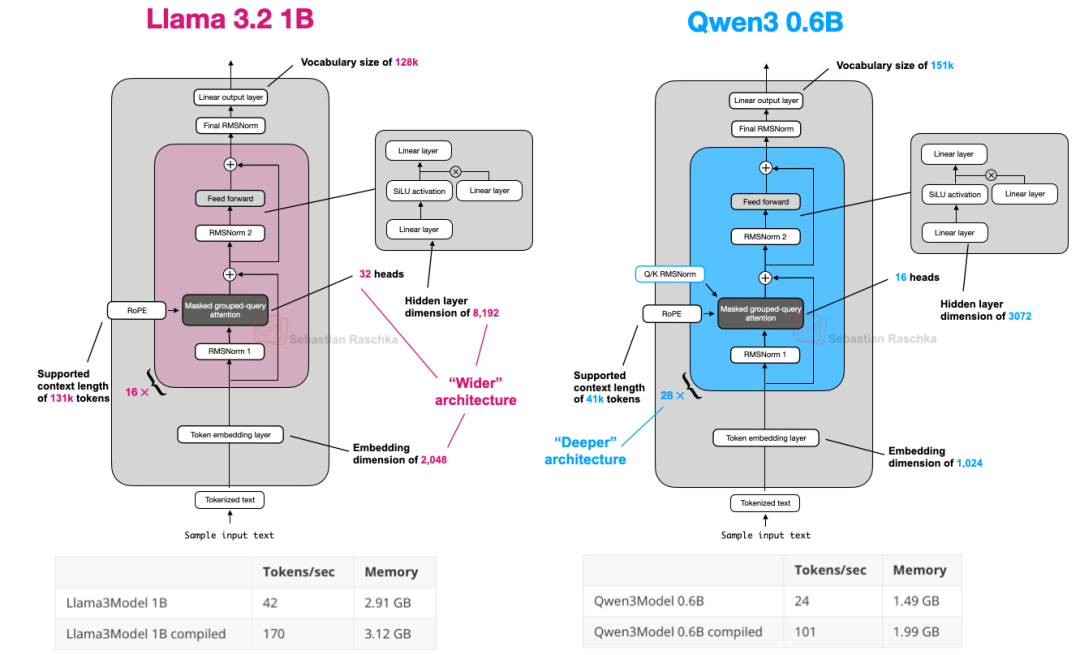
图 18:Qwen3 0.6B 和 Llama 3 1B 的架构比较;请注意 Qwen3 是一个更深层的架构,层数更多,而 Llama 3 是一个更宽的架构,注意力头更多。
如果您对无需依赖外部第三方 LLM 库的易读 Qwen3 实现感兴趣,作者最近从头开始(纯 PyTorch)实现了一个 Qwen3。
上图中所示的计算性能数据是基于我在 A100 GPU 上运行的从零开始的 PyTorch 实现。可以看出,Qwen3 占用内存更小,因为它整体架构更小,而且隐藏层和注意力头也更少。然而,它比 Llama 3 使用了更多的 Transformer 块,导致运行速度更慢(每秒词元生成速度更低)。
6.2 Qwen3 (MoE)
如前所述,Qwen3 也提供了两种 MoE 版本:30B-A3B 和 235B-A22B。为什么有些架构,比如 Qwen3,会同时提供常规(密集)和 MoE(稀疏)版本呢?
正如本文开头所述,MoE 变体有助于降低大型基础模型的推理成本。提供密集和 MoE 两种版本,可根据用户的目标和限制提供灵活性。
密集模型通常更容易进行微调、部署和在各种硬件上进行优化。
另一方面,MoE 模型则针对大规模推理进行了优化。例如,在固定的推理预算下,它们可以实现更高的整体模型容量(即,由于模型更大,训练期间可以吸收更多知识),而无需按比例增加推理成本。
通过发布这两种类型,Qwen3 系列可以支持更广泛的用例:密集模型适用于鲁棒性、简单性和微调,而 MoE 模型则适用于高效的大规模服务。
为了总结本节,我们来比较一下 DeepSeek-V3 和 Qwen3 235B-A22B(请注意,A22B 代表“220 亿活跃参数”),前者活跃参数几乎是后者的两倍(370 亿)。
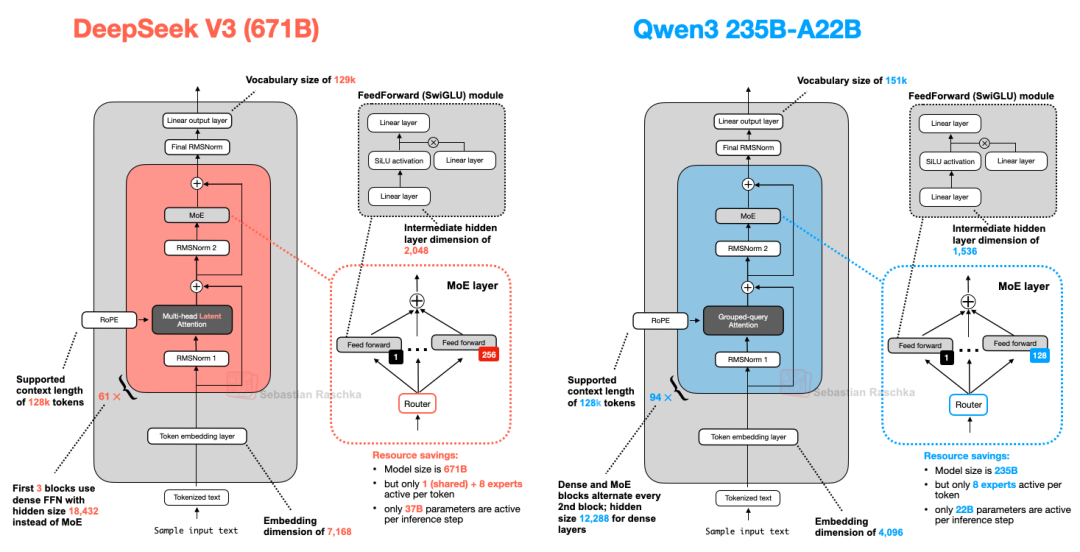
图 19:DeepSeek-V3 和 Qwen3 235B-A22B 的架构比较。
如上图所示,DeepSeek-V3 和 Qwen3 235B-A22B 架构惊人地相似。然而,值得注意的是,Qwen3 模型放弃了共享专家的使用(早期的 Qwen 模型,例如 Qwen2.5-MoE 确实使用了共享专家)。
不幸的是,Qwen3 团队并未透露他们放弃共享专家的原因。如果作者必须猜测,或许是当他们将专家数量从 2 个(Qwen2.5-MoE 中)增加到 8 个(Qwen3 中)时,对于其设置的训练稳定性而言,共享专家根本没有必要。于是,他们通过只使用 8 个而不是 8+1 个专家,节省了额外的计算/内存成本。(然而,这并不能解释 DeepSeek-V3 为何仍保留共享专家。)
7. SmolLM3
SmolLM3 也许不如本文中提及的其他 LLM 那样受欢迎,但作者认为它仍然是一个值得纳入的有趣模型,因为它在相对较小的 30 亿参数模型尺寸下提供了非常好的模型性能,其规模介于 17 亿和 40 亿参数的 Qwen3 模型之间,如下图所示。
此外,它还分享了许多训练细节,与 OLMo 类似,这实属罕见且总是令人赞赏!
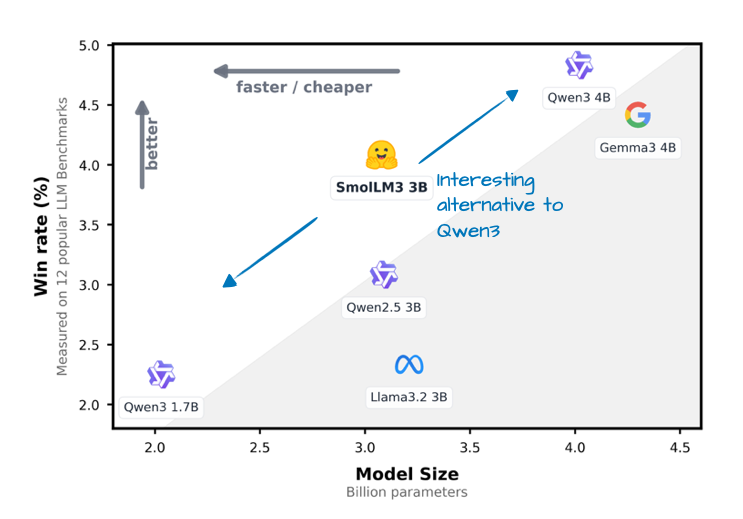
图 20:SmolLM3 发布公告(https://huggingface.co/blog/smollm3)中比较 SmolLM3 胜率与Qwen3 1.7B 和 4B 以及 Llama 3 3B 和 Gemma 3 4B 的标注图。
如下图所示的架构比较,SmolLM3 架构看起来相当标准。然而,它最有趣的方面或许是其使用了无位置嵌入(NoPE)。
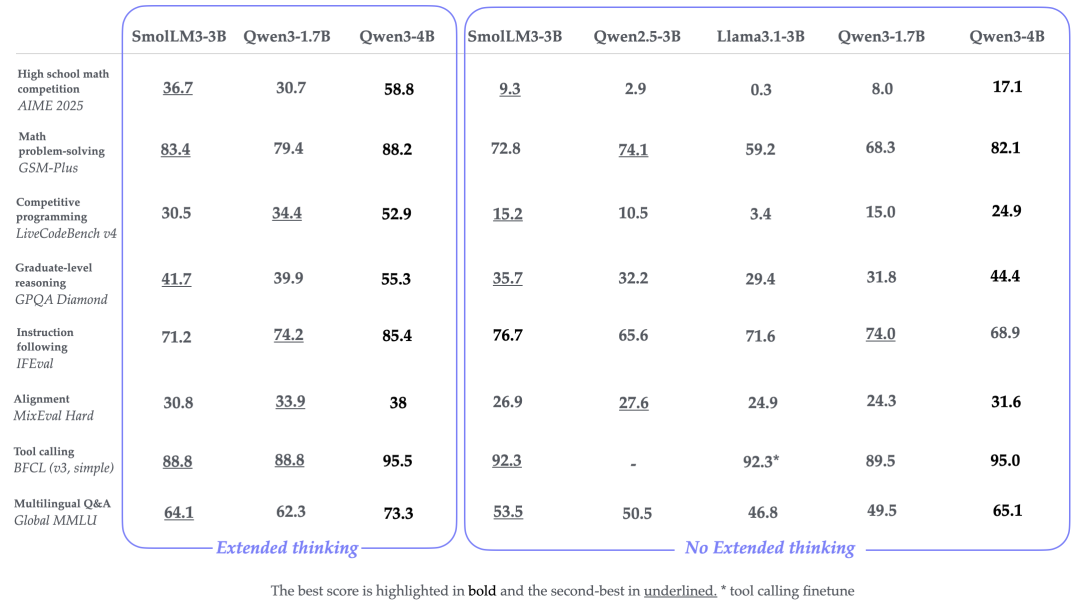
图 21:Qwen3 4B 和 SmolLM3 3B 的并排架构比较。
7.1 无位置嵌入 (NoPE)
在 LLM 应用中,无位置嵌入(NoPE)是一个较早提出的概念,可追溯到 2023 年的一篇论文(《位置编码对 Transformer 中长度泛化能力的影响》),旨在移除显式的位置信息注入(例如通过早期 GPT 架构中的经典绝对位置嵌入层或现今的旋转位置嵌入 RoPE)。
在基于 Transformer 的大型语言模型(LLM)中,位置编码通常是必需的,因为自注意力机制独立于词元顺序处理它们。绝对位置嵌入通过添加一个额外的嵌入层来为词元嵌入添加信息,从而解决了这个问题。
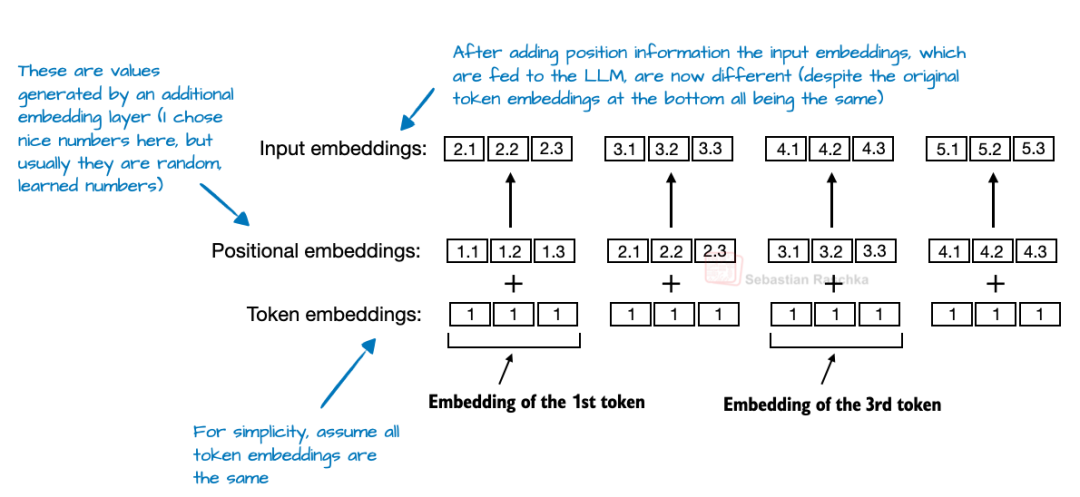
图 22:摘自作者著作《从零构建大型语言模型》(https://www.amazon.com/Build-Large-Language-Model-Scratch/dp/1633437167)的修改图,说明了绝对位置嵌入。
另一方面,RoPE 的解决方案是旋转查询和键向量,使其相对于词元位置。
然而,在 NoPE(无位置嵌入)层中,根本不添加任何此类位置信号:不固定,不学习,也不相对。什么都没有。
即使没有位置嵌入,模型仍然知道哪些词元在前面,这要归功于因果注意力掩码。该掩码阻止每个词元关注未来的词元。因此,位置 t 的词元只能看到位置小于等于 t 的词元,这保留了自回归排序。
因此,尽管没有明确添加位置信息,但模型的结构中仍然隐含着方向感,LLM 在常规的基于梯度下降的训练中,如果发现对优化目标有利,便能学会利用这种方向感。(更多信息请查阅 NoPE 论文中的定理。)
总的来说,NoPE 论文 不仅发现不需要注入位置信息,还发现 NoPE 具有更好的长度泛化能力,这意味着随着序列长度的增加,LLM 的回答性能下降较少,如下图所示。
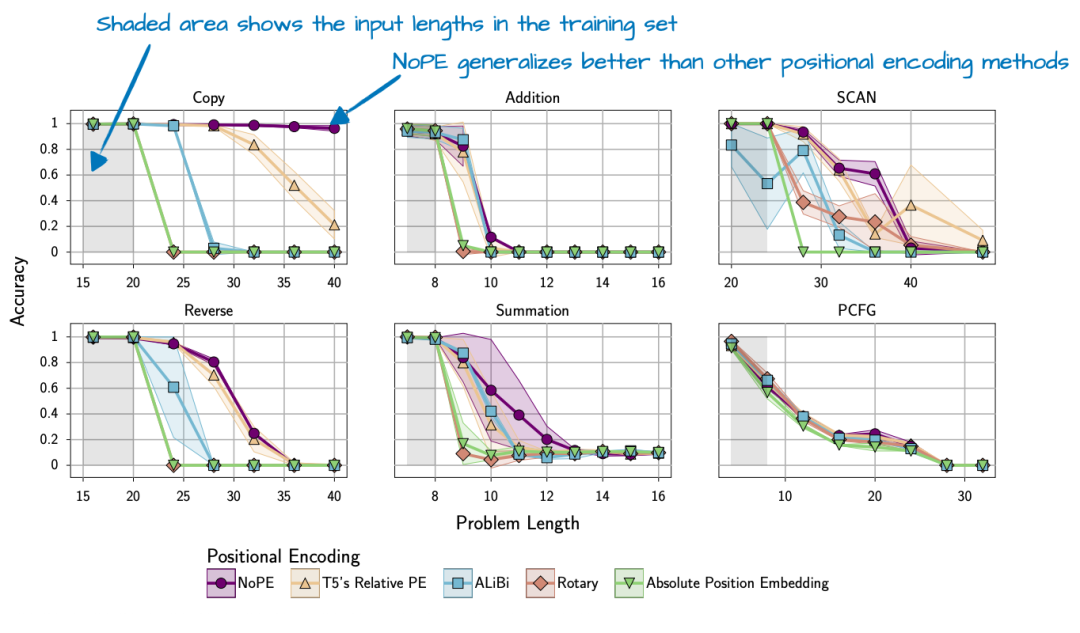
图 23:来自 NoPE 论文(https://arxiv.org/abs/2305.19466)的标注图,显示 NoPE 具有更好的长度泛化能力。
请注意,上述实验是使用大小约为 1 亿参数的相对较小的 GPT风格模型和相对较小的上下文大小进行的。这些发现能多大程度上推广到更大的当代 LLM,目前尚不清楚。
因此,SmolLM3 团队可能只是在每四个层中“应用”了 NoPE(或者说省略了 RoPE)。
8. Kimi 2
Kimi 2 最近在人工智能社区引发了巨大轰动,因为它是一款性能卓越的开源模型。根据基准测试,它与谷歌的 Gemini、Anthropic 的 Claude 以及 OpenAI 的 ChatGPT 等顶级闭源模型不相上下。
一个显著特点是它使用了相对较新的Muon 优化器 的变体,而非 AdamW。据作者所知,这是 Muon 首次被用于如此规模的生产模型,此前它只被证明能扩展到 160 亿参数(先前)。这使得训练损失曲线表现出色,这可能有助于将该模型推向前述基准测试的顶端。
虽然人们评论损失异常平滑(因为没有尖峰),但作者认为它并非异常平滑(例如,参见下图中 OLMo 2 的损失曲线;此外,梯度的 L2范数可能更能衡量训练稳定性)。然而,其损失曲线的衰减程度确实引人注目。
然而,正如本文引言中提到的,训练方法学是另一个话题,留待以后讨论。
该模型本身拥有 1 万亿参数,这确实令人印象深刻。
截至本文撰写之时,它可能是这一代最大的 LLM(考虑到 Llama 4 Behemoth 尚未发布、闭源 LLM 不算在内,以及谷歌的 1.6 万亿参数 Switch Transformer 是另一代的编码器-解码器架构)。
Kimi 2 也算殊途同归,它沿用了我们在本文开头介绍的 DeepSeek-V3 架构,只是将其规模变得更大,如下图所示。
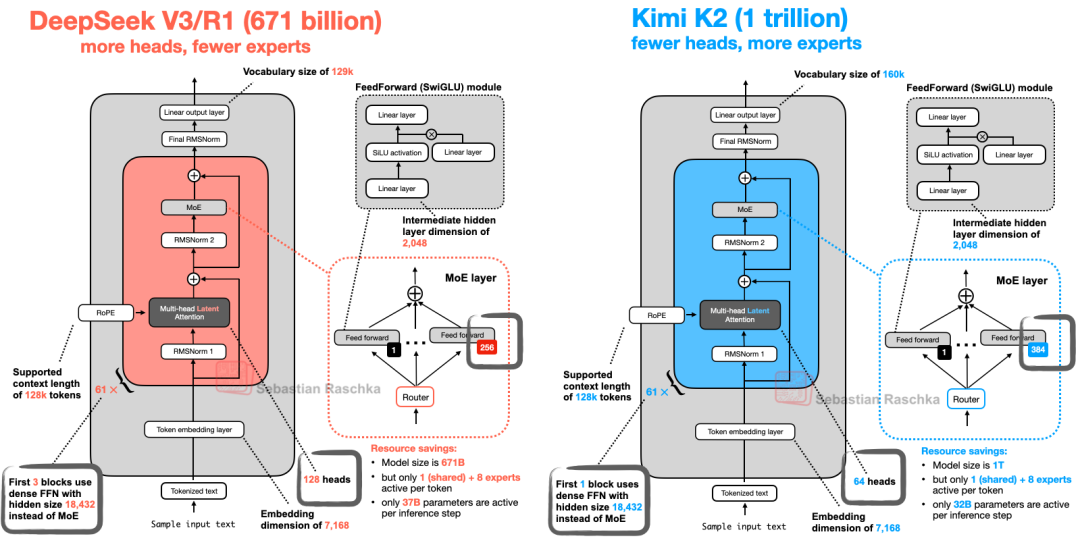
图 25:DeepSeek V3 和 Kimi K2 的架构比较。
如图所示,Kimi 2 和 DeepSeekV3 基本相同,只是它在专家混合(MoE)模块中使用了更多的专家,而在多头潜在注意力(MLA)模块中使用了更少的头部。
Kimi 2 并非凭空出现。早期在 Kimik1.5:强化学习与 LLM 扩展 论文中讨论的 Kimi 1.5 模型同样令人印象深刻。然而,它不幸地与 DeepSeek R1 模型论文在同一天(1 月 22 日)发布。此外,据作者所知,Kimi 1.5 的权重从未公开分享过。
因此,Kimi K2 团队很可能吸取了这些教训,在 DeepSeek R2 发布之前,将 Kimi K2 作为开源模型分享出来。截至本文撰写时,Kimi K2 是最令人印象深刻的开源模型。
作者:致Great
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 1850
1850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









