



- 背景:为什么需要微调?
- 核心概念:什么是微调?
- 技术原理:微调如何工作?
- 微调的类型和方法详解
- 应用场景案例
- 微调的优势与挑战
一、背景:为什么需要微调?
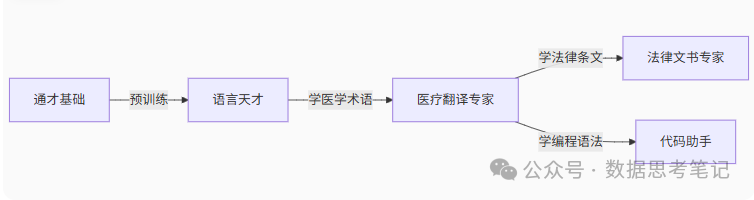
想象一下,你刚刚学会了汉语的基本语法和词汇,能够理解和表达日常对话,但如果让你去当医生、律师或程序员,你就需要在已有的语言基础上,再学习专业知识和专业表达方式。
大语言模型就像这样一个"语言天才"。它们通过预训练阶段在海量文本上学习,掌握了丰富的语言知识和常识,但要在特定领域发挥作用,就需要进一步的专业化训练——这就是微调的作用。
传统解法:重新培训(训练新模型)—— 耗时费钱,浪费原有天赋。
创新方案:微调 → 在原有能力基础上,用少量专业数据针对性强化。
二、核心概念:什么是微调?
1. 基本概念
定义:在预训练大模型的基础上,用特定领域的小规模数据继续训练,使其适应专门任务的过程。
类比:
预训练 = 读完12年基础教育(掌握通用知识);
微调 = 大学专业课程(4年针对性学习成为医生/律师/工程师)。
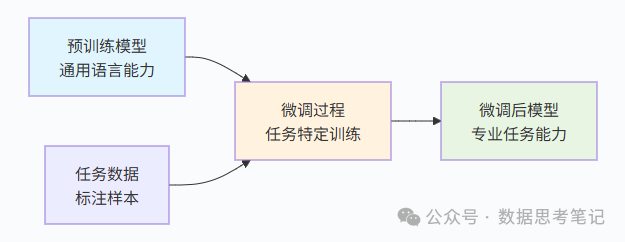
微调的核心思想是“站在巨人的肩膀上”:
1.保留基础能力: 不从零开始,而是基于已有的强大基础。
2.针对性优化: 只需要相对少量的数据来学习特定任务。
3.高效利用资源: 相比从头训练,大大减少了计算和数据需求。
2. 微调 vs 预训练
| 对比维度 | 预训练 | 微调 |
|---|---|---|
| 数据规模 | 海量(TB级) | 少量(MB-GB级) |
| 数据标注需求 | 无需标注 | 需标注 |
| 训练目标 | 学习通用语言规律 | 适应特定任务 |
| 计算成本 | 极高(百万美元级) | 较低(百美元级) |
| 输出结果 | 基础模型 | 领域专家模型 |
三、技术原理:微调如何工作?
1. 微调训练过程
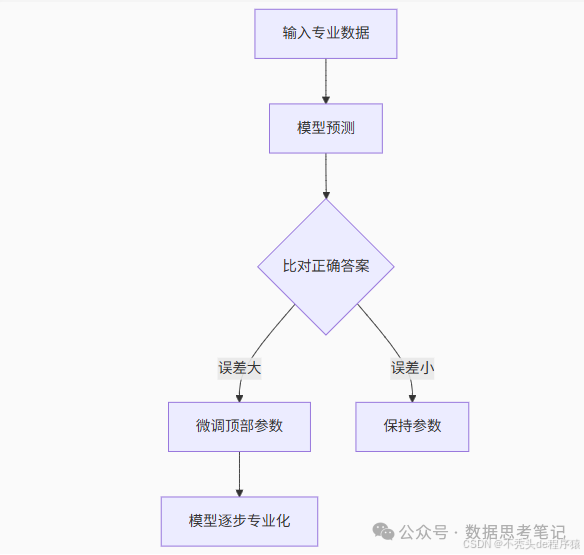
教预训练模型识别“差评”:
(1)输入:“手机电池续航太差了!” → 真实标签:差评;
(2)模型初始预测:中性(未理解“差”的情感强度);
(3)系统计算误差 → 微调情感分析相关参数;
(4)反复训练后 → 模型学会“差”“糟糕”“垃圾”等词的负面含义。
2. 参数更新机制
想象模型的参数就像一个人的知识结构。预训练阶段建立了基础的知识框架,微调阶段则在这个框架上进行精细调整:
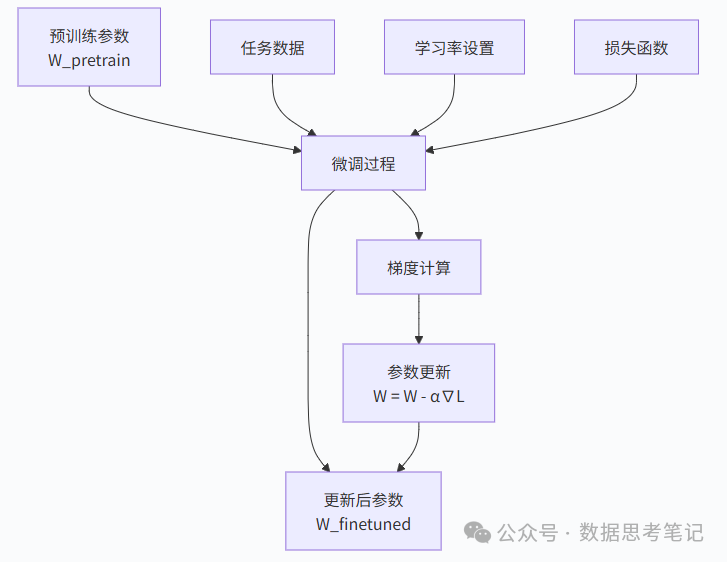
(1)梯度计算过程
- 前向传播:输入数据通过模型计算得到预测结果
- 损失计算:比较预测结果与真实标签,计算损失值
- 反向传播:计算损失对每个参数的梯度
- 参数更新:使用梯度下降法更新参数
(2)学习率策略
- 分层学习率:对不同层设置不同的学习率,通常底层(更通用)用更小的学习率
- 学习率衰减:随着训练进行逐步减小学习率,避免在最优解附近振荡
- 热身策略:开始时使用很小的学习率,逐步增加到目标值
(3)损失函数设计
- 分类任务:交叉熵损失 + 正则化项
- 生成任务:语言模型损失(下一词预测)
- 多任务:加权组合多个任务的损失
数学表达:
微调目标:minimize L_finetune = L_task + λ * L_regularization
其中:
- L_task:任务特定损失
- L_regularization:正则化项(如L2正则化)
- λ:正则化权重
四、微调的类型和方法详解
1. 微调方法分类体系
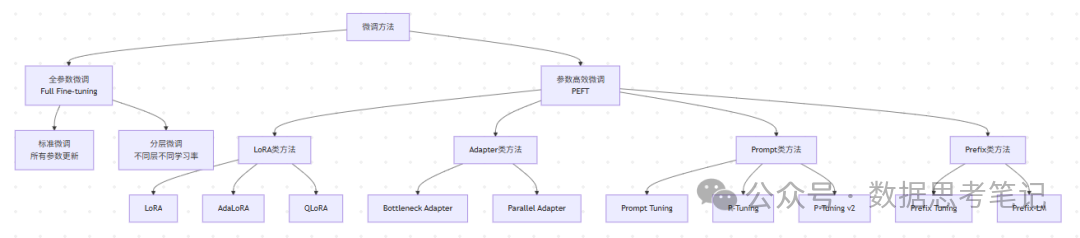
2. 全参数微调(Full Fine-tuning)
全参数微调是最直接的方法,更新模型的所有参数。
优势:
- 理论上能达到最好的性能
- 对任务的适应性最强
- 实现简单,技术门槛低
劣势:
- 计算成本极高(需要完整模型的梯度计算和存储)
- 内存需求大(需要存储所有参数的梯度)
- 容易过拟合(特别是在小数据集上)
- 部署成本高(需要存储完整的微调后模型)
3. 高效微调(Parameter-Efficient Fine-tuning)
3.1 LoRA微调
基本概念
LoRA基于一个重要假设:模型适应新任务时,权重矩阵的更新具有低秩特性。
数学原理:
原始计算:y = Wx
LoRA计算:y = Wx + ΔWx = Wx + BAx
其中:
- W:原始权重矩阵(frozen,不更新)
- ΔW = BA:权重更新矩阵
- B ∈ R^(d×r),A ∈ R^(r×k)
- r << min(d,k):秩大大小于原矩阵维度
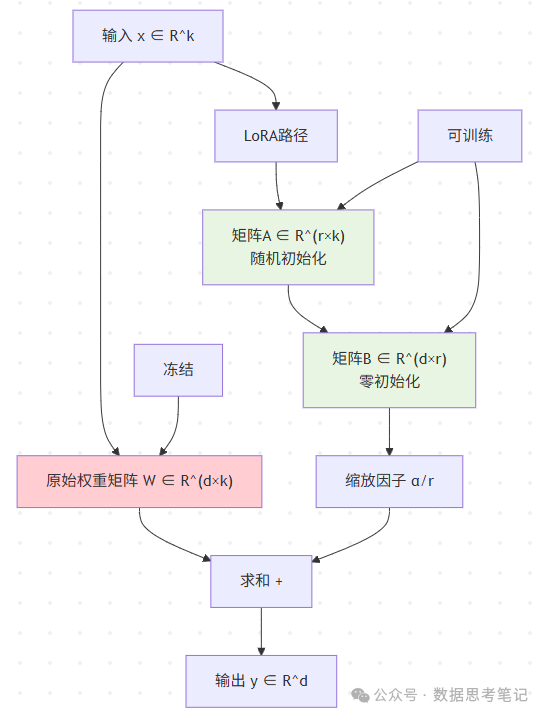
关键实现细节:
(1) 初始化策略
- 矩阵A:使用高斯随机初始化
- 矩阵B:使用零初始化,确保初始时ΔW = BA = 0
- 这样确保训练开始时模型行为与原模型一致
(2) 秩的选择(r值)
- r=1: 参数最少,但表达能力有限
- r=4-8: 平衡性能和效率的常用选择
- r=16-64: 更好性能,但参数量增加
- 经验法则:r ≈ 原矩阵最小维度的1%-10%
(3) 缩放因子α
- 控制LoRA部分的贡献大小
- 通常设置为α = r,使得初始学习率合理
- 可以作为超参数进行调优
LoRA的变体:
(1)AdaLoRA (Adaptive LoRA)
- 动态调整不同层的秩
- 重要的层分配更高的秩
- 通过奇异值分解进行重要性评估
(2)QLoRA (Quantized LoRA)
- 结合量化技术,进一步减少内存占用
- 基础模型使用4-bit量化
- LoRA部分保持16-bit精度
- 在保持性能的同时大幅减少显存需求
3.2 Adapter方法
在层间插入小型神经网络(“知识过滤器”)
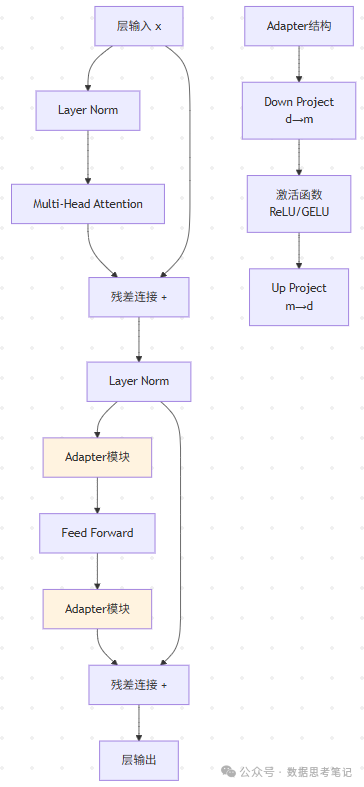
3.3 提示微调(Prompt Tuning)
在输入序列前添加可学习的提示词:
原始输入: [CLS] I love this movie [SEP]
Prompt Tuning: [P1] [P2] [P3] [CLS] I love this movie [SEP]
其中 [P1], [P2], [P3] 是可学习的embedding向量
3.4 各方法对比
| 方法 | 参数量 | 训练时间 | 推理速度 | 性能 | 内存占用 |
|---|---|---|---|---|---|
| 全参数微调 | 100% | 最长 | 正常 | 最好 | 最高 |
| LoRA | 0.1-1% | 中等 | 正常 | 很好 | 低 |
| Adapter | 2-4% | 中等 | 略慢 | 好 | 中等 |
| Prompt Tuning | 0.01-0.1% | 最短 | 最快 | 一般 | 最低 |
使用场景建议:
(1) LoRA
- 适合大多数场景的首选方案
- 在性能和效率间取得很好平衡
- 特别适合语言生成任务
(2) Adapter
- 适合需要在多个任务间快速切换的场景
- 每个任务只需要保存对应的Adapter参数
(3) Prompt Tuning
- 适合快速原型开发
- 在大模型上效果更好
- 适合少样本学习场景
(4) 全参数微调
- 有充足计算资源且追求最佳性能
- 数据集较大且质量很高
- 任务与预训练差异较大
五、应用场景案例
1. 医疗诊断助手
- 微调数据:10万份脱敏病历+医学文献
- 效果:准确解读“血清肌钙蛋白升高提示心肌损伤”
2. 金融合规审核
- 微调数据:监管文件+风险案例库
- 效果:识别“阴阳合同”“洗钱话术”准确率提升40%
3. 教育作文批改
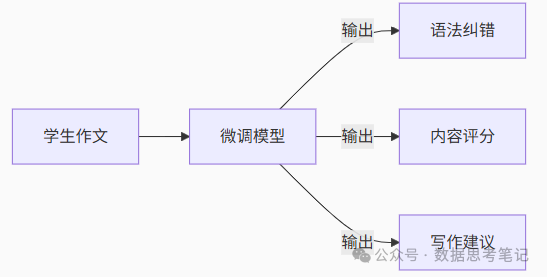
六、微调的优势与挑战
1. 主要优势
(1)成本效益高
- 训练时间从数月缩短到数小时或数天
- 数据需求从TB级别降低到GB级别
- 计算资源需求大幅减少
(2)效果显著
- 在特定任务上通常比通用模型表现更好
- 能够快速适应领域特定的语言风格和专业术语
(3)灵活性强
- 可以针对不同任务进行多次微调
- 支持个性化定制
2. 面临的挑战
(1)灾难性遗忘
- 模型可能会忘记预训练阶段学到的通用知识
- 需要平衡新任务学习和知识保留
(2)数据质量依赖
- 微调效果很大程度上取决于训练数据的质量
- 低质量数据可能导致模型性能下降
(3)过拟合风险
- 在小数据集上容易出现过拟合
- 需要合适的正则化技术
总结
微调技术是大模型时代的关键技术之一,它让AI应用变得更加易得和实用。通过在预训练模型基础上进行针对性训练,微调能够以较低的成本快速获得高质量的专用模型。随着技术的不断发展,微调将在AI普及化和产业化中发挥越来越重要的作用,让每个组织都能够拥有属于自己的专业AI助手。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~



















 2838
2838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









