



你有没有想过,为什么有些AI回答问题时逻辑清晰、知识渊博,而有些却答非所问、胡说八道?关键就在于它们"吃"了什么样的数据。
就像人类的成长需要优质教育一样,AI的训练也离不开高质量的数据。但在AI领域,一直存在一个尴尬的现状:那些表现最好的AI模型,比如GPT-4、Claude等,它们的训练数据都是商业机密,普通研究者和小公司根本接触不到。这就像最好的学校不对外开放,只有少数人能享受优质教育资源。
直到FineWeb的出现,这种局面才被彻底打破。2024年,Hugging Face发布了迄今为止最大的开源AI训练数据集——FineWeb。这不仅仅是一个数据集,更是一次技术民主化的革命。它首次将顶级AI训练数据的"秘方"完全公开,让任何人都能复制和改进。
那么,这个改变游戏规则的数据集到底是什么?它又是如何制作出来的?让我们一起揭开FineWeb的神秘面纱。

一、FineWeb是什么?
FineWeb:一个改变游戏规则的数据集
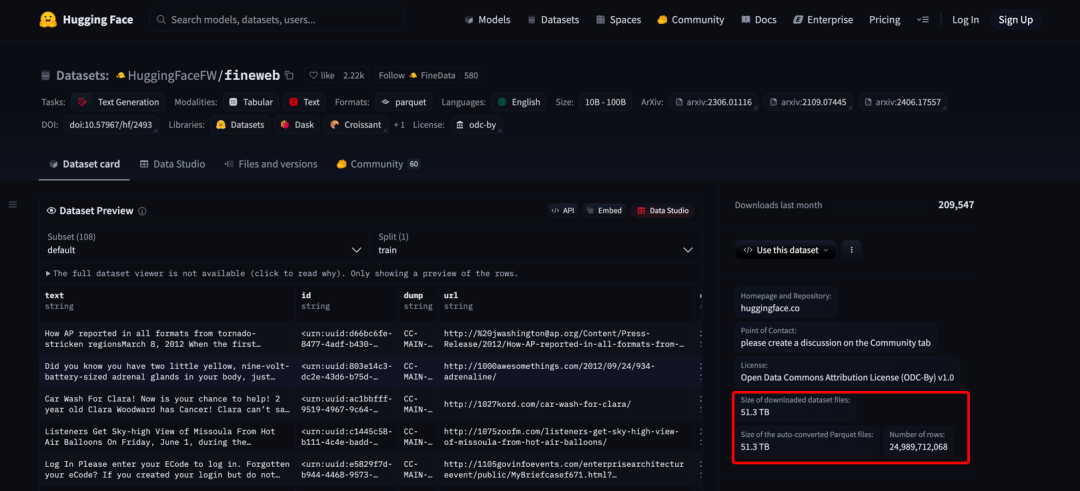
FineWeb是目前最大的开源AI训练数据集,包含超过15万亿个token的清洗和去重英文网络数据 HuggingFaceFW/fineweb · Datasets at Hugging Face。这个数字有多大?大概相当于:
- 1500万本书的内容
- 人类一辈子都读不完的文字量
- 足够训练顶级AI模型的数据规模

为什么FineWeb这么重要?
FineWeb解决了大模型行业数据集缺少的痛点问题
像Llama 3和Mixtral这样的知名AI模型,虽然开源了代码,,但训练数据却不公开The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale。这就像有人告诉你车的构造,但不告诉你用什么燃料。
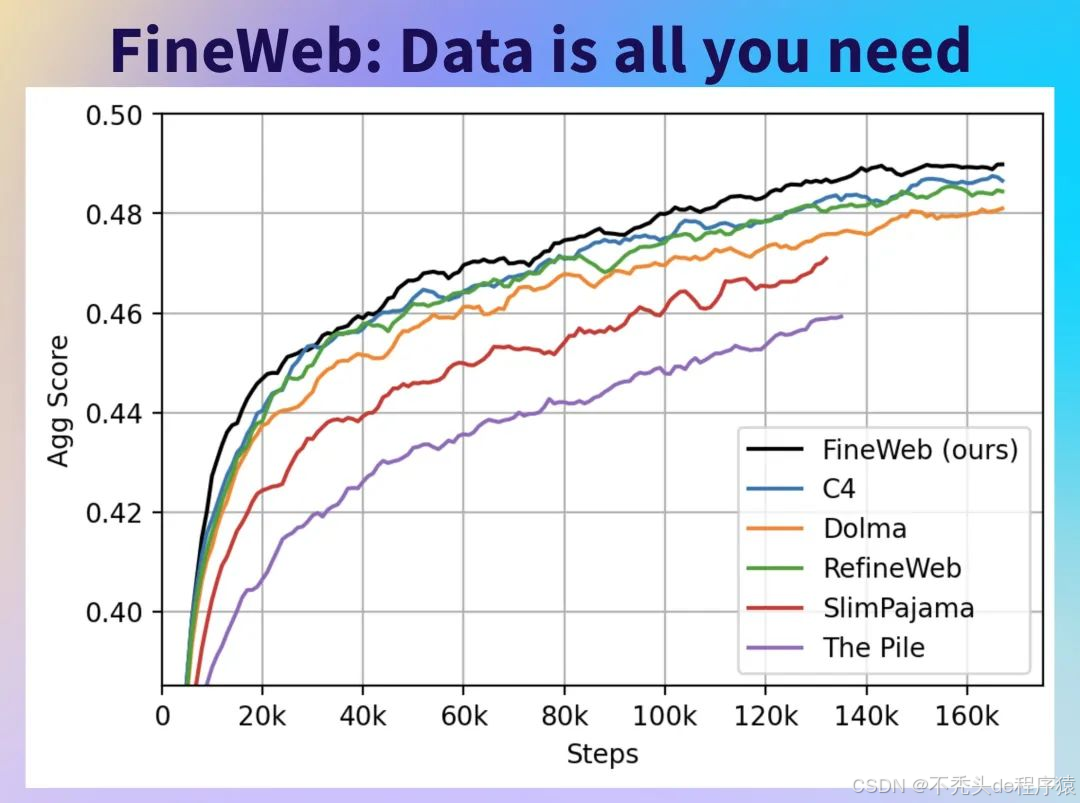
FineWeb数据集开源之后,人们发现,利用该数据集训练大模型,相较于使用其他常见的高质量数据集(如业内知名的C4、The Pile等)训练出的模型,表现更为出色。
FineWeb的突破有哪些?
(1)数据完全开源
15万亿token完全免费开放,全部免费开放且支持商业用途,其数据规模足以支撑顶级 AI 模型的训练。这也让小公司首次有机会使用以往只有巨头企业才能获取的大规模数据来训练 AI。
(2)处理方法全透明
每个处理步骤均有详细技术文档记录,同时开源了完整的处理代码库。团队不仅公开了失败经验,而且每个决策均以实验数据作为有力支撑。
(3)任何人都能复现和改进
提供完整工具包和详细操作教程,所有人站在同一起跑线,无需从零开始收集数据,只用注算法而非重复数据工作。
二、FineWeb制作全过程是什么?
从原始数据到精品数据集的蜕变
*制作FineWeb不是拍脑袋决定的,而是采用了严格的科学方法。每个处理步骤都必须通过训练AI模型来验证效果,使得整个制作过程是一个数据质量不断提升的过程,从网络上的原始内容,逐步打造成适合AI学习的高质量数据集。*
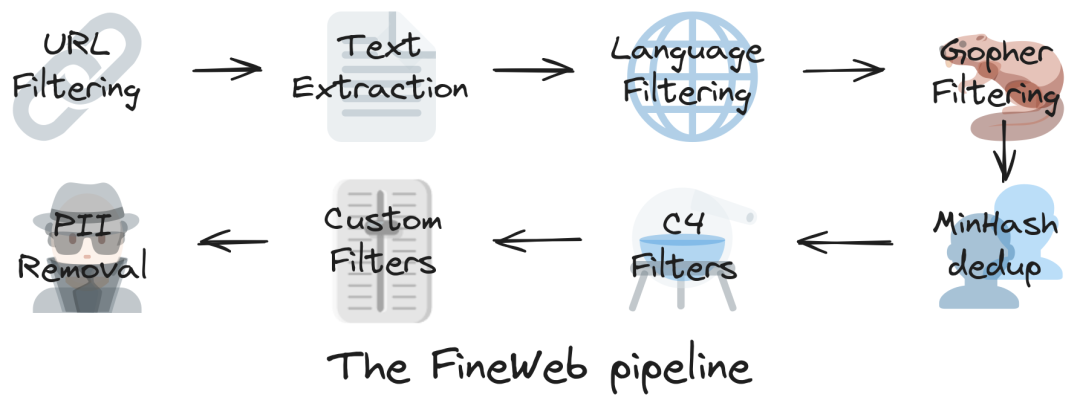
第一阶段:数据获取与初步清理
这个阶段的目标是从海量的网络数据中获取可用的文本内容。
(1)URL Filtering :首先进行URL筛选,从源头过滤掉明显不合适的网站,比如成人内容、垃圾站点等。
(2)Text Extraction:接着是文本提取环节,研究团队发现直接使用网上现成的文本文件效果不好,因为包含太多网页的无用信息(导航菜单、广告等)。他们改用专业工具从原始网页中提取纯文本,虽然成本更高,但AI训练效果明显更好。
(3)Language Filtering:然后通过语言识别,使用AI工具识别语言,只保留高质量的英文内容。
这三步下来,就从原始的网页数据中提取出了相对干净的英文文本。
第二阶段:革命性的去重创新
Gopher 过滤和MinHash去重:去重处理是整个FineWeb制作过程中最具创新性的部分,也是效果提升最明显的环节。
研究团队在这里遇到了一个重大挑战。按照传统思路,他们原本想把所有数据放在一起去重,认为去重越彻底越好。但实验结果令人震惊:对于较老的数据,全局去重会删掉90%的内容,但留下的10%质量反而不如被删掉的那90%!
这个发现完全颠覆了"去重越多越好"的传统观念。研究团队大胆创新,改为分时间段独立去重的策略。具体做法是:把不同时期爬取的网页数据分开处理,每个时间段内部去重,但不跨时间段去重。这个看似简单的改变,却带来了显著的性能提升
第三阶段:精细化质量提升
在有了相对高质量的去重数据后,研究团队开始进行更精细的质量优化。
(1)C4过滤器 (C4 Filters):他们首先借鉴了C4数据集的成功经验。C4是一个经典的数据集,在某些任务上表现很好。研究团队深入分析了C4的处理方法,包括删除没有标点符号结尾的行、过滤包含代码的内容、移除法律条款类文本等。但他们没有照搬,而是根据实际效果选择性采用,避免了过度过滤。
(2)自定义过滤器 (Custom Filters):更重要的是,研究团队还开发了自主创新的过滤方法。他们设计了一套系统化的过滤器开发流程:先收集50多个文档质量指标,然后对比高质量和低质量数据的差异,根据统计分析确定过滤阈值,最后通过实验验证效果。
(3)PII移除 (PII Removal):隐私保护的最后防线,对于数据集的公开发布,研究团队还应用了个人身份信息(PII)移除,通过匿名化邮箱和公共IP地址。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









